Znam się na sztucznej inteligencji i rozmowach o kryptowalutach, więc potrafię rozpoznać, kiedy prezentacja to tylko elegancki garnitur na słabym pomyśle. Większość modeli nagród w tej przestrzeni nadal wydaje się leniwa. Dołącz, kliknij, publikuj, stakuj, farmuj, powtarzaj. To liczy ruch. Nie pyta, czy twoja praca przyniosła coś lepszego. To zły sposób na wycenę ludzkiego wkładu, a jeszcze gorszy, gdy w grę wchodzi dane AI.
@OpenLedger with $OPEN jest bardziej wart uważnej lektury, ponieważ stara się zająć tym starym bałaganem, kto powinien zarabiać, gdy wiele rąk kształtuje jeden model?
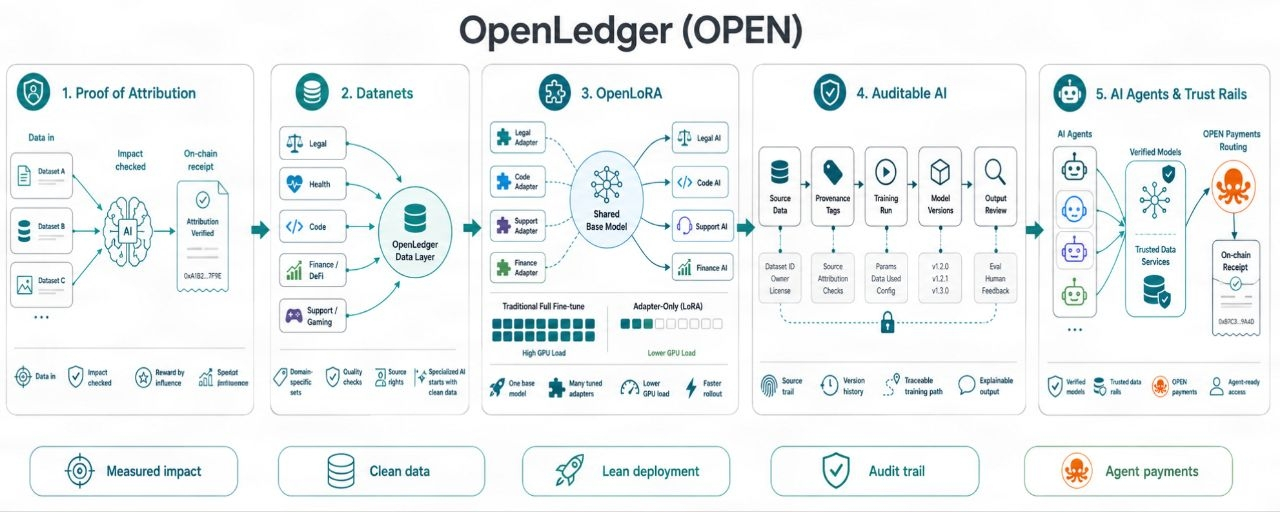
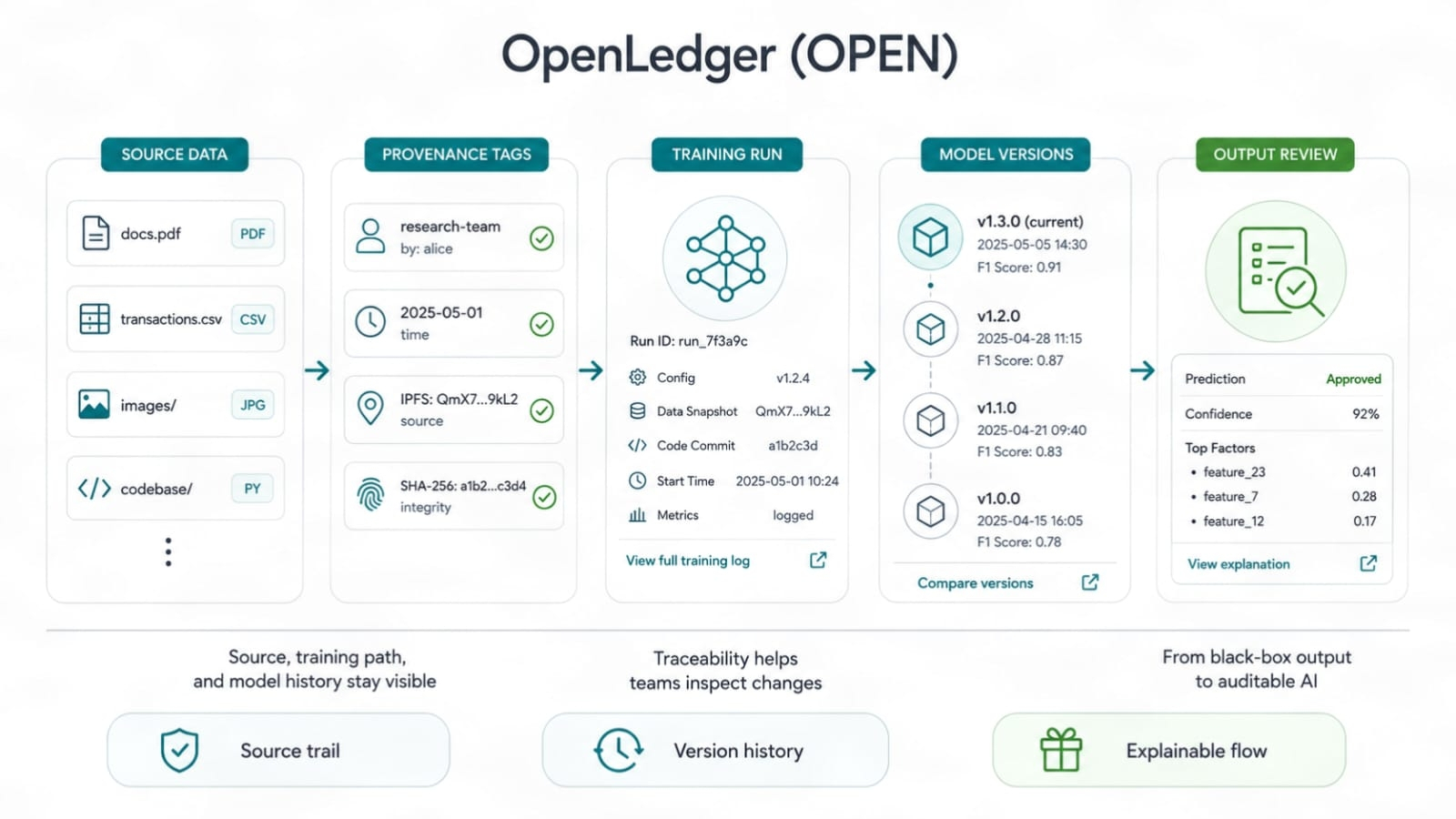
Dowód atrybucji jest przydatny, ponieważ przenosi fokus z "Brałem udział" na "moje dane zmieniły jakość wyjścia."
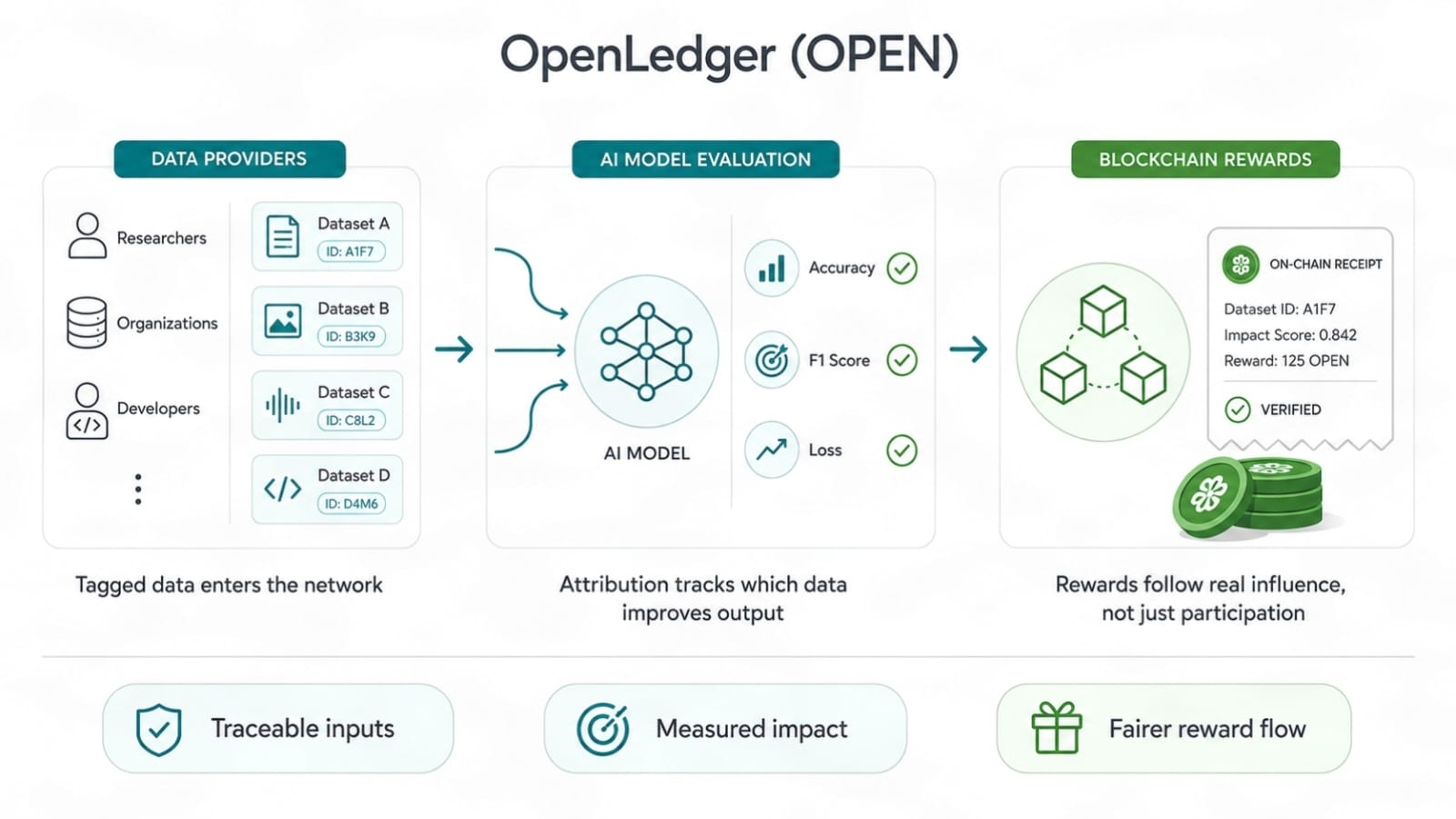
To brzmi mało. Ale tak nie jest. Rynki danych AI mają dużo zbędnego ciężaru. Ludzie mogą wrzucać pliki, skrobać niskiej jakości tekst, zmieniać nazwy i liczyć, że skala ukryje słabą wartość źródłową. Jeśli nagrody idą za surowym wkładem, spam wygrywa. Jeśli nagrody idą za realnym wzrostem, jakość ma swoją ścieżkę.
To jest trudne do zrobienia. Nie będę tego upiększać. Atrybucja w AI nie jest czystą zabawką matematyczną. Modele uczą się w chaotyczny sposób. Jeden zestaw danych może pomóc w jednym zadaniu i zaszkodzić innemu. Niektóre wkłady dodają umiejętności w przypadkach skrajnych. Niektóre tylko powtarzają to, co model już wie. Więc twierdzenie OpenLedger musi żyć lub umrzeć w zależności od tego, jak dobrze może śledzić wpływ danych, prawa, użycie modeli i przepływ nagród. Ładne dokumenty nie będą wystarczające. Żywy dowód będzie miał znaczenie.
Dane potrzebują ścieżki dowodowej. Nie fałszywego odznaki. Nie próżnościowego wyniku. Ścieżka pokazująca, skąd pochodził dany wkład, jak był używany i jaką rolę odgrywał. To jest to, czego chcą dostawcy danych, jeśli są poważni. Nie chcą stać w tłumie i liczyć na ochłapy. Chcą wiedzieć, czy ich dane miały wpływ.
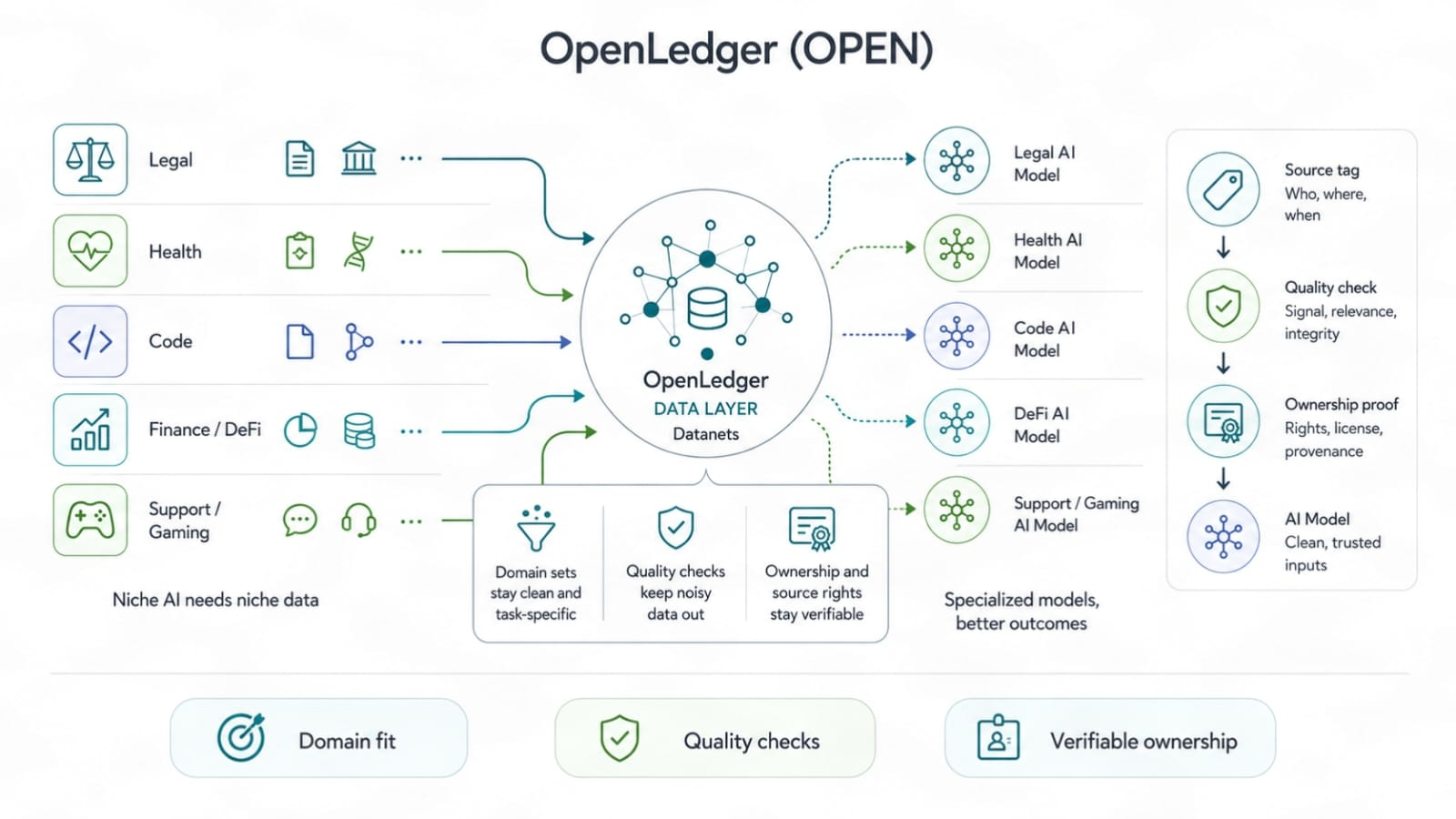
Datanety to miejsce, gdzie zaczyna się to bardziej realne. Szerokie dane AI mają ograniczenia. Możesz trenować ogólny model na ogromnych stertach tekstów, pewnie. Ale gdy potrzebujesz modelu do prawa, kodu, administracji zdrowiem, zasobów gier, ryzyka DeFi, statystyk sportowych czy operacji wsparcia, szerokie dane zaczynają wydawać się cienkie. Dane zadaniowe wygrywają. Czyste dane wygrywają. Posiadane dane wygrywają.
Datanet może działać jak pokój roboczy dla jednej dziedziny. Może przechowywać dane źródłowe, linki do praw, rejestry użycia i dopasowania zadań. To jest bardziej przydatne niż jeden wielki pojemnik, w którym wszystkie dane są mieszane, aż nikt nie wie, co skąd pochodzi. Jeśli OpenLedger może pomóc każdej dziedzinie utrzymać własną ścieżkę danych, to wąscy budowniczowie zyskują lepszą bazę do trenowania. Nie idealnie. Lepiej.
To również daje małym właścicielom danych uczciwą szansę. Zespół może nie mieć ogromnej skali, ale może mieć rzadkie dane o wysokiej wartości użycia. W starych rynkach rozmiar ma tendencję do przytłaczania umiejętności. W rynkach opartych na atrybucji, mały zestaw, który podnosi wyjście modelu, może mieć większe znaczenie niż ogromna sterta, która dodaje szum. To zdrowsza ramka. Nagradza prawdziwą przewagę, a nie głośną objętość.
OpenLoRA pasuje następnie do drugiego punktu bólu, kosztu wdrożenia modelu. Modele dostosowane brzmią świetnie, dopóki nie uderzy koszt GPU. Pełna praca modelu może szybko zjeść budżet. Metody w stylu LoRA pomagają, ponieważ dostosowują model bazowy za pomocą lżejszych zmian. Nie musisz targać ze sobą pełnego nowego modelu za każdym razem. Możesz uruchomić wiele dostosowanych ścieżek z mniejszym obciążeniem.
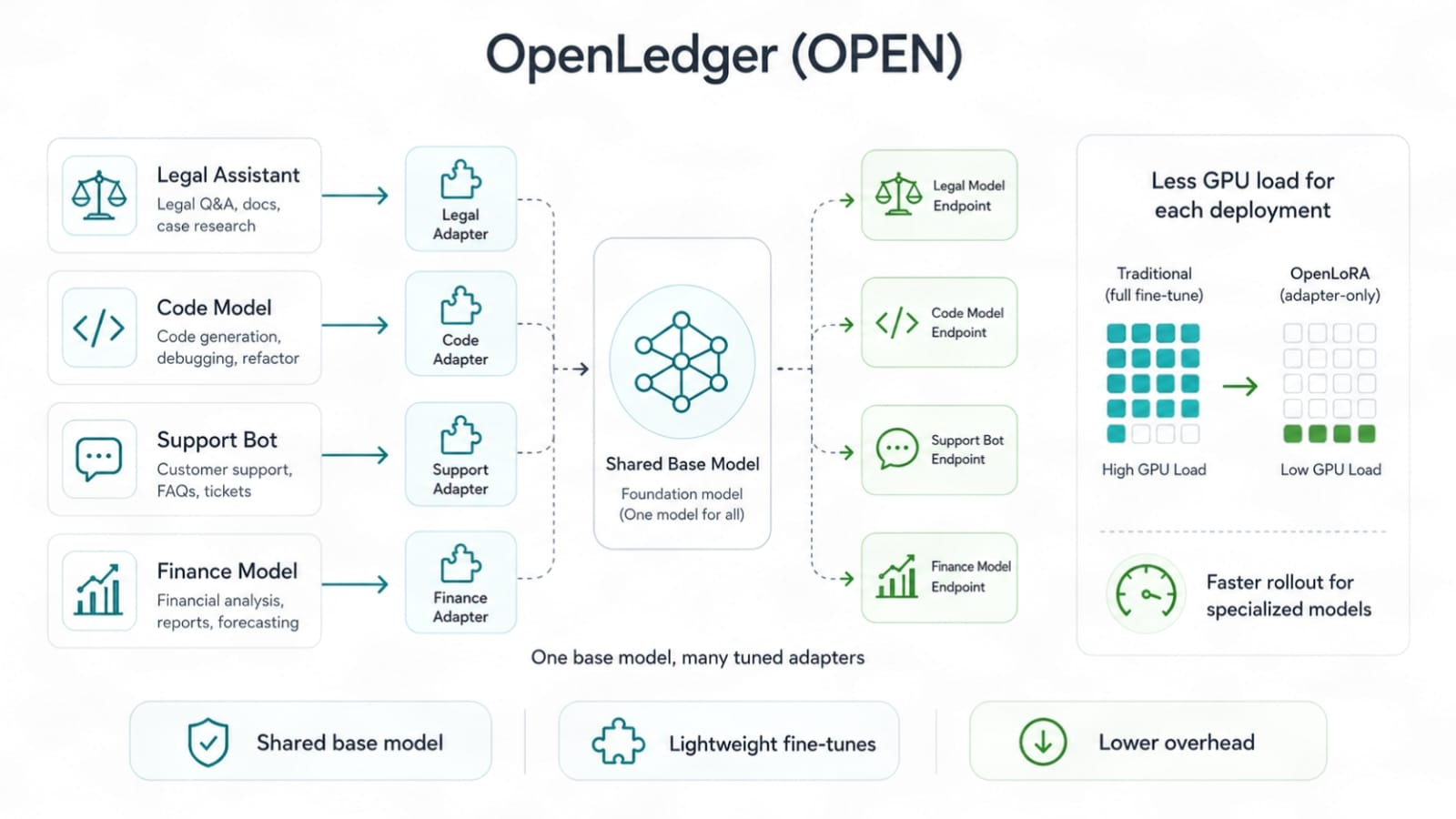
OpenLedger, OpenLoRA mogą oznaczać więcej modeli zadań serwowanych z mniejszym obciążeniem obliczeniowym. To ma znaczenie, ponieważ przyszłe AI nie będzie jednym gigantycznym modelem wykonującym wszystkie zadania dobrze. Prawdopodobnie będzie to wiele skoncentrowanych modeli, każdy dostosowany do jednej dziedziny. Jeden do wyszukiwania prawnego. Jeden do operacji finansowych. Jeden do wsparcia gier. Jeden do sprawdzeń danych łańcucha. Jeden do użycia narzędzi agenta. Małe, ostre, wystarczająco tanie do uruchomienia. To nie jest hype. To jest kierunek, w którym już zmierza wiele prac AI.
Ale cięcia kosztów nie mogą przychodzić kosztem zaufania. Tani model, którego nikt nie może prześledzić, to po prostu szybki problem. Zespoły potrzebują historii modelu. Jakie dane zostały użyte? Która wersja się zmieniła? Kto dodał co? Czy nowy zestaw danych pogorszył odpowiedzi? Czy budowniczy może cofnąć? Czy właściciel danych może udowodnić użycie? To nie są elementy opcjonalne. To sposób, w jaki prawdziwe zespoły utrzymują kontrolę, gdy AI wchodzi do codziennej operacji.
Czarna skrzynka AI wciąż ma słaby zapach wokół siebie. Nie dlatego, że AI jest zła, ale dlatego, że zaufanie łamie się, gdy nikt nie może audytować ścieżki. Ścieżka audytu OpenLedger ma na celu ułatwienie inspekcji historii budowy modelu. Śledzenie i dowód źródła brzmią sucho, aż coś się zepsuje. Wtedy stają się kluczowymi narzędziami. Każdy, kto wysłał prawdziwe systemy, wie o tym. Logi przewyższają wibracje.
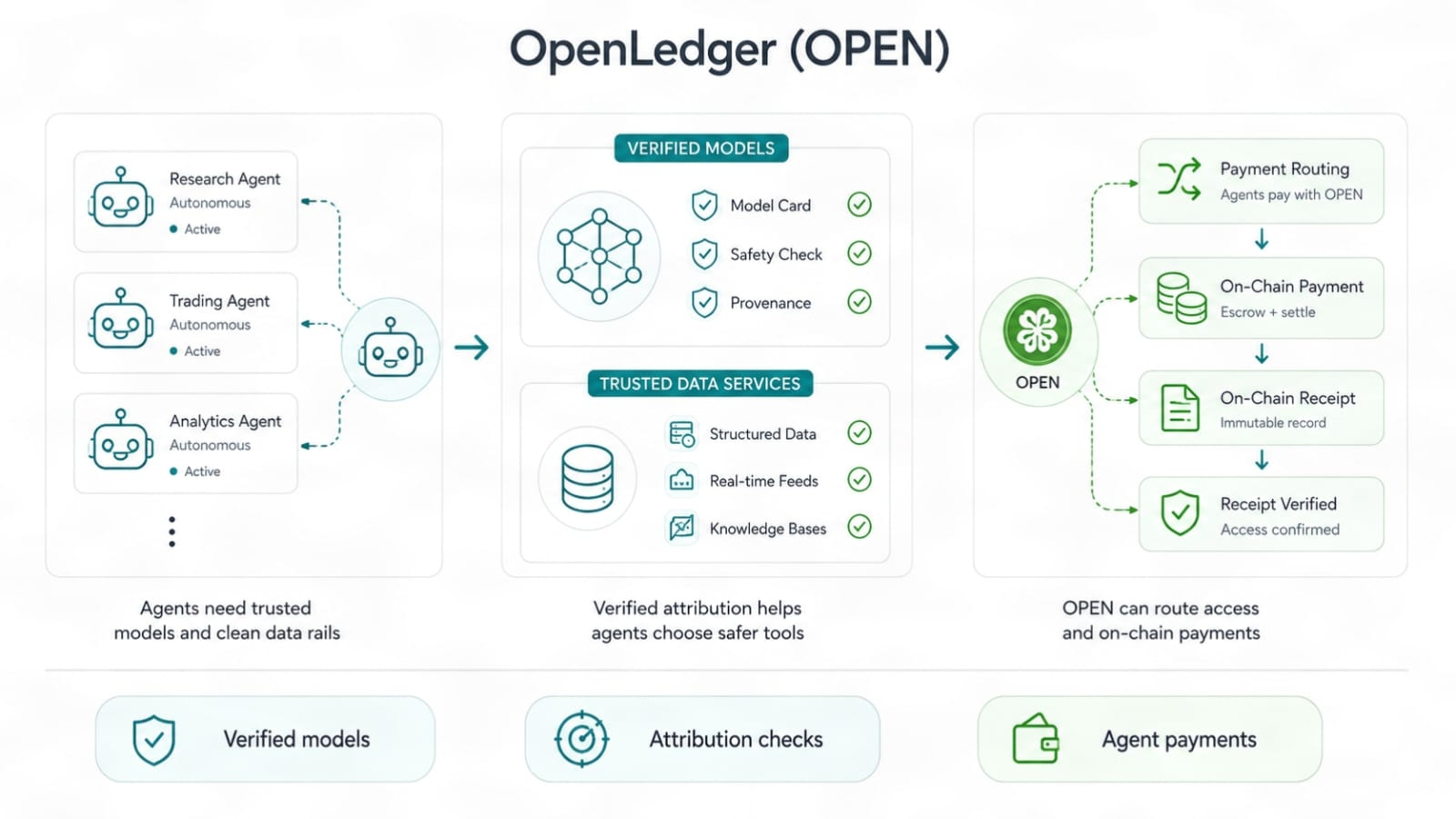
Agenci AI podnoszą stawki ponownie. Agenci nie tylko odpowiadają. Działają. Wywołują modele, używają danych, kierują zadaniami i mogą płacić za dostęp do systemów. Gdy agenci zaczynają podejmować więcej decyzji samodzielnie, istotne stają się tory zaufania. Model z zweryfikowaną historią danych jest bezpieczniejszy do włączenia w przepływ agenta niż taki z nieznanymi korzeniami. Warstwa płatności związana z OPEN mogłaby pomóc w kierowaniu opłat i nagród w tym ustawieniu, ale tylko jeśli użycie jest realne, a zasady pozostają jasne.
OpenLedger wskazuje na rzeczywistą potrzebę rynkową, uczciwą nagrodę za użyteczne dane AI. Dowód atrybucji nie dotyczy wręczania tokenów każdemu, kto się pojawi. Chodzi o powiązanie nagrody z wpływem. Datanety dają domenowym danym miejsce na udowodnienie wartości. OpenLoRA daje dostosowanym modelom prostą ścieżkę wdrożenia. Narzędzia audytowe wprowadzają historię źródłową do widoku. Płatności agenta sugerują przyszłą pracę AI, gdzie modele, dane i zadania poruszają się z mniejszym ludzkim oporem.
DYOR, zawsze. Czytaj dokumenty. Śledź użycie. Obserwuj, jak działają nagrody w otwartym widoku. Sprawdź, czy jakość danych pozostaje wysoka, gdy rosną zachęty. Sprawdź, czy OPEN ma wyraźną potrzebę w przepływie pracy, a nie tylko logo na górze. Czysty design to nie to samo co twarde dopasowanie do rynku.
Nie jestem tu, aby koronować cokolwiek. Krypto spaliło zbyt wielu mądrych ludzi, którzy zakochali się w ładnych słowach. Ale myślę, że OpenLedger zadaje jedno z właściwych pytań. W sztucznej inteligencji wartość nie będzie pochodzić tylko z posiadania danych. Będzie pochodzić z udowodnienia, które dane pomogły, kto je posiadał, dokąd poszły i dlaczego zasługują na udział. To jest miejsce, gdzie ta historia ma zęby.
