
Szczerze mówiąc, noszę w sobie cichą frustrację od 2022 roku związaną z moim wkładem w przestrzenie online.
Nie złość.
Po prostu niskiego poziomu świadomość, która nigdy całkowicie nie znika.
Napisałem szczegółowe analizy rynku na publicznych forach. Podzieliłem się badaniami, które zdobyły setki udostępnień. Spędziłem realne godziny na tworzeniu wątków, na których inni ludzie budują, remiksują, cytują w swojej pracy. Niektóre z tych postów są nadal cytowane w dzisiejszych rozmowach, w których nawet nie biorę udziału.
Zarobiłem dokładnie raz na każdym z nich. Zazwyczaj nic w ogóle.
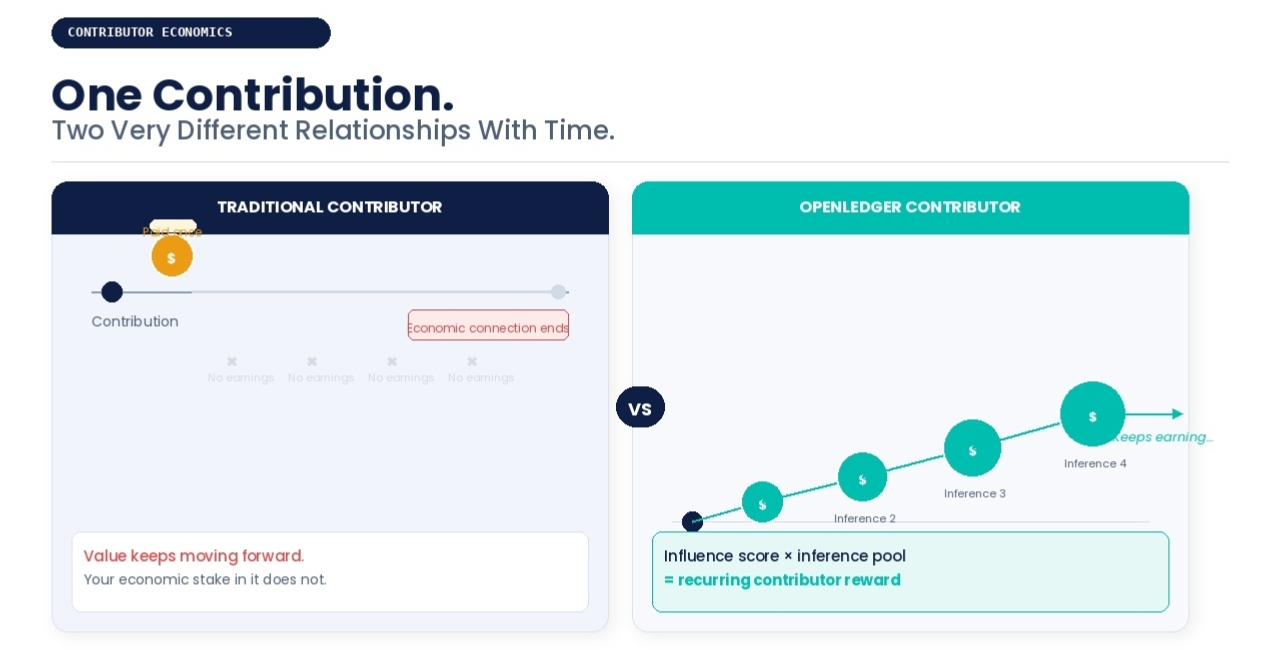
Wartość wciąż się przesuwała do przodu. Moje połączenie ekonomiczne z tym zatrzymało się w momencie publikacji.
To konkretne doświadczenie sprawia, że czytam model atrybucji OpenLedger w inny sposób niż większość rzeczy w tej przestrzeni w tej chwili.
Ponieważ to, co tak naprawdę opisuje, to nie tylko lepsza wersja jednorazowych płatności dla współpracowników. Opisuje to strukturalnie inną relację między wkładem a wynikiem ekonomicznym w czasie.
Oto część, która przyciąga moją uwagę.
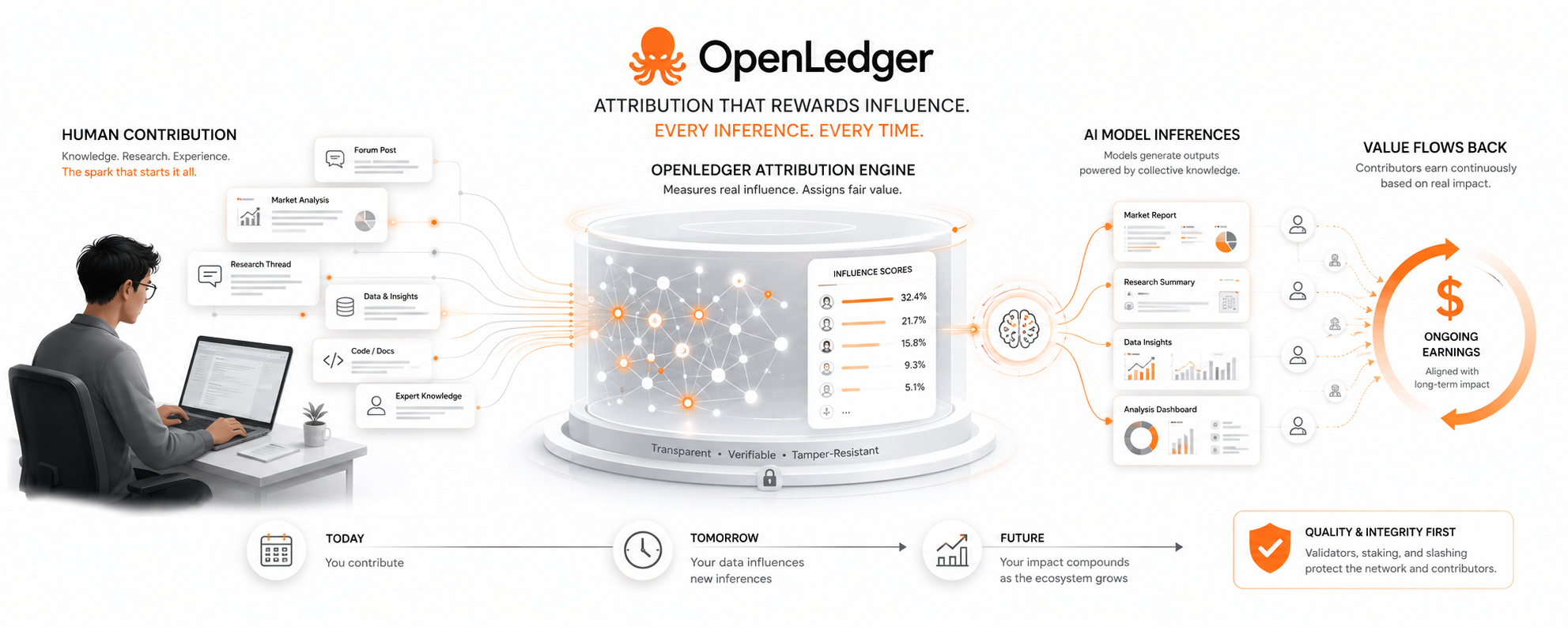
Kiedy specjalizowany model na OpenLedger obsługuje zapytanie, system oblicza, jak bardzo każdy indywidualny wkład danych naprawdę ukształtował ten konkretny wynik. Nie równo wśród wszystkich współpracowników. Każdy punkt danych nosi wskaźnik wpływu oparty na jego mierzonym wpływie na wynik. Współpracownik, którego dane osiągają wyższy wynik w tym konkretnym wyniku, zarabia proporcjonalnie większy kawałek puli opłat dla współpracowników z tego wniosku.
Każdy wniosek. Nie tylko za pierwszym razem, gdy model działa.
Więc przesłanie danych nie niesie ze sobą stałej wartości życiowej zablokowanej w momencie wkładu. Jego wartość ekonomiczna wciąż się przelicza z każdym wywołaniem modelu, które wpływa. Starannie skonstruowany wkład do aktywnie używanego modelu wciąż generuje dochód tak, jak dobrze cytowany dokument referencyjny wciąż wciąga się w nowe badania. Nie dlatego, że ktoś jest hojnym. Ponieważ system pomiarowy łączy zarobki bezpośrednio z ciągłym mierzonym wpływem.
Ta strukturalna luka ma większe znaczenie, niż wydaje się na pierwszy rzut oka.
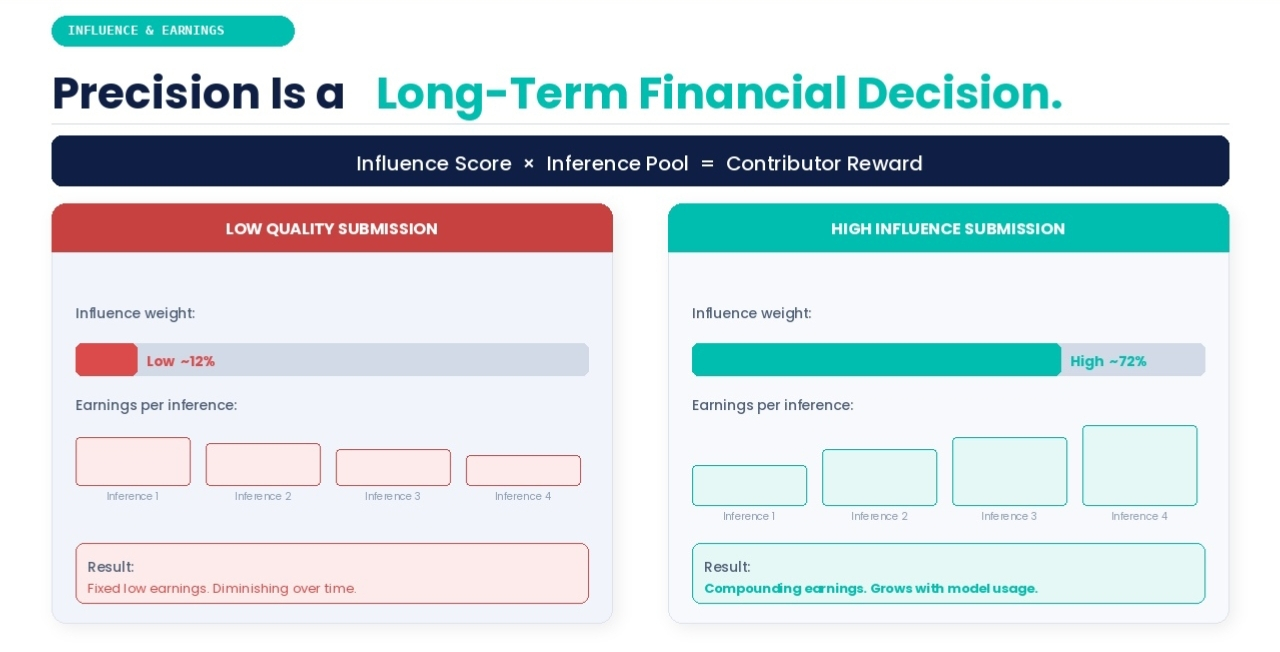
W standardowej giełdzie danych, jakość przekraczająca podstawowy akceptowalny próg nie zmienia wyniku. Szybkie przesłanie o minimalnej jakości i wolne przesłanie z głęboką wiedzą dziedzinową dają ten sam wynik, gdy płatność zostanie zrealizowana. Struktura zachęt nie rozróżnia między nimi po zamknięciu transakcji.
W systemie, w którym ciągły wpływ determinuje bieżące zyski, precyzja staje się długoterminową decyzją finansową, a nie profesjonalną uprzejmością. Współpracownik, który głęboko rozumie swoją dziedzinę i dostarcza dane, które ciągle osiągają wysokie wyniki w przyszłych wnioskach, nie jest tylko skrupulatny. On kumuluje pozycję w przyszłym wyniku modelu. $US
To zmienia, kogo sieć racjonalnie przyciąga w czasie.
Ale chcę szczerze zasiąść z tą niewygodną stroną.
Ciągła atrybucja jest znacznie trudniejszym problemem technicznym niż początkowa atrybucja.
Udowodnienie, że punkt danych wprowadzony w momencie przesłania jest stosunkowo czysty. Istnieje znacznik czasu. Istnieje zapis. Dane albo ukształtowały wczesne szkolenie, albo nie.
Udowodnienie, że ten sam wkład nadal niesie prawdziwy wpływ miesiące później, w ramach rosnącej puli współpracowników, gdy model otrzymuje dalsze aktualizacje i dostrajanie, to całkowicie inne wyzwanie. Indywidualne wskaźniki wpływu naturalnie się kompresują w miarę wzrostu puli współpracowników. To, co ma silną wagę w wczesnej fazie szkolenia, staje w obliczu rosnącej konkurencji ze strony nowszych, bardziej aktualnych przesłań w czasie. Współpracownik, który buduje silną pozycję we wczesnych stadiach modelu, nie utrzymuje automatycznie tej pozycji w nieskończoność. Matematyka się rozcieńcza, gdy całkowita pula się rozszerza.
A presja związana z grą kumuluje się proporcjonalnie do tego, jak finansowo istotne stają się źródła dochodu.
Kiedy ciągły dochód zależy od algorytmicznych wyników, optymalizacja pod kątem wyniku, a nie prawdziwej poprawy modelu, staje się racjonalna dla zaawansowanych graczy.

Luka między tym, co metryka mierzy, a tym, co miała nagradzać, rozszerza się dokładnie w tych warunkach, w których finansowy bodziec do jej wykorzystywania rośnie najsilniej.
Mechanika walidatora OpenLedger i kary za stakowanie istnieją specjalnie, aby przeciwdziałać temu. Koszty ekonomiczne wiążą się z niskiej jakości przesłaniami.
Ale czy te mechanizmy oporu utrzymają swoją integralność, gdy wartość sieci rośnie, a nagroda za wykorzystywanie rośnie równolegle z nią, to naprawdę otwarte pytanie.
CENY OPEN decydują, czy to pytanie znajdzie trwałą odpowiedź.
Nie chodzi tylko o to, czy infrastruktura do pomiaru wkładu zostanie zbudowana. Czy pozostanie wystarczająco dokładna pod realną presją finansową, aby uzasadnić długoterminowe decyzje jakościowe, które współpracownicy podejmują, opierając się na zaufaniu.
To znacznie trudniej wycenić niż samo przyjęcie infrastruktury.
I oto, co wciąż krąży w moim myśleniu po tym wszystkim. $LAB
Gdyby wiedza przekazywana systemom AI miała ciągłą relację ekonomiczną zamiast zamkniętej jednorazowej transakcji... czy ludzie obecnie oddający tę wiedzę za darmo zaczęliby podejmować inne decyzje dotyczące tego, gdzie i jak precyzyjnie się przyczyniają?
A jeśli tak się stanie... jak wygląda jakość rozwoju AI po tej zmianie zachowania?