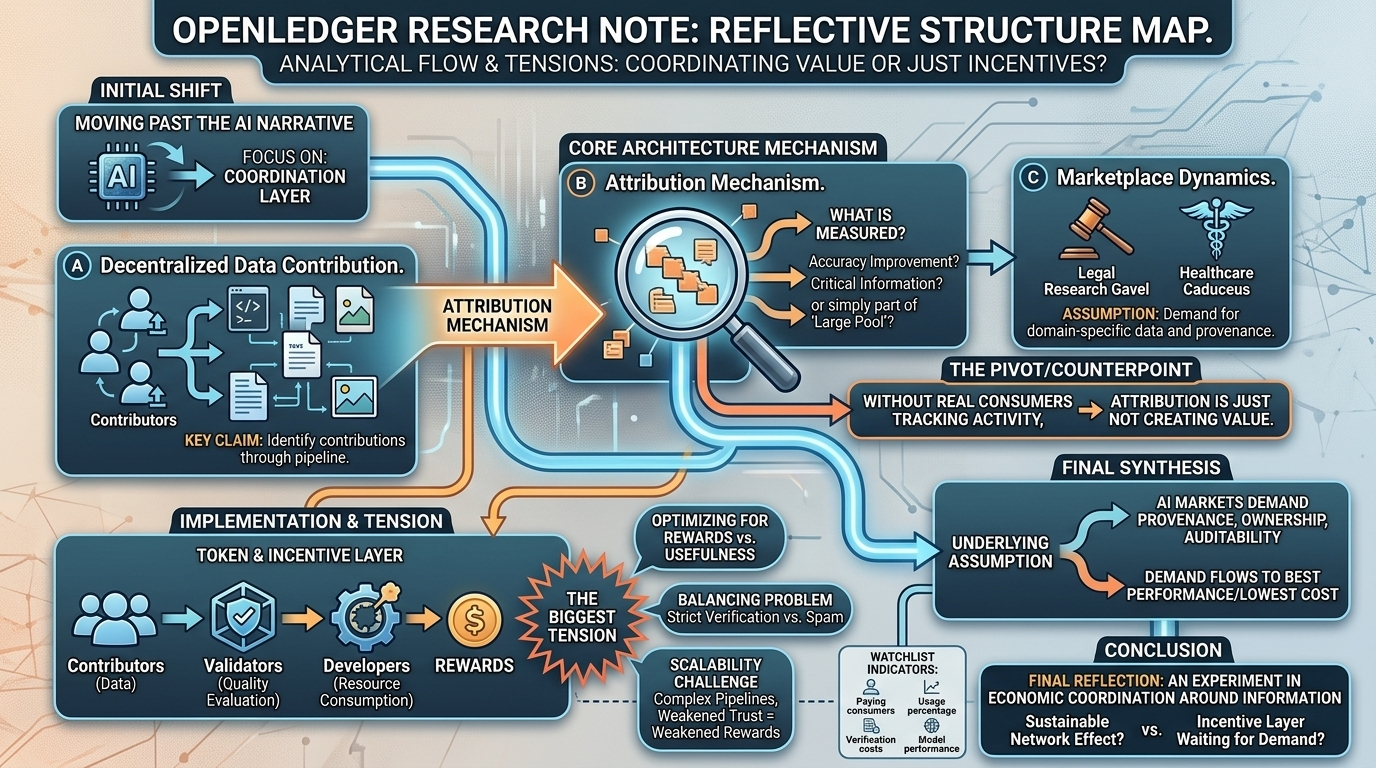
been going through openledger s architecture over the last week and honestly i keep finding myself looking past the ai narrative and focusing on the coordination layer underneath it
most people seem to view openledger as another ai crypto project which is understandable on the surface there is a token there is ai infrastructure there are contributor rewards but what caught my attention is that the architecture appears to be attempting something more specific: creating a system where data models and economic incentives can be linked together through attribution
that's a much harder problem than simply building another model marketplace
the decentralized data contribution system is probably the foundation the protocol assumes that useful datasets can come from a distributed group of contributors rather than a single centralized source that idea isn't new by itself but openledger seems to be making a stronger claim it wants those contributions to remain identifiable as they move through training pipelines and eventually generate value
which immediately leads to the attribution mechanism
and this is the part i keep thinking about
because attribution sounds simple until you ask what exactly is being measured
if a model is trained on thousands of documents datasets corrections annotations and updates how do you determine which contributor actually created value did they provide information that improved accuracy did they contribute data that became critical for a specific use case? or were they simply part of a large pool where individual impact becomes impossible to isolate
the protocol seems to rely heavily on the idea that contribution can be tracked and rewarded in a meaningful way technically that may be possible to some degree economically i'm less certain
the marketplace dynamics are also interesting. openledger appears to assume future demand for specialized data and specialized models rather than generic ai outputs. i can see the logic a legal research model for example may need continuously updated domain specific information a healthcare model might require verified medical datasets with clear provenance in those situations, knowing where data originated could actually matter
but the architecture seems dependent on that demand existing at meaningful scale
without real consumers of datasets and models attribution systems don't create value by themselves they simply track activity
the token layer is where the network coordination becomes more visible contributors provide data validators or verification systems evaluate quality developers consume resources rewards are distributed based on participation and measured contribution
on paper it creates alignment
in practice incentive systems often attract behavior that optimizes for rewards rather than usefulness
that's where i see the biggest tension
if emissions are generous contributors may focus on maximizing submissions rather than maximizing quality if verification becomes too strict participation may decline if verification becomes too loose spam and low value data begin accumulating every decentralized network eventually encounters some version of this balancing problem
there's also the broader question of scalability. attribution becomes increasingly difficult as datasets grow larger and model pipelines become more complex the protocol's long term success may depend less on attracting contributors and more on proving that attribution remains trustworthy under heavy network activity
because if attribution confidence weakens the reward mechanism weakens with it
and underneath all of this is one assumption that keeps showing up no matter how i look at the architecture: future ai markets will care enough about provenance ownership and transparency to pay for them
maybe that's true
maybe enterprises regulators and developers eventually demand auditable data infrastructure
or maybe most demand continues flowing toward whatever delivers the best performance at the lowest cost
i'm still not sure
watching
growth in paying model and data consumers versus contributors
percentage of rewards tied to actual network usage rather than token emissions
verification costs as network activity increases
evidence that attributed datasets improve model performance in measurable ways
the more i read the more openledger feels less like an ai project and more like an experiment in economic coordination around information
whether that becomes a sustainable network effect or simply an incentive layer waiting for demand is probably the question that matters most