Mình vừa ngồi đọc lại một số tài liệu của @OpenLedger
Không phải để hiểu thêm, mà để làm rõ những vấn đề còn đang đọng lại trong đầu
Ban đầu mình nghĩ đây sẽ lại là một câu chuyện quen thuộc về dữ liệu AI
Các mô hình ngày càng lớn, nhu cầu dữ liệu ngày càng tăng, nguồn dữ liệu chất lượng cao ngày càng khan hiếm
Và một mạng lưới phi tập trung xuất hiện để kết nối những người tạo dữ liệu với những người cần dữ liệu
Nghe rất hợp lý
Thậm chí càng nghĩ càng thấy hợp lý
Nếu dữ liệu đang trở thành nhiên liệu của AI thì việc xuất hiện một lớp hạ tầng để ghi nhận nguồn gốc, theo dõi đóng góp và phân phối giá trị gần như là điều sớm muộn cũng phải xảy ra
Nhưng có một chi tiết khiến mình cứ quay lại suy nghĩ mãi
Không phải dữ liệu
Mà là thứ xuất hiện ngay sau dữ liệu
"Niềm tin"
Bởi vì dữ liệu chỉ có giá trị khi ai đó tin rằng nó đáng để sử dụng
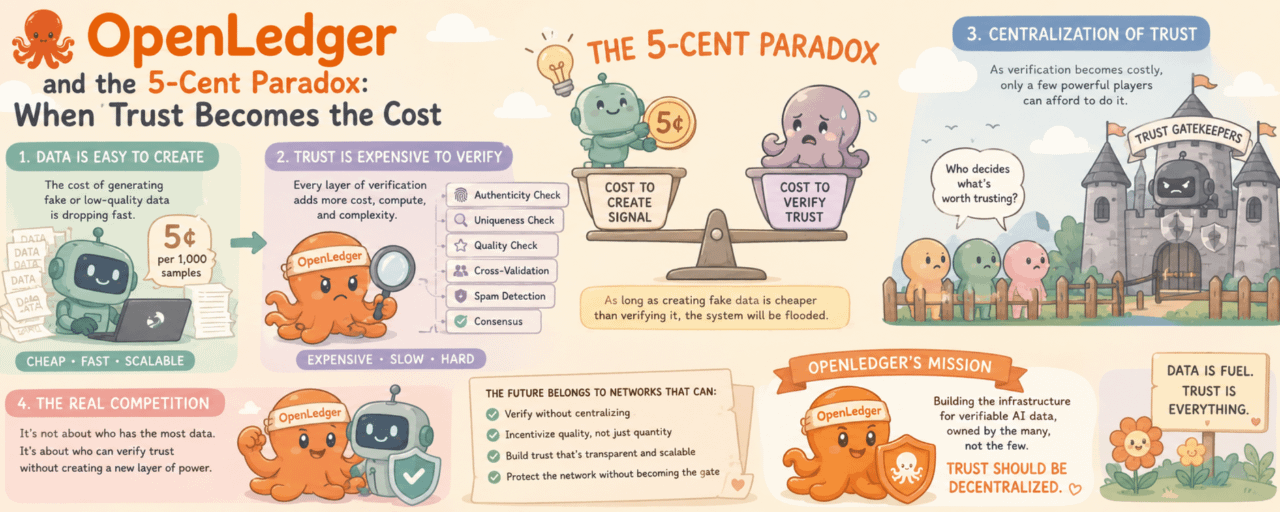
Và càng nghĩ về chuyện đó mình càng thấy @OpenLedger có thể đang đối mặt với một bài toán khó hơn nhiều so với việc thu thập dữ liệu
Làm sao để chứng minh dữ liệu đó đáng được tin?
Lúc đầu mình không nhìn vấn đề theo hướng này
Mình mặc định rằng nếu dữ liệu hữu ích thì thị trường sẽ tự định giá nó
Người đóng góp dữ liệu tốt sẽ được thưởng nhiều hơn, người đóng góp dữ liệu kém sẽ bị đào thải
Nghe giống như cách rất nhiều hệ thống thị trường hoạt động
Nhưng rồi mình nhận ra một điều
Ngay khoảnh khắc một điểm dữ liệu được gắn với phần thưởng kinh tế, bản chất của nó thay đổi
Nó không còn đơn thuần là dữ liệu nữa
Nó trở thành mục tiêu để tối ưu hóa
Điều này gần như chưa bao giờ thất bại trong crypto:
Nếu có incentive, sẽ có người tìm cách tối đa hóa incentive đó
Không phải vì họ xấu, mà vì hệ thống đang khuyến khích họ làm vậy
Nếu OpenLedger thành công và phần thưởng đủ hấp dẫn, điều đầu tiên xuất hiện có lẽ sẽ không phải những người đóng góp dữ liệu tốt nhất
Mà là những người hiểu cách kiếm phần thưởng hiệu quả nhất
Và đó là lúc mình bắt đầu thấy có một sự bất đối xứng khá kỳ lạ
Chi phí tạo ra tín hiệu đang giảm rất nhanh
Chi phí xác minh tín hiệu lại không giảm nhanh như vậy
Một nhóm nhỏ hoàn toàn có thể tạo ra hàng triệu mẫu dữ liệu trông có vẻ hợp lệ bằng những công cụ ngày càng rẻ
Trong khi đó phía còn lại của hệ thống phải trả lời những câu hỏi khó hơn nhiều
Dữ liệu này có thật không? Có mới không? Có hữu ích không? Có đang lặp lại thứ đã tồn tại hay không? Có được tạo ra chỉ để vượt qua bộ lọc hay không?
Mỗi câu hỏi mới lại kéo theo một lớp xác minh mới
Và càng thêm một lớp xác minh mới thì chi phí của hệ thống lại tăng thêm một chút
Đến đây mình chợt nhớ tới một mô hình đã xuất hiện rất nhiều lần trên Internet
Spam không biến mất vì người ta phát hiện được spam
Spam tồn tại vì chi phí gửi spam luôn thấp hơn chi phí ngăn spam
Click farm cũng vậy. SEO cũng vậy
Thậm chí rất nhiều nền tảng mạng xã hội cũng từng đi qua vòng lặp tương tự
Việc tạo ra tín hiệu giả thường rẻ hơn việc chứng minh tín hiệu đó không đáng tin
Nếu quy luật đó tiếp tục lặp lại trong các mạng lưới dữ liệu AI thì câu chuyện bắt đầu trở nên thú vị hơn
Bởi vì lúc đó OpenLedger sẽ không còn tối ưu cho dữ liệu
Họ sẽ tối ưu cho việc xác thực dữ liệu
Nghe có vẻ giống nhau. Nhưng thực ra không giống nhau
Càng nhiều dữ liệu đáng ngờ xuất hiện
Mạng lưới càng cần nhiều bộ lọc hơn, nhiều validator hơn, nhiều cơ chế kiểm tra chéo hơn, nhiều tài nguyên hơn
Thoạt nhìn đây là phản ứng hoàn toàn hợp lý
Nhưng mình lại bị mắc kẹt ở một câu hỏi khác
Ai sẽ là người đủ khả năng vận hành tất cả những thứ đó?
Nếu xác thực trở thành phần đắt đỏ nhất của hệ thống
Thì lợi thế sẽ thuộc về ai?
Có lẽ không phải những validator nhỏ, cũng không phải những người vận hành bằng vài chiếc máy cá nhân
Mà là những tổ chức có nhiều compute hơn, nhiều vốn hơn, nhiều dữ liệu hơn
Những người đủ khả năng hấp thụ chi phí xác thực đang ngày càng tăng
Và đây là lúc mình nhận ra thứ khiến bản thân lấn cấn từ đầu
OpenLedger được thiết kế để phi tập trung hóa quyền sở hữu dữ liệu
Nhưng nếu chi phí xác thực tiếp tục tăng theo thời gian
Mạng lưới có thể vô tình tập trung hóa một thứ khác
Quyền quyết định dữ liệu nào đáng được tin
Ban đầu điều này nghe không quá nghiêm trọng
Nhưng nghĩ kỹ thì đây mới là lớp quyền lực quan trọng hơn
Người sở hữu dữ liệu chưa chắc đã kiểm soát hệ thống
Người quyết định dữ liệu nào được công nhận mới là người định hình dòng chảy giá trị
Nếu một ngày nào đó phần lớn năng lực xác thực nằm trong tay một nhóm nhỏ
Thì vấn đề của @OpenLedger sẽ không còn là dữ liệu giả
Cũng không còn là spam
Mà là việc mạng lưới đang hình thành một tầng người gác cổng mới
Chỉ khác ở chỗ lần này người gác cổng không kiểm soát dữ liệu
Họ kiểm soát niềm tin
Và càng nghĩ về chuyện đó mình càng thấy có lẽ chúng ta đang nhìn sai nút thắt của toàn bộ ngành
Mọi người thường nói AI đang thiếu dữ liệu
Nhưng dữ liệu có thể không phải thứ khan hiếm nhất
Thứ khan hiếm nhất có thể là khả năng tạo ra niềm tin mà không cần tạo ra một tầng quyền lực mới để bảo vệ niềm tin đó
Nếu đúng là như vậy
Thì cuộc cạnh tranh thực sự trong vài năm tới có lẽ sẽ không phải giữa những mạng lưới sở hữu nhiều dữ liệu nhất🤷
Mà giữa những mạng lưới tìm ra cách xác minh dữ liệu mà không phải đánh đổi quá nhiều tính phi tập trung của chính mình🤙
#openledger $OPEN $LAB $HYPE