Fogo se posiciona como uma blockchain de Camada 1 ultra rápida, otimizada para tempos de bloco abaixo de 100 milissegundos e ambientes de execução de alta frequência. Abordei isso não como uma narrativa de marketing, mas como um pesquisador de sistemas abordaria qualquer protocolo distribuído, examinando artefatos de testnet, comportamento de validadores, detalhes de implementação e superfícies de falha. Em vez de repetir as alegações do whitepaper, concentrei-me no que pode ser inferido a partir de repositórios públicos, notas de lançamento, benchmarks de devnet e comentários do ecossistema.
Em um nível alto, o Fogo é um Layer 1 compatível com SVM que adapta ideias arquitetônicas do Solana enquanto introduz um modelo de consenso zonal e um cliente de validador altamente otimizado derivado do Firedancer. Seu objetivo de engenharia declarado é a execução de latência extremamente baixa, especialmente para aplicações intensivas em comércio. Materiais públicos, incluindo seu litepaper e documentação, delineiam uma arquitetura que combina sequenciamento no estilo Proof of History com um mecanismo de rotação baseado em zona, destinado a minimizar os atrasos de propagação da rede durante épocas ativas.
O primeiro pilar de design que se destaca é a localidade física. Dentro de uma zona ativa, a mensagem de consenso se beneficia de latências de hardware próximas. Em teoria, isso reduz o componente de propagação da rede do tempo de bloco de uma variável de internet global para uma restrição de engenharia controlável. A rotação horária ou periódica de zonas ativas é projetada para prevenir a centralização permanente da produção de blocos.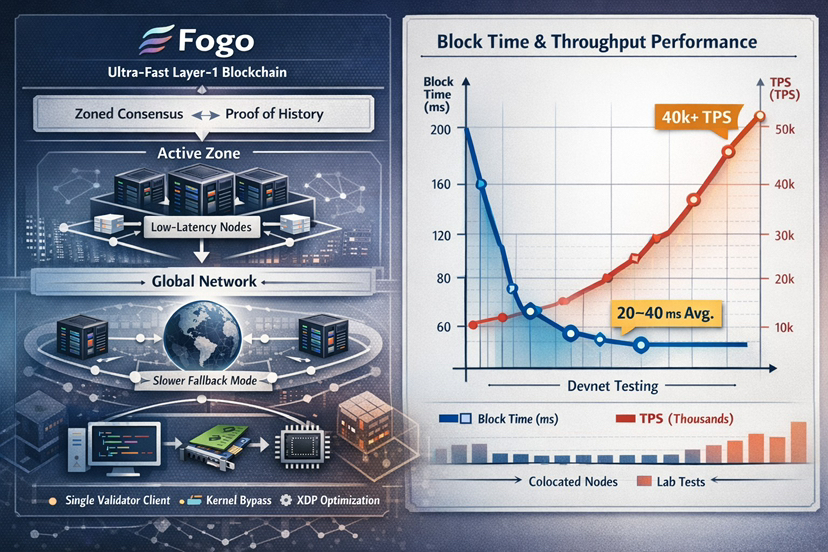
O segundo pilar é a implementação do validador em si. O Fogo depende de um único cliente de validador dominante derivado do Firedancer, projetado com otimizações agressivas de rede e agendamento. Notas de lançamento e artefatos de repositório indicam atenção às técnicas de bypass de kernel, caminhos de XDP e cuidadosa minimização da sobrecarga de serialização. Estas não são alterações superficiais; elas visam a redução da latência de cauda em nível de microssegundos.
Do ponto de vista da engenharia, esses são alavancas de desempenho legítimas. Se os validadores estão fisicamente próximos e a pilha de rede é rigidamente otimizada, tempos de bloco abaixo de 50 milissegundos são tecnicamente plausíveis. A questão não é se tal desempenho é alcançável em um ambiente de laboratório, mas se essas condições persistem em condições adversariais, heterogêneas e do mundo real.
Artefatos públicos de devnet e testnet relatam tempos de bloco na faixa de 20-40 milissegundos em condições favoráveis e números de throughput na casa das dezenas de milhares de transações por segundo. Esses números aparecem em anúncios de testnet e resumos de terceiros. Importante, as condições anexadas a esses benchmarks importam: conjuntos de validadores colocalizados, hardware homogêneo e misturas de transações sintéticas projetadas para estressar o throughput em vez de refletir o uso bagunçado do mundo real.
Em pesquisa de sistemas distribuídos, benchmarks de laboratório são necessários, mas insuficientes. Um ambiente homogêneo e provisionado revela limites superiores. A internet pública global revela variância. Latência de cauda, perda de pacotes, roteamento assimétrico e heterogeneidade de validadores introduzem dinâmicas que benchmarks raramente capturam.
Eu olhei para o que o código público e artefatos operacionais revelam sobre o comportamento. Os repositórios do GitHub mostram uma única implementação de validador primário. Esta escolha arquitetônica reduz a sobrecarga de coordenação e elimina bugs de divergência de múltiplos clientes, mas também introduz o risco de falha de modo comum. Em um ecossistema de cliente único, um bug determinístico pode propagar-se em toda a rede.
O kernel bypass e o XDP reduzem a latência, mas aumentam a sensibilidade operacional. Incompatibilidades de firmware ou regressões de driver podem afetar características de desempenho de maneiras que são sutis, mas materiais, em alvos de 20 milissegundos.
O mecanismo de consenso zonal introduz outra superfície comportamental interessante. Durante a época de uma zona ativa, a produção de blocos e a votação são otimizadas para velocidade local. Se a zona experimentar perda de quórum ou problemas de conectividade, o protocolo reverte para um modo de consenso global mais lento. Este mecanismo de fallback é explicitamente projetado para segurança e, do ponto de vista do protocolo, é reconfortante. No entanto, introduz um modelo de desempenho bimodal, extremamente rápido em condições ótimas de zona e mais lento sob fallback.
Não encontrei extensos logs de falhas disponíveis publicamente com profundas análises pós-morte. A rede é relativamente jovem e as primeiras testnets costumam operar com conjuntos de validadores curados. Isso reduz a visibilidade em eventos raros de falha.
Se uma zona ativa se torna parcialmente isolada, os validadores dentro dessa zona poderiam continuar produzindo blocos sob a suposição de quórum local. A segurança depende de como a finalização é definida e como a reintegração é tratada. Projetado corretamente, blocos de uma zona particionada não seriam considerados globalmente finais. Gerenciados de forma inadequada, tais partições podem levar a complexidade de reorganização e inconsistências visíveis para o usuário.
Bugs determinísticos de cliente único são outra superfície de risco. Um pânico em um caminho de código quente, erro de desserialização, má gestão de memória ou deadlock do agendador podem se propagar entre validadores quase simultaneamente. Em ecossistemas de múltiplos clientes, a diversidade de implementação limita o raio de explosão. Em um sistema de cliente único, o raio de explosão é em toda a rede, a menos que mitigado por correções rápidas e coordenadas.
Zonas ativas rotativas distribuem influência ao longo do tempo, mas introduzem sobrecarga de coordenação. Se o tempo de votação não se alinha ou se os validadores discordam sobre o limite preciso de uma época sob carga, pode ocorrer degradação temporária da vivacidade. O fallback para o modo global mitiga o risco de segurança, mas altera as características de confirmação no meio do processo.
A centralização física aumenta a exposição a riscos não protocolares: interrupções em data centers, congestionamento de conexões cruzadas ou até mesmo pressões regulatórias ou coercitivas.
Nenhuma dessas preocupações nega a inovação. A engenharia de desempenho na camada de rede é trabalho real. Reduzir a latência de cauda na fronteira do kernel não é trivial. O consenso zonal é um reconhecimento prático de que a velocidade é limitada pela física e que a localidade pode ser explorada intencionalmente.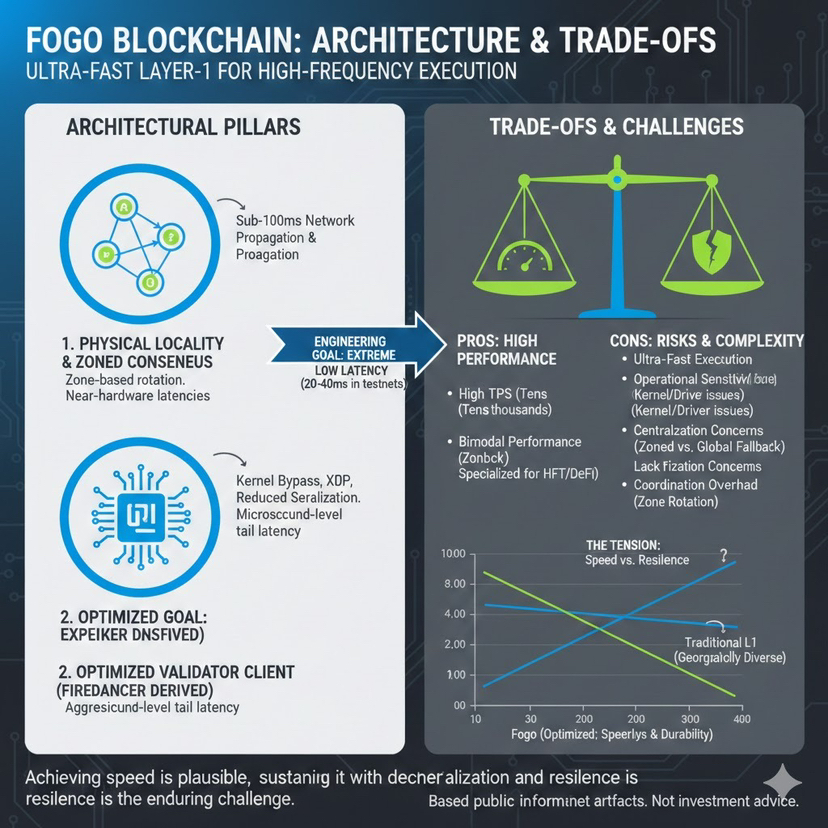
A pergunta mais sutil é a sustentabilidade. O comércio de alta frequência e os primitivos DeFi sensíveis à latência se beneficiam diretamente de tempos de bloco ultra rápidos. Mas os ecossistemas não são definidos apenas por TPS de pico. Eles são definidos pela diversidade de operadores, segurança de atualização, maturidade de ferramentas e resiliência sob estresse.
Construtores que implantam em uma rede assim devem instrumentar agressivamente. Histograma de latência por RPC, telemetria em nível de NIC e métricas de propagação de gossip tornam-se preocupações de monitoramento de primeira classe. A lógica da aplicação deve tolerar mudanças de modo entre operação de alta velocidade zonal e fallback global. Incentivar implementações adicionais de validadores ao longo do tempo melhoraria materialmente a resiliência sistêmica.
Do ponto de vista de um pesquisador, a tensão chave reside nos trade-offs. Um consenso ultra rápido é alcançável se alguém estiver disposto a restringir a topologia e otimizar agressivamente. Mas a descentralização e a durabilidade impõem seus próprios custos. A dispersão geográfica aumenta o atraso de propagação. A diversidade de clientes aumenta a sobrecarga de coordenação. Mecanismos de fallback conservadores reduzem o throughput máximo.
A questão duradoura é se desempenho, descentralização e durabilidade do ecossistema podem coexistir sem que um subordine permanentemente os outros. Se a velocidade se tornar o valor dominante, o sistema corre o risco de fragilidade sob eventos raros. Se a descentralização dominar, a latência inevitavelmente aumenta. O desafio mais interessante para o Fogo não é alcançar blocos de 20 milissegundos em um ambiente controlado, mas sim manter uma descentralização credível e um comportamento de recuperação robusto enquanto opera nessas velocidades.
Em última análise, designs de Layer 1 ultra rápidos forçam a comunidade a confrontar uma realidade estrutural: ganhos de desempenho raramente são gratuitos. Eles são comprados com suposições sobre hardware, topologia, governança e coordenação. Se essas suposições permanecem válidas à medida que as redes crescem e as condições adversariais se intensificam, determinará se tais arquiteturas amadurecem em infraestrutura financeira durável ou permanecem trilhos especializados otimizados para casos de uso restritos.
