Estava lendo o litepaper do protocolo SIGN e alguns exemplos de repositórios mais cedo, tentando principalmente mapear onde ele realmente se encontra na pilha. inicialmente parece bastante simples — credenciais na forma de atestações, então alguma lógica para distribuir tokens com base nessas credenciais. meio que como formalizar o que as equipes já juntam antes dos lançamentos.
e eu acho que esse é o modelo mental padrão. as pessoas veem “verificação de credenciais + distribuição de tokens” e assumem que é apenas um pipeline de airdrop mais limpo. defina elegibilidade, execute verificações, envie tokens. feito.
mas essa não é a imagem completa.
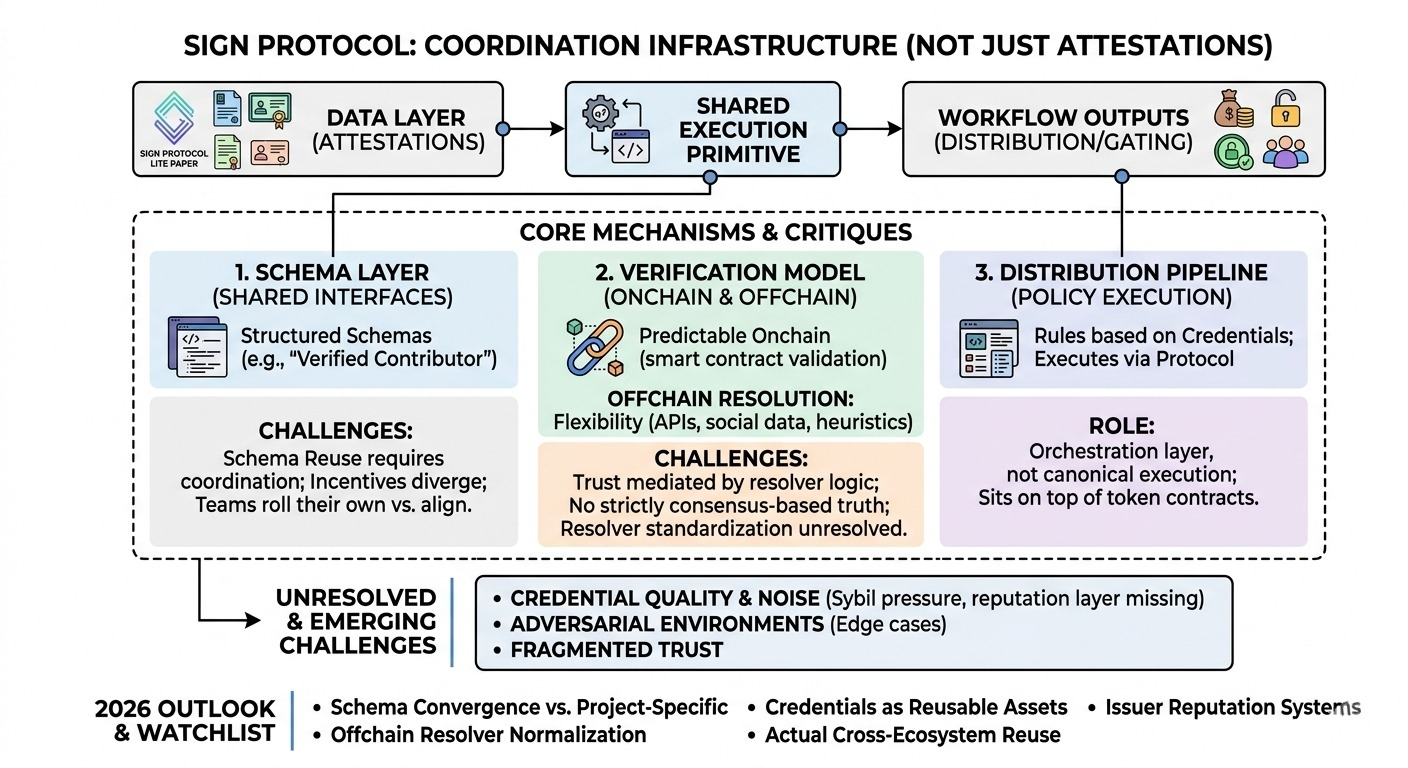
a coisa mais profunda que a SIGN está fazendo é tentar transformar credenciais em um primitivo de execução compartilhada, não apenas um registro de dados. em vez de atestações serem passivas (algo que você consulta), elas se tornam entradas ativas em fluxos de trabalho — especialmente distribuição. e uma vez que você faz isso, você não está mais apenas armazenando reivindicações, você está coordenando resultados.
o primeiro mecanismo que se destaca é a camada de esquema. A SIGN se baseia fortemente em esquemas estruturados para atestações — não apenas blobs de chave/valor arbitrários, mas formatos predefinidos que descrevem o que uma credencial representa. no papel, isso parece modelagem de dados padrão, nada especial.
mas aqui está a questão — se esquemas são reutilizados entre aplicações, eles começam a agir como interfaces compartilhadas. um esquema de "colaborador verificado" em um ecossistema poderia, em teoria, ser consumido por outro sem tradução. mas essa é uma grande suposição. a reutilização de esquemas requer coordenação, e a coordenação tende a se desmoronar uma vez que os incentivos divergem.
parte disso está ao vivo. projetos já estão emitindo atestações contra esquemas e usando-os internamente. mas a composabilidade entre projetos ainda parece mais uma promessa do que uma realidade. ainda não vejo evidências fortes de que as equipes estão se alinhando em definições de esquemas compartilhados em vez de criar suas próprias variações sutis.
o segundo é o modelo de verificação, que é mais sutil do que parece. SIGN suporta tanto a verificação onchain quanto a resolução offchain. onchain é previsível — você pode validar atestações diretamente via contratos. offchain é onde a flexibilidade entra: puxando dados externos, APIs, sinais sociais, o que for.
e é aí que fica interessante. uma vez que você permite resolvers offchain, você introduz uma camada onde a verdade não é mais estritamente baseada em consenso. é mediada por quem executa a lógica do resolver. dois sistemas poderiam tecnicamente "verificar" a mesma credencial de forma diferente dependendo de como resolvem dependências externas.
isso não é necessariamente uma falha — provavelmente é necessário para casos de uso do mundo real — mas isso significa que o modelo de confiança é mais complexo do que "está onchain, então está correto." partes disso já estão operacionais, especialmente em verificações de elegibilidade que dependem de heurísticas offchain. mas padronizar o comportamento do resolver, ou mesmo definir quais garantias eles devem fornecer, parece não resolvido.
a terceira parte é o pipeline de distribuição, que é arguivelmente o mais concreto hoje. SIGN conecta atestações diretamente à lógica de distribuição de tokens. em vez de exportar listas e escrever scripts, você define regras com base em credenciais e executa distribuições através do protocolo.
isso está claramente funcionando em contextos de produção. equipes estão usando para gerenciar airdrops, recompensas a colaboradores, restrições de acesso. reduz a coordenação manual e torna o processo mais reproduzível. mas também levanta uma questão estrutural: a SIGN está apenas orquestrando distribuições, ou está tentando se tornar a camada de execução canônica para elas?
agora parece orquestração. fica em cima dos contratos de token em vez de substituí-los. talvez isso seja intencional — mantendo-se modular em vez de possuir toda a pilha.
as partes mais ambiciosas — gráficos de identidade persistente, portabilidade de credenciais entre cadeias, integrações mais profundas em nível de carteira — ainda estão se formando. elas dependem fortemente dos padrões de adoção. as credenciais só se tornam significativas entre sistemas se outros sistemas concordarem em honrá-las, e isso não é algo que um protocolo pode impor.
uma coisa que continua me incomodando é a qualidade da credencial. se a emissão é barata e sem permissão, então o sistema precisa de alguma forma de diferenciar atestações de alto sinal de ruído. SIGN não resolve isso diretamente. fornece os trilhos, mas não a camada de reputação.
então você acaba empurrando essa responsabilidade para aplicações ou para alguma futura meta-camada. o que pode funcionar, mas também fragmenta a confiança novamente.
também não tenho certeza de como isso se comporta sob pressão adversarial. padrões sybil, emissores coordenados, manipulação de esquemas — todos gerenciáveis individualmente, mas juntos eles criam casos limites que não são óbvios a partir da abstração limpa.
assistindo:
* se os esquemas convergem em padrões compartilhados ou permanecem específicos do projeto
* como os resolvers offchain são implementados e se eles se normalizam ao longo do tempo
* se a distribuição permanece o principal ponto de entrada em vez de credenciais se tornarem ativos reutilizáveis
* surgimento de sistemas de reputação ou ponderação de emissores
* reutilização real de credenciais entre ecossistemas, não apenas dentro de plataformas únicas.
$SIGN @SignOfficial #signdigitalsovereigninfra