Małe zakłócenie wystarczy, aby ujawnić słabe punkty w każdym systemie o szybkim finalizowaniu. Wszystko może wydawać się normalne na pierwszy rzut oka—działalność trwa, wiadomości płyną, a łańcuch nie „zatrzymuje się”. Jednak doświadczenie natychmiast się zmienia dla każdego, kto próbuje przenieść prawdziwą wartość. Podjęcie decyzji zajmuje więcej czasu, pewność siebie spada, a każde przekazanie w procesie zaczyna wymagać drugiego sprawdzenia. To nie jest dramatyczna awaria, na którą ludzie się przygotowują. To cicha forma, która zamienia rutynowe rozliczenie w ostrożne czekanie.
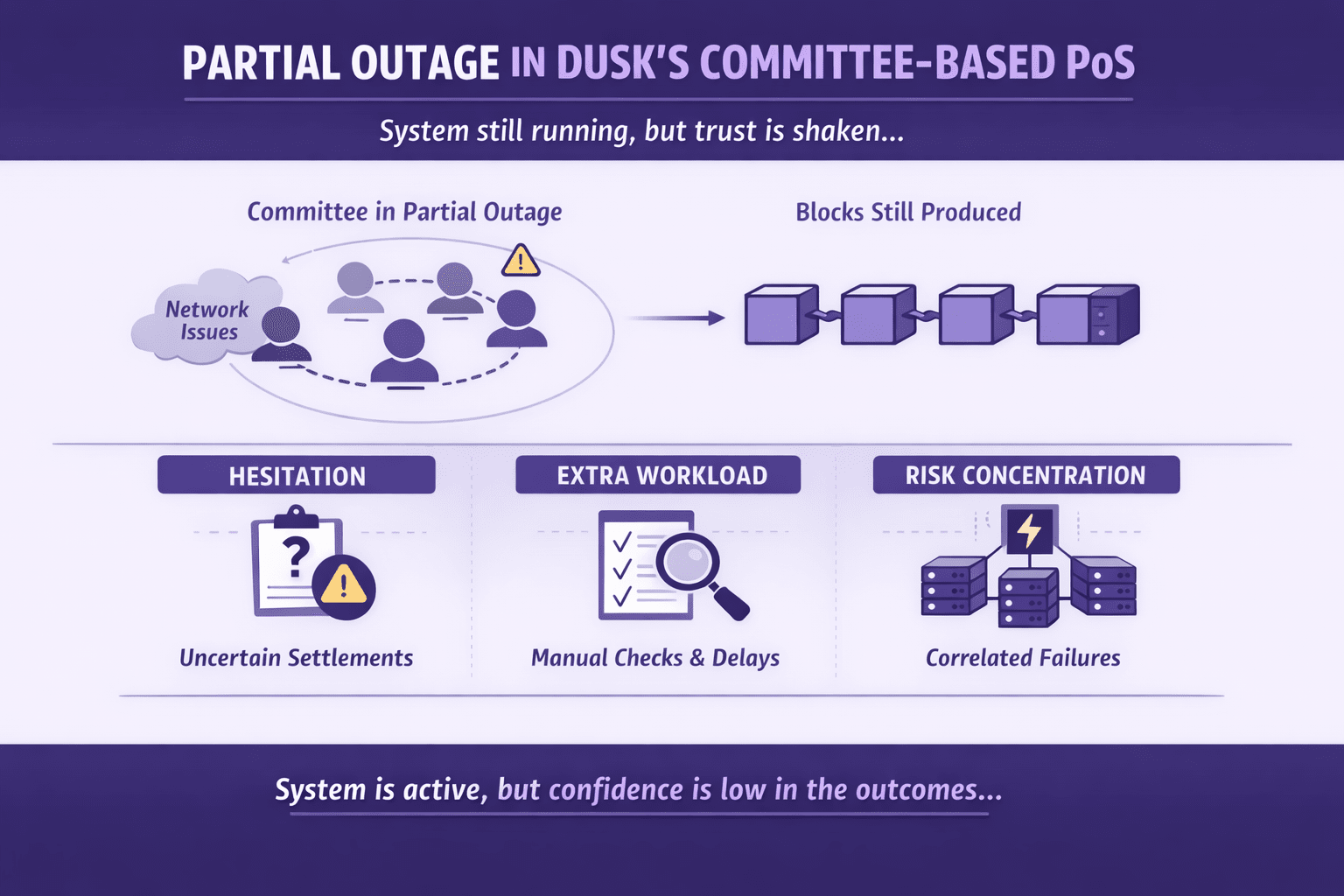
To jest miejsce, w którym oparta na komitetach metoda dowodu stawki Dusk staje się prawdziwą historią operacyjną. W idealnych warunkach komitety są wydajne. Redukują liczbę uczestników potrzebnych do osiągnięcia zgody, dzięki czemu wyniki przychodzą szybko i przewidywalnie. Dokładnie tego chcą regulowane rynki: nie tylko szybkości, ale czystego zakończenia. Problem polega na tym, że częściowa awaria atakuje jedną rzecz, którą komitety mają zapewnić — wiarygodną koordynację.
Podczas częściowej awarii niektórzy walidatorzy mogą być wolni, niedostępni lub utknąć z powodu problemów sieciowych. Nie zniknęli na zawsze, ale przestają działać synchronicznie. To samo może przekształcić cały system. Komitet nie potrzebuje, aby wszyscy odpowiadali, ale potrzebuje wystarczającej liczby odpowiedzi w odpowiednim czasie, aby proces był płynny. Gdy odpowiedzi przychodzą późno, protokół może nadal się poruszać, ale osoby budujące na jego szczycie odczuwają niedopasowanie.
Pierwszy widoczny wpływ to wahanie. Aplikacje i użytkownicy przestają działać na „prawdopodobnych” wynikach. Zespół handlowy nie chce oznaczać pozycji jako zamkniętej, chyba że rozliczenie jest bezsprzecznie zakończone. Emitent nie chce aktualizować rekordów, jeśli istnieje szansa, że stan sieci będzie wymagał korekty lub ponownego sprawdzenia. Nawet gdy technicznie nic nie jest nie tak, ludzcy operatorzy wprowadzają tarcia, ponieważ koszt bycia w błędzie jest wyższy niż koszt bycia wolnym.
Drugi wpływ to obciążenie operacyjne. Gdy ostateczność wydaje się mniej czysta, zespoły rekompensują to ręcznymi krokami bezpieczeństwa: dodatkowymi monitorowaniami, powtarzanymi kontrolami potwierdzającymi i wewnętrzną rekonsyliacją. To, co powinno być prostą linią, staje się pętlą. To jest miejsce, gdzie czas znika. Nie wewnątrz samego protokołu, ale w otaczającej „warstwie zaufania”, którą instytucje budują, gdy nie mogą sobie pozwolić na niepewność.
Trzeci wpływ to koncentracja ryzyka. Komitety są mniejsze niż cały zestaw walidatorów, dlatego mogą być szybkie. Ale mniejsze zestawy oznaczają również, że skorelowane awarie mają większe znaczenie. Jeśli kilku członków komitetu korzysta z tego samego dostawcy chmury, regionu lub trasy sieciowej, jeden incydent może usunąć znaczną część grupy jednocześnie. To szybko zmienia profil bezpieczeństwa i wydajności, nawet jeśli reszta sieci jest zdrowa.
Projekt Dusk jest zbudowany wokół regulowanej finansów, więc prawdziwą miarą odporności nie jest to, czy bloki nadal przychodzą. Miara to, czy rozliczenie pozostaje nudne. Częściowe awarie testują tę nudność. Ujawnią, czy system może pozostać przewidywalny, gdy komitet jest niedoskonały, sieć jest nierówna, a użytkownicy wrażliwi na czas obserwują zegar.
Ostatecznie częściowa awaria nie jest głównie zdarzeniem protokołu. To jest zdarzenie zaufania. Łańcuch nadal może działać, ale rynek funkcjonuje tylko wtedy, gdy uczestnicy mogą traktować wyniki jako zakończone bez dodawania przypisów. To jest standard, do którego dąży Dusk — i dokładny standard, który ma na celu wyzwanie częściowych awarii.
\u003cm-35/\u003e \u003ct-37/\u003e \u003cc-39/\u003e
