@Walrus 🦭/acc is designed around the idea that decentralized storage must evolve in clearly defined phases rather than reacting chaotically to constant change. The timeline shown in the diagram captures how Walrus organizes its entire system around epochs, giving structure to staking, voting, shard assignment, and data migration. Instead of letting nodes freely enter and exit at arbitrary moments, Walrus enforces predictable boundaries where changes are planned, verified, and safely executed. This temporal structure is critical because Walrus does not manage small state like a blockchain; it manages real storage that is expensive to move and costly to rebuild.
Each epoch in Walrus represents a stable operating window where the set of storage nodes, their stake, and their responsibilities are fixed. During Epoch E, nodes actively store data, serve reads, and participate in the protocol with a known configuration. At the same time, staking and voting for a future epoch are already underway. This overlap is intentional. Walrus separates decision-making from execution so that when an epoch ends, the system already knows what the next configuration will be. There is no last-minute scrambling or uncertainty about which nodes will be responsible for storage in the future.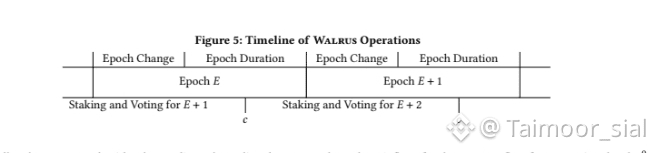
The cutoff point marked in the timeline is one of the most important safety mechanisms in Walrus. Before this cutoff, wallets can stake or unstake and participate in voting for future epochs. After the cutoff, changes no longer affect shard allocation for the upcoming epoch. This prevents adversarial behavior where a node could withdraw stake at the last moment after influencing shard assignments. By freezing stake influence at a known point, Walrus ensures that shard allocation is based on committed economic weight, not opportunistic timing.
Once an epoch concludes, #walrus enters the reconfiguration phase. This is where the real challenge begins. Unlike blockchains, where state migration is relatively lightweight, Walrus must move actual data between nodes. Storage shards may need to be transferred from outgoing nodes to incoming ones. The timeline emphasizes that this process happens after the epoch ends, not during active operation. This separation prevents writes from racing against shard transfers in a way that could stall progress indefinitely.
Walrus supports both cooperative and recovery-based migration paths. In the cooperative pathway, outgoing and incoming nodes coordinate to transfer shards efficiently. However, the protocol does not assume cooperation or availability. If some outgoing nodes are offline or fail during migration, incoming nodes can recover the necessary slivers from the remaining committee using Walrus’s two-dimensional encoding and RedStuff recovery mechanisms. This ensures that reconfiguration always completes, even in faulty or adversarial conditions.
The timeline also highlights how Walrus handles unstaking safely. When a node requests to unstake, its departure does not immediately affect shard allocation or system safety. The departing stake is excluded from future assignments only after the cutoff, and the node remains responsible for its duties until the epoch ends. This avoids scenarios where nodes escape responsibility by withdrawing stake while still holding critical data. Even after unstaking, incentives are aligned so that nodes return slashed or near-zero objects, allowing Walrus to reclaim resources cleanly.
By structuring the protocol around epochs, cutoffs, and delayed effects, Walrus transforms what would otherwise be a fragile, constantly shifting system into a predictable and verifiable process. Every change happens with notice, every migration has time to complete, and every decision is backed by stake that cannot vanish at the last second. The timeline is not just an operational detail; it is the backbone that allows Walrus to scale storage, tolerate churn, and remain secure while managing real data at decentralized scale. $WAL

