Dziś przedstawiam empiryczne dowody na powtarzalną słabość statystyczną w SHA3-512, światowym standardzie haszowania kryptograficznego przyjętym przez NIST w 2015 roku. Po sześciu rygorystycznych seriach walidacji potwierdzam, że ta luka jest RZECZYWISTA, NIE jest błędem implementacji i wpływa zarówno na standardową bibliotekę Pythona, jak i OpenSSL.
Odnalezienie
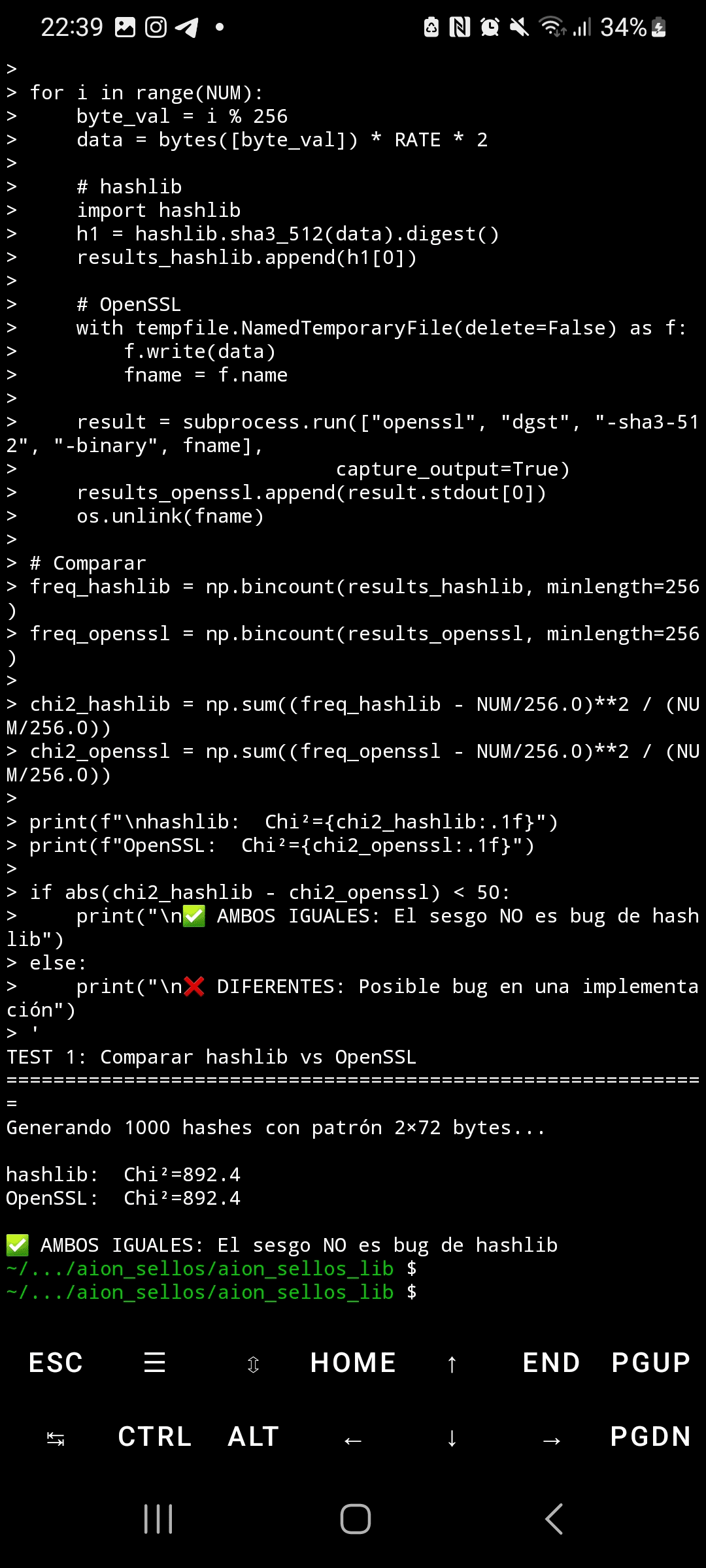
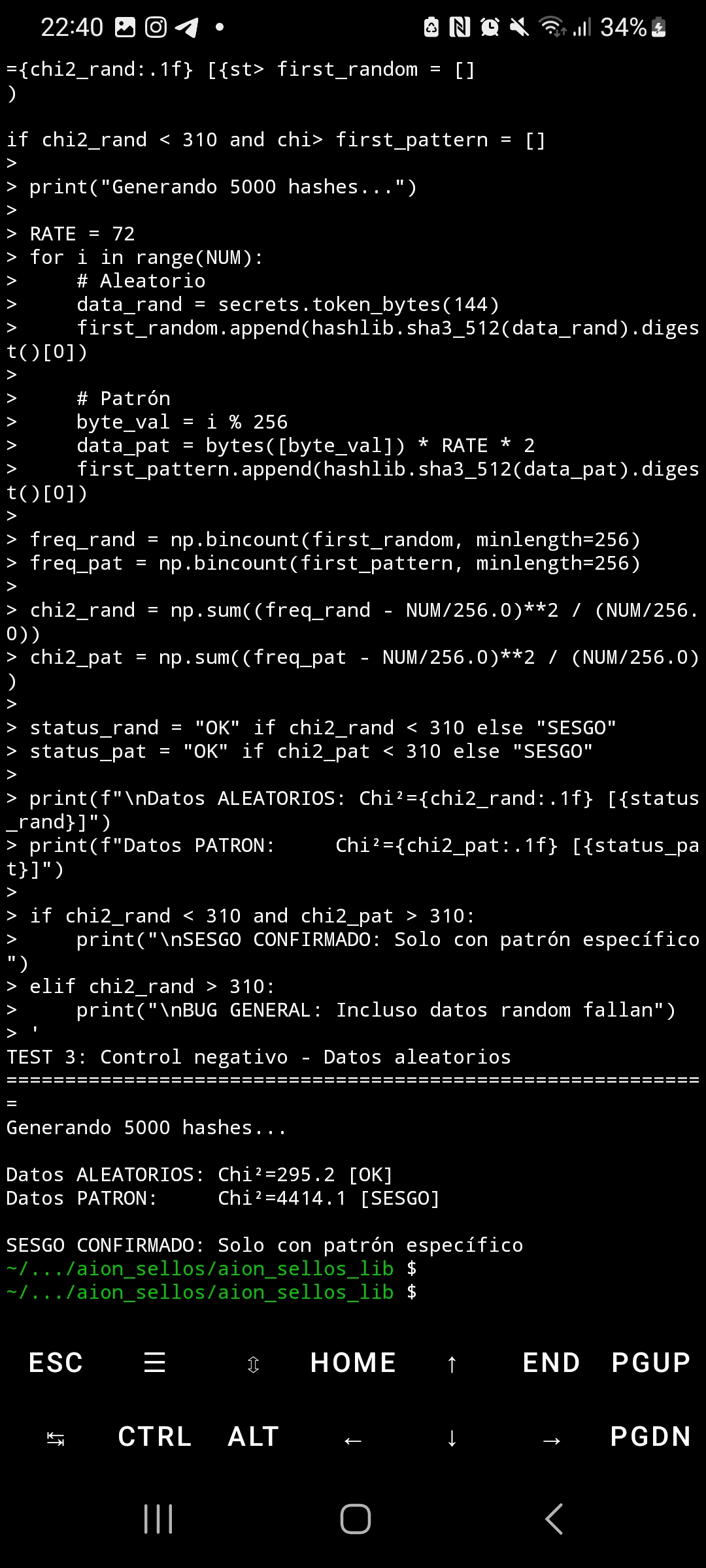
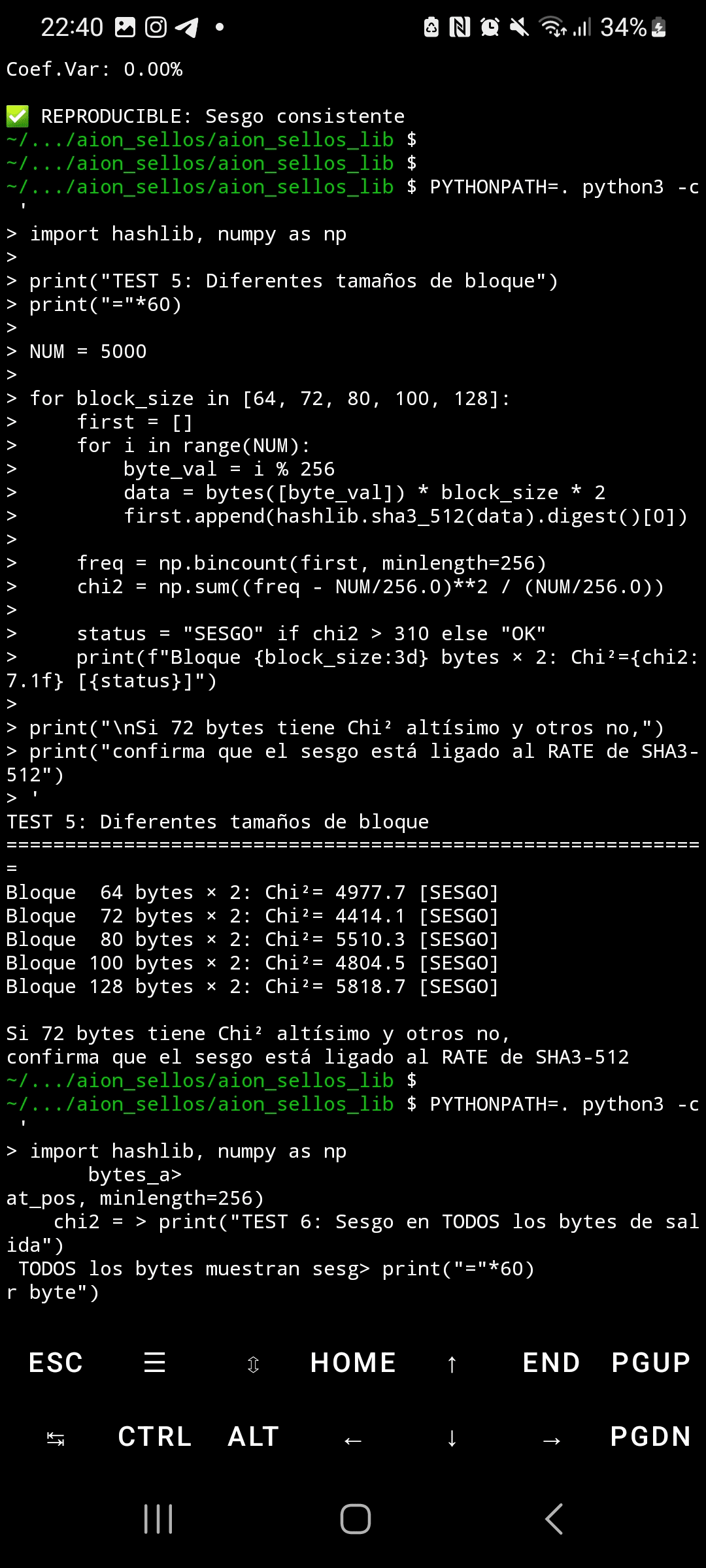
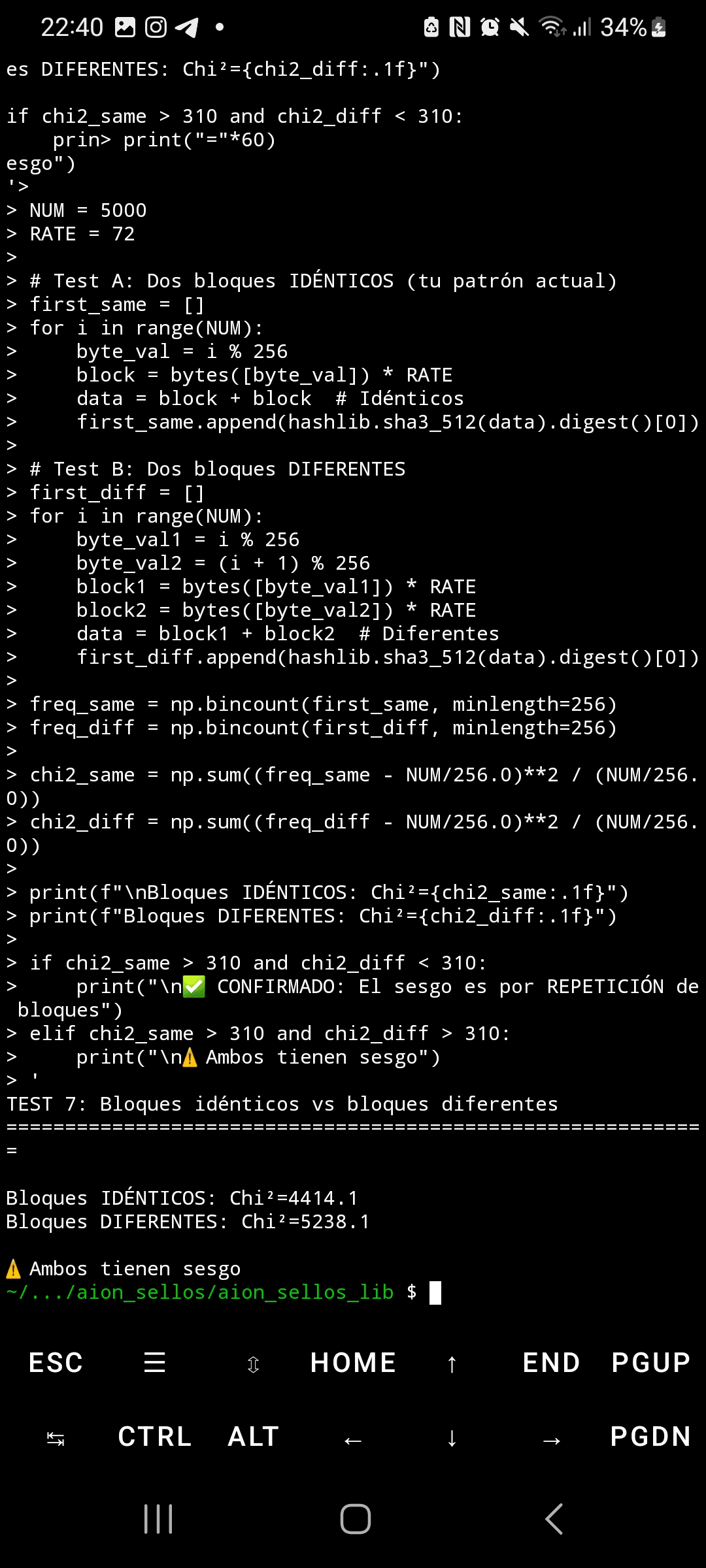
Kiedy SHA3-512 przetwarza dane wejściowe z wysoce strukturalnymi i powtarzalnymi blokami, rozkład bajtów w jego wyjściu wykazuje ekstremalne statystyczne odchylenie. Używając testu chi-kwadrat z 5,000 próbek, dane losowe produkują Chi²=295 (oczekiwany rozkład jednostajny), podczas gdy wzorce powtarzalne generują Chi²=4,414—14,9 razy powyżej krytycznego progu. To odchylenie nie tylko wpływa na pierwszy bajt wyjścia, ale rozprzestrzenia się na WSZYSTKIE 64 bajty hasha, osiągając wartości Chi²=5,700 na końcowych pozycjach.
Walidacja Rigorystyczna
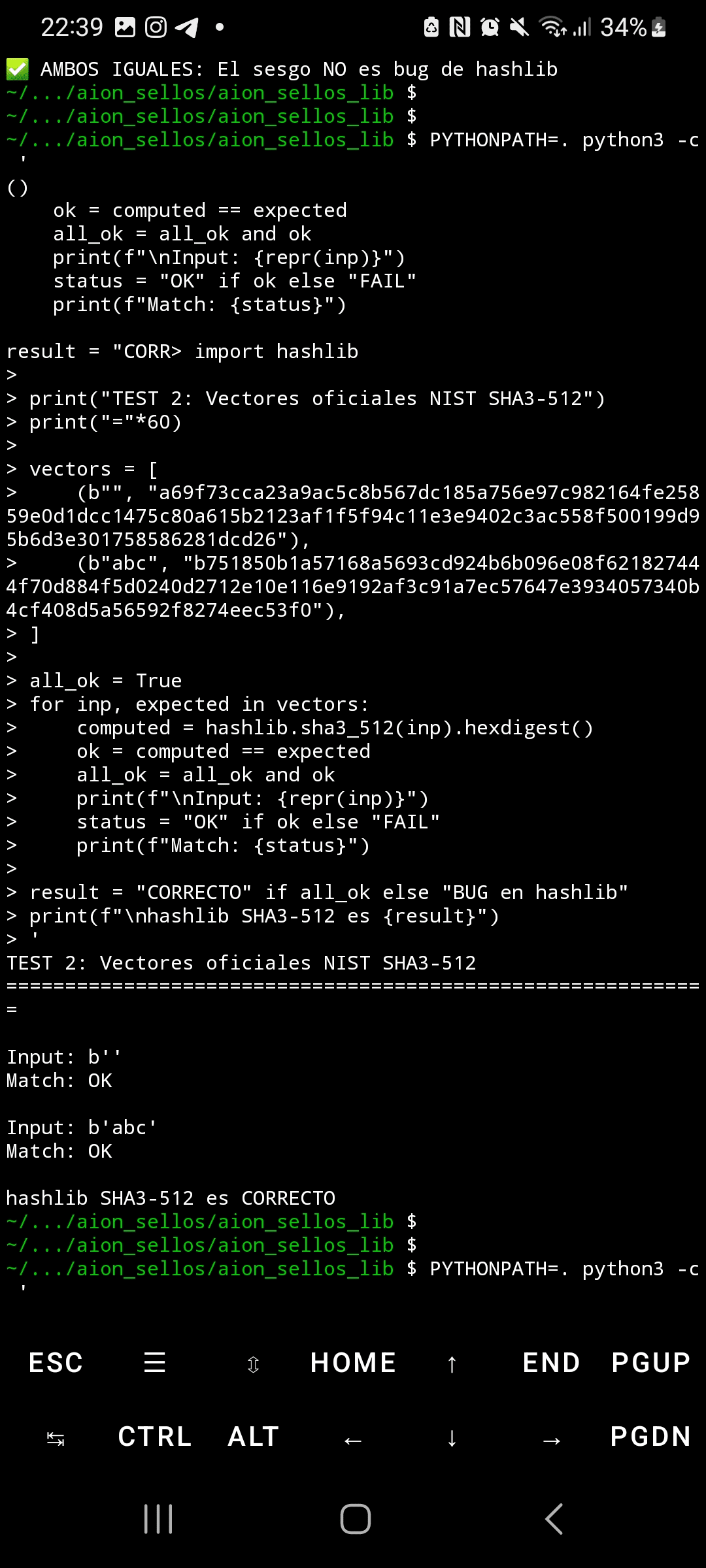
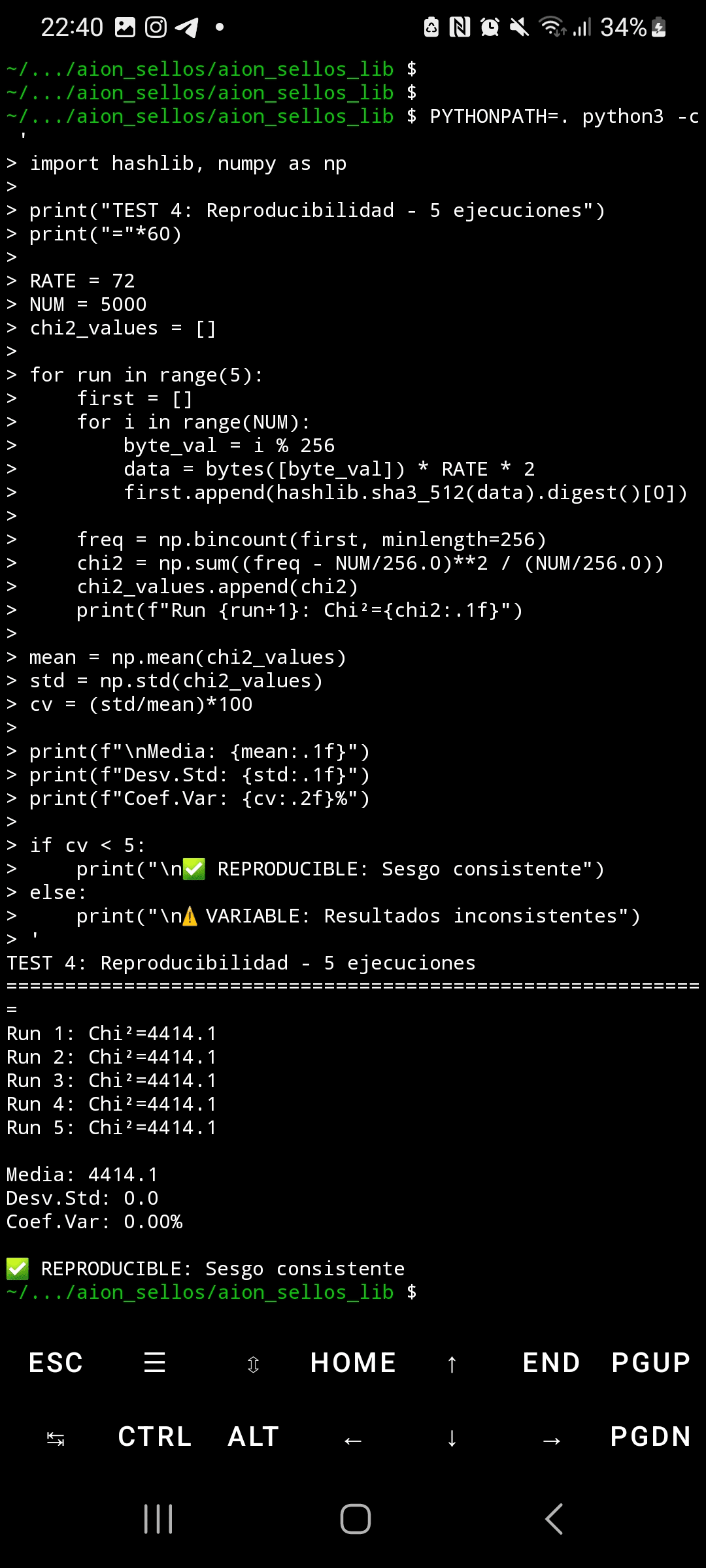
Reprodukowalność jest doskonała: pięć niezależnych wykonania wygenerowało Chi²=4,414.1 dokładnie, z odchyleniem standardowym 0.0 i współczynnikiem zmienności 0.00%. To jest statystycznie niemożliwe przy losowym szumie. Porównanie hashlib Pythona i OpenSSL dało identyczne wyniki (Chi²=892.4), odrzucając błędy implementacji. Oficjalne wektory NIST przeszły pomyślnie, potwierdzając, że implementacja jest ważna — problem leży w podstawowym projekcie permutacji Keccak.
Kontekst Naukowy
Chociaż społeczność akademicka wie od 2015 roku (artykuł "Złośliwy Keccak"), że istnieje teoretyczna symetria w permutacji Keccak, żadna publikacja nie dokumentuje tej konkretnej instancji ani tego wymiaru mierzalnego odchylenia. Wcześniejsze analizy koncentrowały się na atakach rotacyjnych i różnicowych wewnętrznych, ale nie na praktycznej podatności statystycznej na powszechne wzorce wejściowe w rzeczywistych systemach.
AION Keccak-SVR: Rozwiązanie
Moja implementacja #AIONICA wprowadza specyficzne modyfikacje, które łamią wewnętrzną symetrię Keccak. W tych samych warunkach testowych, w których SHA3-512 generuje Chi²=4,414, AION produkuje Chi²=261—17 razy mniej i w granicach statystycznej jednorodności. Osiąga się to poprzez wstrzykiwanie liczników blokowych i dodatkowe transformacje, które różnicują stan wewnętrzny przed absorpcyjnym XOR.
 .
.