
AI 初创企业选型分析:云端与本地部署 GPU 的成本及 ROI 对比(本文为$IO 官方提供内容,进行归纳学习研究)
以下是关于云端与本地部署(On-Premises)GPU 的详细成本拆解。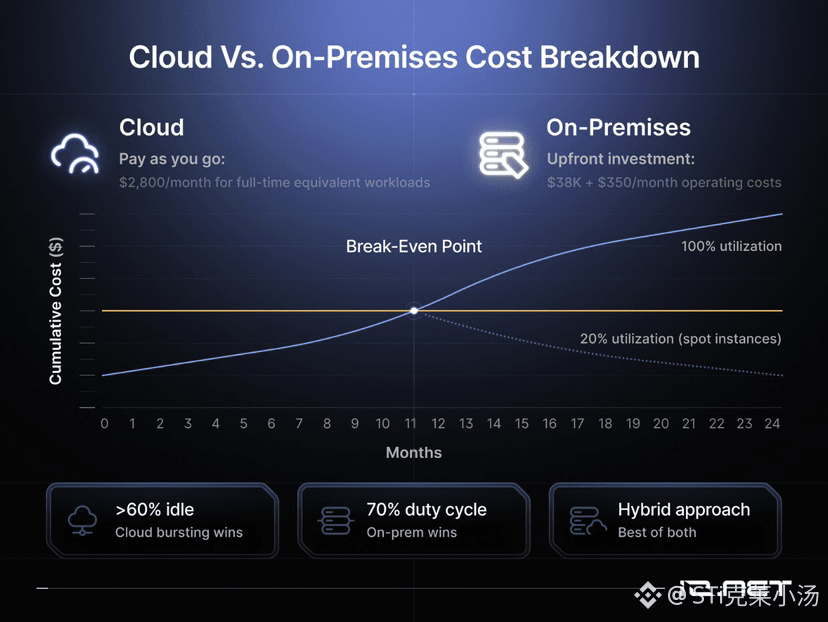
1. 成本数据对比
• 本地部署(On-Prem): 一套 64 核 GPU 集群的前期投入约为 3.8 万美元,此外每年需承担约 4,200 美元的电力成本。
• 云端租赁(Cloud): 同等配置的云端资源成本约为 2,800 美元/月。
2. 盈亏平衡与使用场景分析
本地部署的盈亏平衡点为 14 个月,但这仅在设备保持 24/7 全天候运行 的前提下成立。如果工作负载的运行时间仅占 20%,采用 云端竞价实例(Spot Instances) 具有更优的资本支出(Capex)效益。
3. 资源编排与灵活性
资源编排(Orchestration)是实现架构灵活性的核心。参照金融科技公司Fintech的常见架构:利用 Slurm-on-Kubernetes 等工具将敏感模型保留在本地运行,而在需要大规模算力(如夜间测试)时,突发扩展至 10,000+ 个云端核心。
4. 采购决策阈值
建议依据 核心工时(Core-hours) 进行决策:
• 购买硬件: 任务负载超过 1,200 核心工时/月。
• 租赁云端: 任务负载低于该数值。
5. 利用率监控与资源调整
应记录实际的 GPU 利用率数据,而非凭猜测行事:
• 若空闲时间 > 60%:表明存在硬件资源浪费,应转向云处理(Cloud Bursting)模式。
• 若负载率(Duty Cycle)持续 > 70%:建议购买硬件或租赁裸金属服务器(Bare Metal)。
6. 大规模并行处理策略

针对大规模工作负载,建议采用混合策略:将基础算力保留在本地,利用去中心化云资源应对峰值需求。应持续监控使用数据,并据此动态调整资源规模。


