Análise rápida a partir do benchmark
A execução otimista é a diferença fundamental
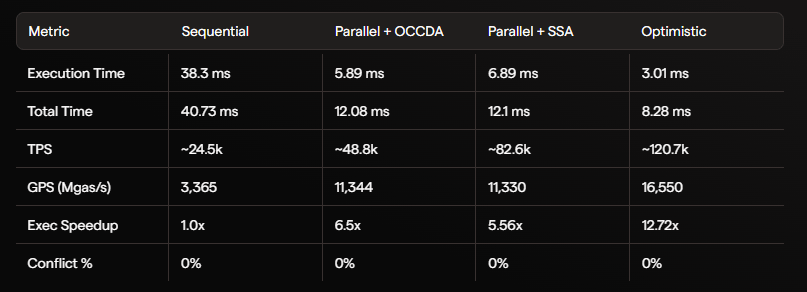
Na execução bruta, a execução otimista alcançou 12.72x em comparação com sequencial e mais de 16.550 Mgas/s. Isso mostra que o gargalo não está mais na CPU de thread única tradicional.
O ponto importante não é apenas ter TPS alto, mas sim a capacidade de escalar linearmente ao aumentar a thread em condições sem conflito.
End to End é o verdadeiro teste prático
A execução bruta apenas reflete os limites teóricos.
Benchmark End to End novo mostra desempenho em ambientes de nó reais, incluindo:
• IO de Banco de Dados
• Cálculo de raiz de estado
• Pipeline de processamento de blocos
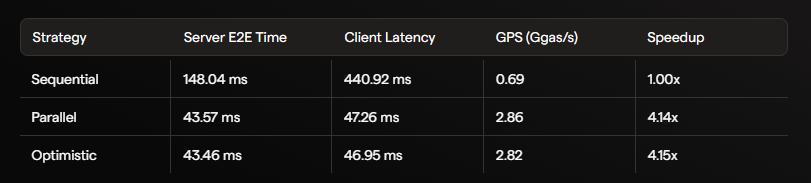
No Cenário A zero conflito:
O desempenho aumenta mais de 4 vezes. Este é um aumento muito significativo para a infraestrutura de nó padrão.
Quando o conflito aumenta, o desempenho diminui
Cenário B com 50% de conflito ainda mantém quase 2x de aumento de velocidade.
Isso mostra que o scheduler foi projetado para degradar graciosamente em vez de falhar no desempenho abruptamente quando a contenção é alta.
Com a carga de trabalho DeFi real, o conflito nunca é 0%, então a capacidade de processamento em um ambiente de alta contenção é o fator decisivo.

Significado para o ecossistema L2
Se a camada de execução puder alcançar 1.8 a 2.8 Ggas/s estável em ambientes reais, então:
• Através L2 pode aumentar significativamente
• As taxas de transação podem diminuir
• A latência de confirmação de bloco é melhorada
• A capacidade de escalar aplicativos DeFi complexos é maior
Este é um avanço de otimização de desempenho micro para otimização de toda a arquitetura de execução.