I didn’t take it seriously at first…
not because OpenLedger sounded empty. more because I’ve watched too many infrastructure ideas enter crypto with careful language and slowly become another incentive machine nobody fully understands after the first wave of belief fades.
that is usually how it goes.
a real problem appears. everyone agrees it matters. the system gets designed around fairness, coordination, transparency, ownership. then money arrives, usage arrives, shortcuts arrive, and the thing starts behaving less like an ideal and more like a market under stress.
Maybe that’s too harsh.
but after enough cycles, you start caring less about what infrastructure claims to fix and more about what it accidentally teaches people to do. what does it reward. what does it ignore. what does it make legible. what does it push into the shadows because the measurement layer cannot handle the mess.
AI-data is uncomfortable for exactly that reason.
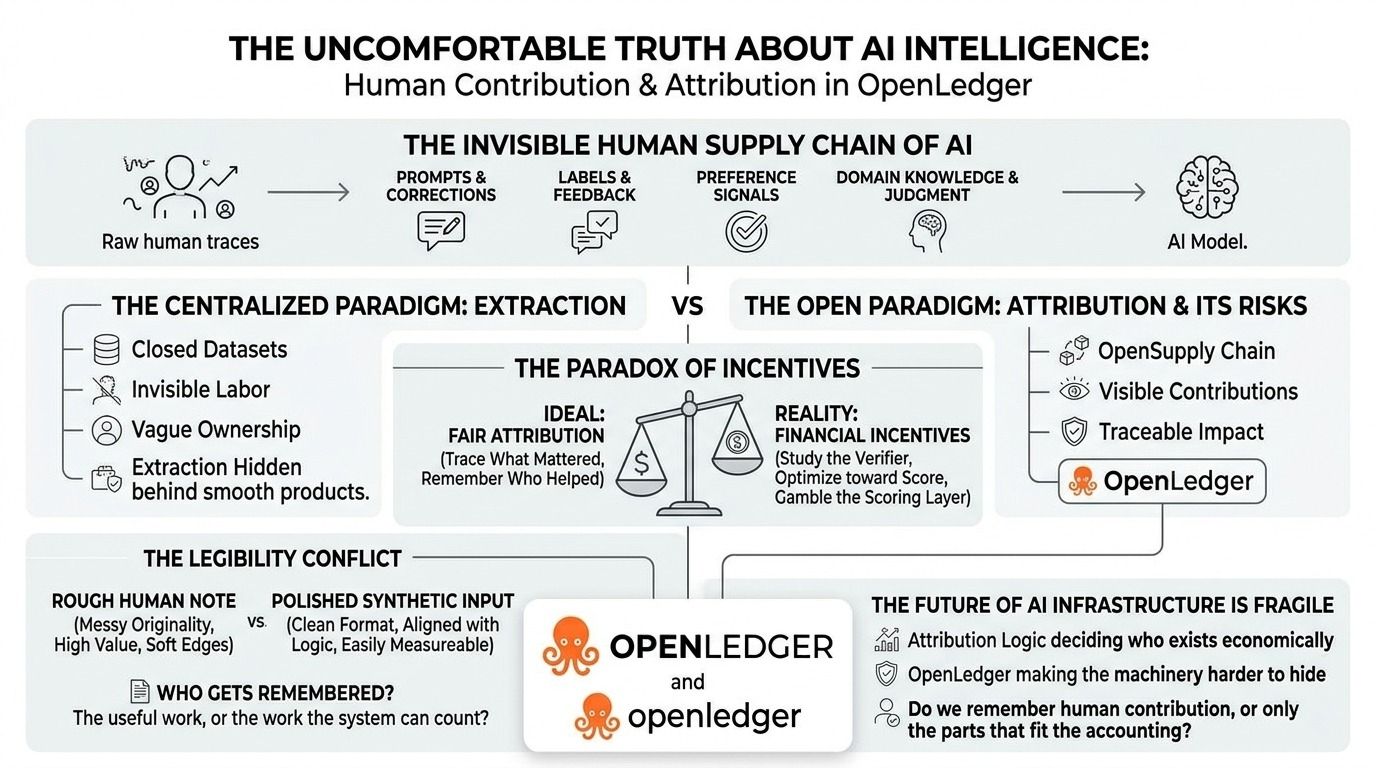
models are not built from some clean, floating intelligence. they are shaped by human traces everywhere. prompts, corrections, labels, feedback, examples, preference signals, domain knowledge, small pieces of judgment. most of it looks minor while it is happening. almost disposable.
then the model improves.
then everyone calls it capability.
and the human part disappears into “data.”
I keep coming back to attribution.
there is something necessary there. if intelligence has a supply chain, maybe that supply chain should not stay hidden inside closed systems. maybe people should not vanish the moment their input becomes valuable. maybe OpenLedger matters because it is trying to make contribution harder to erase.
not perfectly.
not cleanly.
but visibly enough to make the question harder to avoid.
and that is where my curiosity starts.
then the discomfort comes back.
because attribution changes once it becomes financial. before incentives, it sounds fair. remember who helped. trace what mattered. make contribution visible. after incentives, the whole texture changes. people study what gets counted. they learn the verifier. they produce toward the scoring layer. useful work and measurable work begin drifting apart, and the system has to keep insisting it knows the difference.
It works in theory. Most things do.
The problem isn’t really the technology… or not only the technology. the problem is that human contribution is soft around the edges. context is soft. originality is soft. usefulness can appear late, after a model has changed, after other inputs have surrounded it, after nobody remembers which small correction made the difference.
a rough human note might matter more than a polished dataset.
synthetic input might look cleaner than actual judgment.
copied work might fit the attribution logic better than the messy original.
so who gets remembered?
the person who helped, or the person the system could recognize?
That part keeps bothering me more than it should.
and then there is the older Web3 drift. open systems rarely recentralize in one dramatic moment. they narrow through convenience. fatigue. dashboards. indexes. quality scores. operators. dispute layers. all the invisible infrastructure nobody wants to audit forever.
AI infrastructure feels especially fragile there because the invisible layers are not secondary. attribution logic, contribution scoring, filtering, model coordination — these layers decide what counts. and once they decide what counts, they decide who exists economically.
still, I can’t dismiss OpenLedger.
centralized AI has not earned that comfort either. closed datasets, vague ownership, invisible labor, extraction hidden behind smooth products. that version already feels broken, just easier to tolerate because the machinery stays private.
maybe OpenLedger makes the machinery harder to hide.
maybe that matters.
or maybe once incentives get sharp enough, the system built to remember human contribution starts remembering only the parts that fit neatly into its accounting, while the rest slips back into the model, useful and unnamed.
[6/3, 12:22 AM] A M S: **AN AI AGENT WITHOUT A PAPER TRAIL IS JUST A VERY CONFIDENT STRANGER**
i was in one of those late-night crypto discussions recently where everyone was arguing about AI agents again.
not whether they work.
that part almost feels obvious now. agents can research, summarize, trade, route, schedule, respond, and pretend to understand context well enough that most people stop asking deeper questions.
the conversation was all about speed.
faster agents. better models. smoother automation. less friction.
but after a while, i kept thinking about something more basic.
it reminded me of watching a trader walk into a room, place a perfect trade, and refuse to explain where the idea came from. no source, no notes, no track record, no risk limits. just confidence.
and crypto people, of all people, should know better than to trust confidence without verification.
the real question isn’t whether AI is intelligent. it’s whether AI is accountable.
where did the intelligence come from?
who contributed the data?
who cleaned it, labeled it, verified it, improved it?
who gave the agent permission to act?
who gets compensated when that intelligence becomes valuable?
without attribution, intelligence becomes anonymous labor.
this is the lens where OpenLedger starts to feel worth examining. not because it is perfect. i don’t think any AI crypto project gets to wear that label right now. most of this space is still experimental, incentive-heavy, and very easy to distort with token rewards.
but OpenLedger seems to be looking at the missing ledger behind intelligence.
Proof of Attribution, data ownership, contributor incentives, datanets, specialized AI models, verifiable intelligence, AI value distribution — these ideas are not as flashy as an agent demo. they do not make people instantly excited in the same way a trading bot or autonomous assistant does.
but they may matter more.
because an AI model without provenance is a black box with a confident tone.
OpenAI and traditional AI platforms are strong at scale, polish, distribution, and model performance. they made AI usable for normal people. that is real execution. but the supply chain remains mostly closed. users see the output, not the ownership trail. contributors rarely know how their data shaped the system or whether they deserve anything from the value created.
Fetch.ai focuses more on autonomous agents and machine-to-machine coordination. that layer is important if agents are going to operate across markets, services, and devices. but agent autonomy creates another problem: permissions. what can the agent actually do? what shaped its decision? who audits it when it executes incorrectly?
Virtuals Protocol is interesting from the agent economy angle. it understands that agents can become social, financial, and community-owned assets. but making the agent visible is not the same as making its intelligence traceable. the character may have a token, but where did its knowledge come from?
Bittensor probably sits closer to the deeper infrastructure debate. it creates markets around machine intelligence and rewards useful outputs. but OpenLedger feels more focused on the layer underneath: the data networks, attribution paths, ownership logic, and contributor rewards that exist before intelligence becomes a final answer.
that distinction matters.
the industry keeps optimizing intelligence while neglecting responsibility.
OpenLedger seems less interested in making AI louder and more interested in making AI traceable.
still, i stay skeptical.
attribution at scale is hard. data quality can collapse if incentives are poorly designed. contributor rewards can become farming games. datanets need real demand, not just emissions. specialized AI models need actual users. governance can drift. and “transparent AI economy” is just a phrase unless the transparency changes who gets paid.
so no, i’m not saying OpenLedger wins.
i’m saying the question it points at feels bigger than one project.
maybe the next major AI infrastructure layer is not the smartest model, fastest chain, or most autonomous agent.
maybe it is the system that finally answers:
where did this intelligence come from, and who should be rewarded for creating it?