Uma reclamação continua aparecendo sobre grandes modelos de linguagem.
Eles soam autoritários mesmo quando estão errados.
O perigo não é apenas a alucinação. É a confiança sobreposta à incerteza. Uma resposta pode ser estruturada, fluente e persuasiva, enquanto ainda contém sutis erros factuais ou viés embutido. Isso cria um risco que a maioria dos usuários subestima.

No núcleo, os LLMs operam em distribuições de probabilidade. Eles preveem sequências prováveis, não verdades verificadas. Pesquisas mostram que a alucinação não é um bug que desaparece com a escala. É uma limitação inerente da geração probabilística. Tentativas de reduzir a alucinação por meio de uma curadoria de dados mais rigorosa geralmente aumentam o viés. Expandir conjuntos de dados para reduzir o viés pode aumentar a inconsistência. Há um compromisso estrutural do qual nenhum modelo único escapa totalmente.
Isso se torna crítico à medida que a IA avança para domínios de maior consequência. Sistemas de negociação, ferramentas de conformidade, resumos médicos, redação legal, agentes autônomos. Nessas áreas, parecer certo não é suficiente. Ser correto importa.
A questão mais profunda é a arquitetura. A maioria dos sistemas de IA depende de validação centralizada ou supervisão humana. Isso não escala em um mundo onde agentes de IA operam continuamente e globalmente.
É aqui que @Mira - Trust Layer of AI reformula o problema.
Em vez de tentar aperfeiçoar um modelo, a MIira $MIRA introduz uma camada de verificação descentralizada. As saídas de IA são decompostas em alegações granulares e independentes. Cada alegação é distribuída por vários nós verificadores. Esses nós executam sua própria inferência e submetem julgamentos que são agregados em consenso.
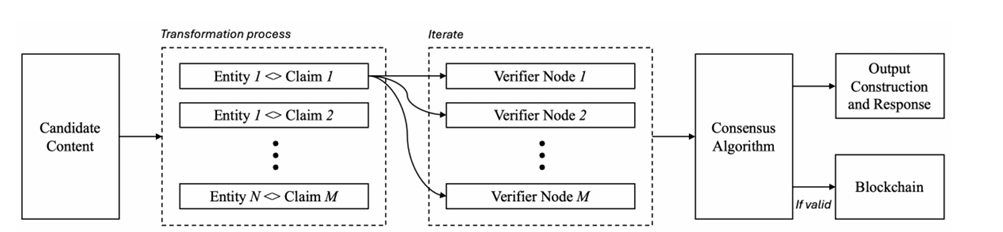
O que torna isso diferente é a camada econômica. Os validadores devem apostar valor. Se tentarem adivinhar ou se desviarem sistematicamente do consenso, sua aposta pode ser reduzida. O whitepaper quantifica até como rodadas de verificação repetidas reduzem acentuadamente a probabilidade de adivinhação aleatória bem-sucedida. Ao longo de várias iterações, a manipulação estatística torna-se economicamente irracional.

Há também um benefício estrutural para a descentralização. Conjuntos centralizados ainda refletem o viés de quem seleciona os modelos. Uma rede sem permissão incentiva a diversidade nas abordagens de treinamento e perspectivas. À medida que a participação escala, o viés sistêmico pode ser diluído por meio de consenso heterogêneo em vez de curadoria controlada.
A privacidade está embutida no design. Saídas complexas são transformadas em alegações em nível de entidade e fragmentadas aleatoriamente, de modo que nenhum nó único reconstrói todo o contexto. A verificação ocorre sem expor documentos completos a operadores individuais.
A visão maior vai além da verificação da geração de postagens. O objetivo é incorporar a verificação diretamente na própria geração, fundindo inferência e validação em um processo unificado. Se alcançado, isso mudaria a IA de uma saída probabilística para uma confiabilidade econômica segura.
À medida que os sistemas de IA começam a mover capital, automatizar decisões e moldar o discurso público, a questão não é mais quão inteligentes eles parecem.
A verdadeira questão é se suas saídas podem ser confiáveis sem supervisão humana.
Essa é a lacuna estrutural $MIRA que estamos tentando fechar por meio de uma infraestrutura de verificação descentralizada e alinhada por incentivos.