@Mira - Trust Layer of AI #Mira
Por anos, a conversa em torno da inteligência artificial se concentrou quase que inteiramente na capacidade: modelos maiores, inferência mais rápida, mais dados e saídas cada vez mais impressionantes que parecem, pelo menos na superfície, aproximar-se do raciocínio humano. No entanto, por trás desse progresso rápido, há uma questão mais silenciosa e difícil que a indústria só começou a confrontar com seriedade recentemente: como determinamos quando um sistema de IA é realmente confiável? Não simplesmente convincente, não meramente confiante, mas confiável de uma maneira que instituições, mercados e infraestrutura crítica possam depender sem hesitação.
O desafio existe porque os sistemas de IA modernos não produzem conhecimento no sentido tradicional; eles geram probabilidades moldadas por padrões em seus dados de treinamento. Um modelo pode soar autoritário enquanto fabrica silenciosamente uma citação, interpreta mal uma cláusula regulatória ou combina fragmentos de informação em algo que parece lógico, mas repousa sobre fundações instáveis. Essas falhas raramente aparecem de forma dramática. Em vez disso, elas se manifestam como distorções sutis que passam despercebidas até que suas consequências surjam em relatórios financeiros, resumos de pesquisa ou decisões automatizadas que dependem da saída do modelo como se fosse um fato verificado.
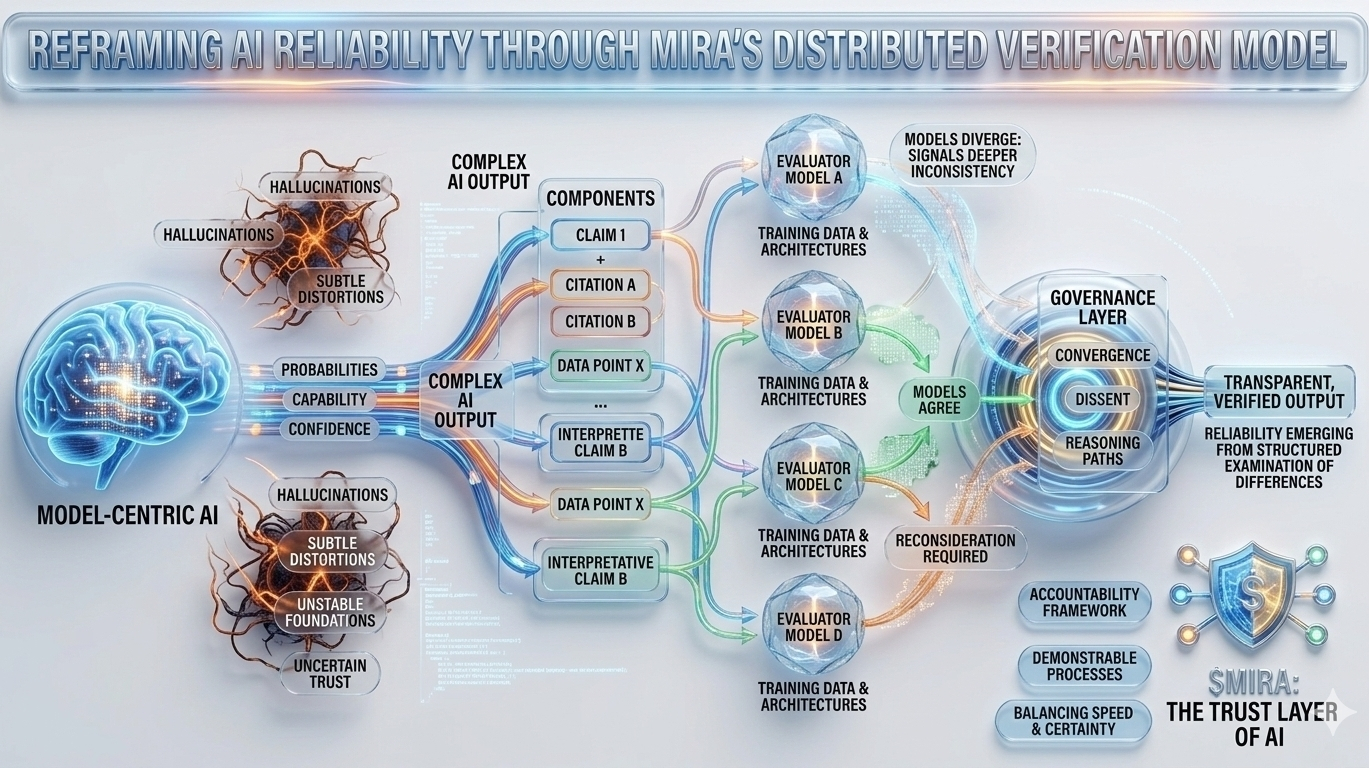
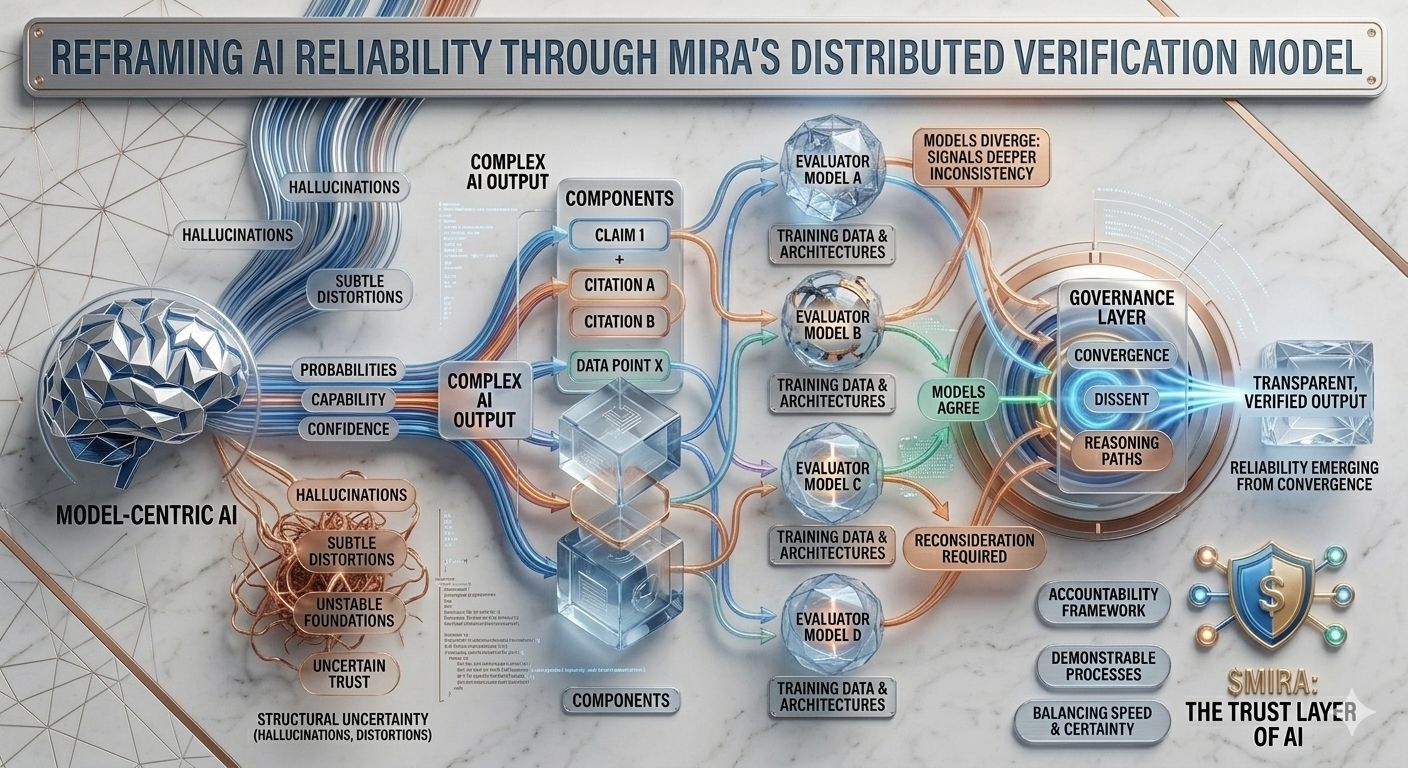
Essa incerteza estrutural é precisamente o problema que a Mira tenta resolver, não exigindo perfeição de um único modelo, mas repensando todo o processo pelo qual as respostas de IA são produzidas e validadas. Na arquitetura da Mira, uma saída de IA é tratada menos como uma conclusão final e mais como uma hipótese entrando em um pipeline de verificação. Em vez de confiar no caminho de raciocínio de um modelo, o sistema distribui a avaliação entre múltiplos modelos independentes que examinam a mesma afirmação de diferentes perspectivas, cada uma moldada por corpora de treinamento distintos, arquiteturas e preconceitos internos.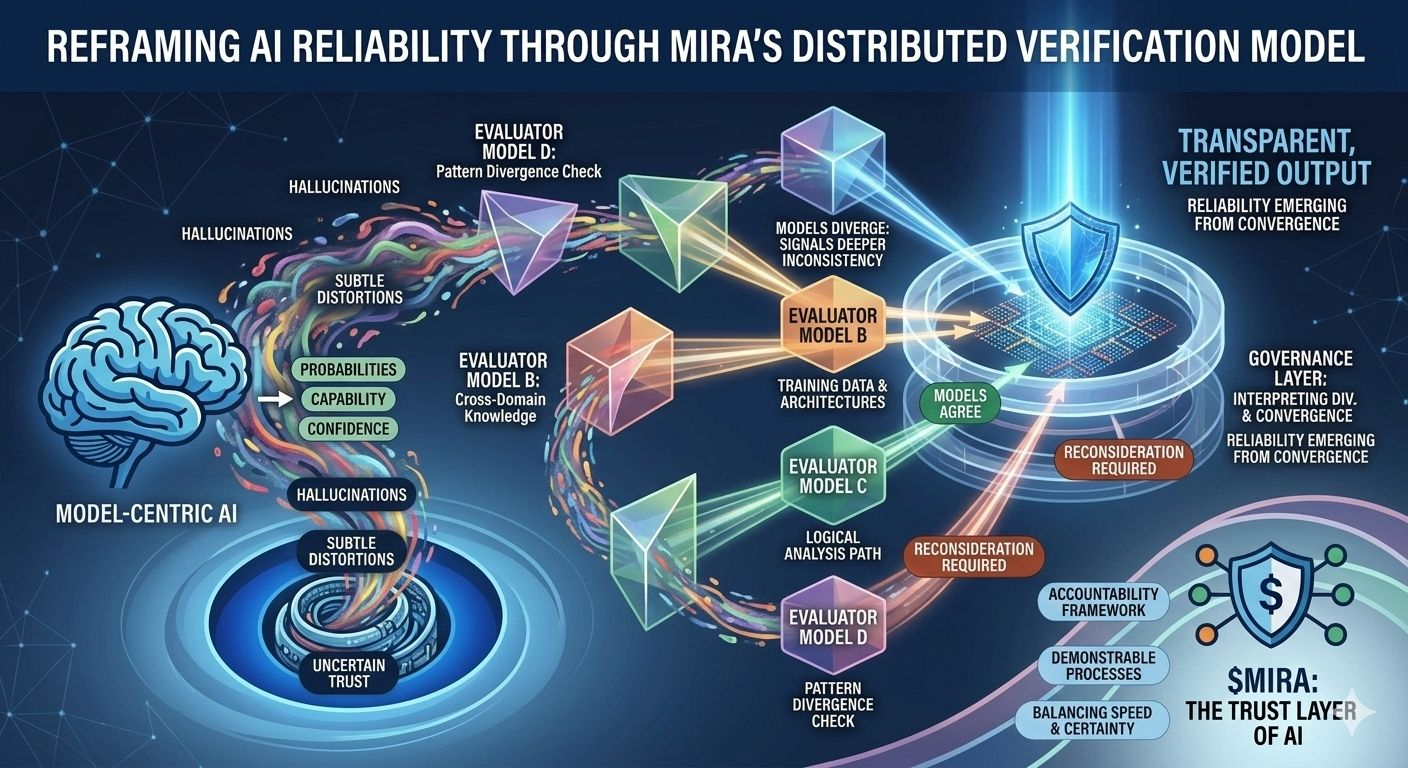
O que torna essa abordagem particularmente interessante é que o objetivo não é um acordo cego entre modelos. A simples votação da maioria ofereceria apenas uma segurança superficial, uma vez que modelos treinados em dados sobrepostos frequentemente herdam suposições e pontos cegos semelhantes. A estrutura de governança da Mira, em vez disso, foca em interpretar como os modelos concordam, onde divergem e se a discordância sinaliza uma inconsistência mais profunda dentro da própria afirmação. Em outras palavras, a confiabilidade surge não de respostas uniformes, mas da análise estruturada das diferenças no raciocínio.
Para tornar isso possível, as saídas complexas de IA devem primeiro ser divididas em componentes verificáveis menores. Um resumo de pesquisa gerado torna-se uma série de declarações rastreáveis, uma explicação legal se transforma em uma sequência de afirmações interpretativas, uma análise financeira se separa em afirmações quantificáveis que podem ser verificadas de forma independente. Cada um desses fragmentos pode então ser avaliado por modelos separados, permitindo que o sistema mapeie não apenas se a resposta geral parece correta, mas quais elementos específicos resistem ao escrutínio e quais requerem reconsideração.
Essa mudança pode parecer sutil, mas representa uma mudança profunda em onde a confiança reside dentro de um sistema de IA. Os pipelines tradicionais concentram autoridade dentro do próprio modelo: se o modelo se sai bem, o sistema se sai bem; se falha, todo o processo colapsa. A Mira distribui essa responsabilidade através de uma camada de governança que avalia as afirmações antes de se solidificarem em saídas. Nesse ambiente, a credibilidade não se origina da pontuação de confiança de um modelo, mas da convergência de caminhos de raciocínio avaliados independentemente.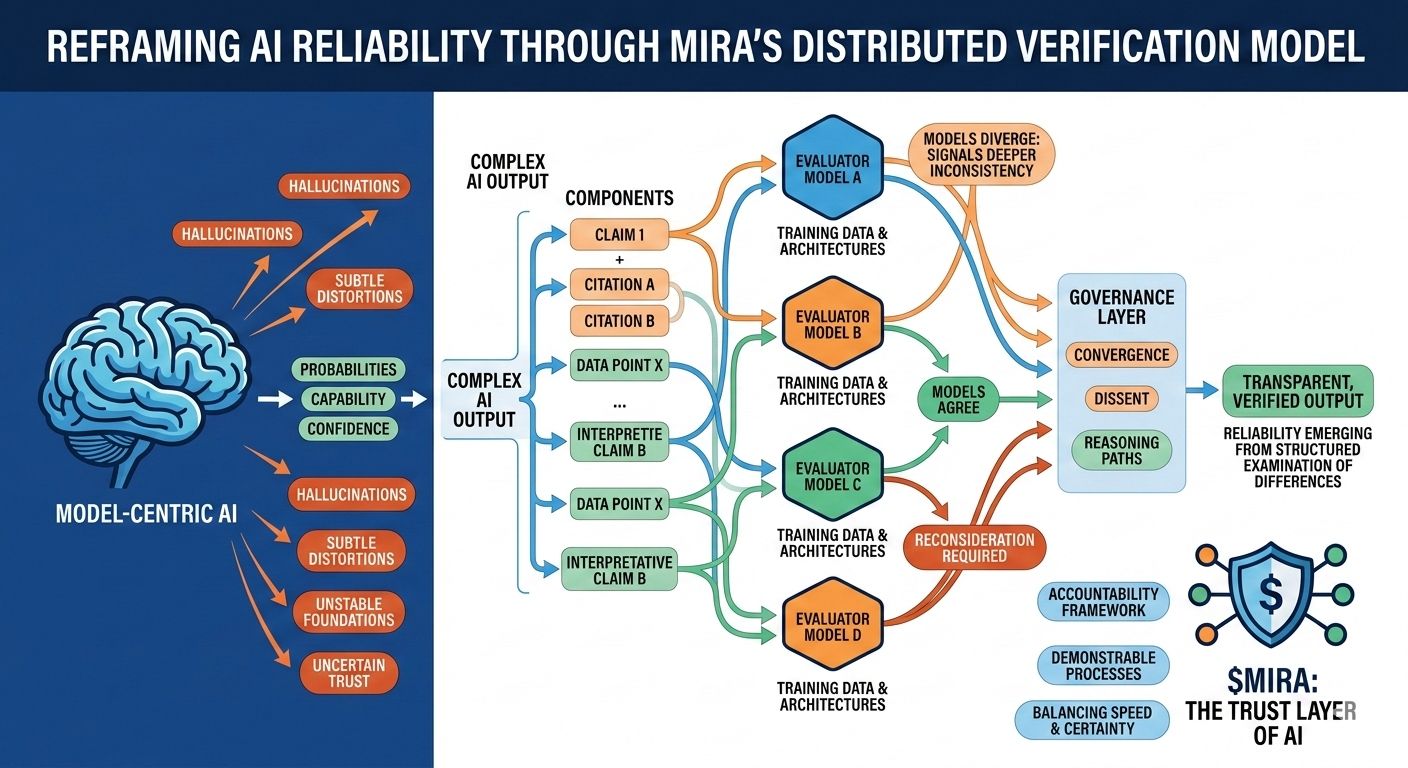
É claro que distribuir a verificação não elimina todas as formas de erro. Modelos treinados em conjuntos de dados semelhantes ainda podem reproduzir informações desatualizadas e solicitações adversariais sofisticadas podem explorar fraquezas sistêmicas compartilhadas entre arquiteturas. O consenso multi-modelo reduz a probabilidade de alucinações aleatórias, mas não pode prevenir completamente erros coordenados que surgem de suposições compartilhadas embutidas no ecossistema de IA mais amplo. Por essa razão, a transparência se torna tão essencial quanto a verificação em si. Os usuários devem entender se os modelos de verificação realmente representam perspectivas independentes ou meras variações do mesmo sistema subjacente.
Outra dimensão desse design reside em suas implicações econômicas. A verificação não é gratuita: cada chamada adicional de modelo introduz custo computacional, latência e complexidade de infraestrutura. À medida que os sistemas de IA integram cada vez mais camadas de verificação, os desenvolvedores devem fazer escolhas deliberadas sobre quando a validação profunda é necessária e quando respostas rápidas são suficientes. Aplicações construídas sobre IA verificada, portanto, evoluem para gerentes de confiabilidade, equilibrando constantemente velocidade, custo e certeza, enquanto determinam quais saídas requerem um escrutínio mais profundo ou supervisão humana.
Essas compensações provavelmente remodelarão como as plataformas de IA competem nos próximos anos. A capacidade sozinha não definirá mais os sistemas mais fortes. Em vez disso, a capacidade de demonstrar processos de verificação transparentes, comunicar claramente incertezas e expor graciosamente desacordos entre modelos pode se tornar as características definidoras de uma infraestrutura de IA confiável. Sistemas que reconhecem suas limitações enquanto contêm sistematicamente erros provarão ser mais valiosos do que aqueles que simplesmente projetam confiança.
Visto por essa perspectiva, o modelo da Mira é menos sobre construir modelos individuais mais inteligentes e mais sobre construir uma estrutura de responsabilidade em torno da inteligência de máquina. As respostas da IA tornam-se propostas em vez de declarações—afirmações que devem passar por uma rede de avaliadores independentes antes de serem aceitas como saídas credíveis. Em tal sistema, erros permanecem inevitáveis, mas seu impacto é contido por mecanismos de verificação que identificam fraquezas antes que elas se propaguem em decisões, sistemas financeiros ou discurso público.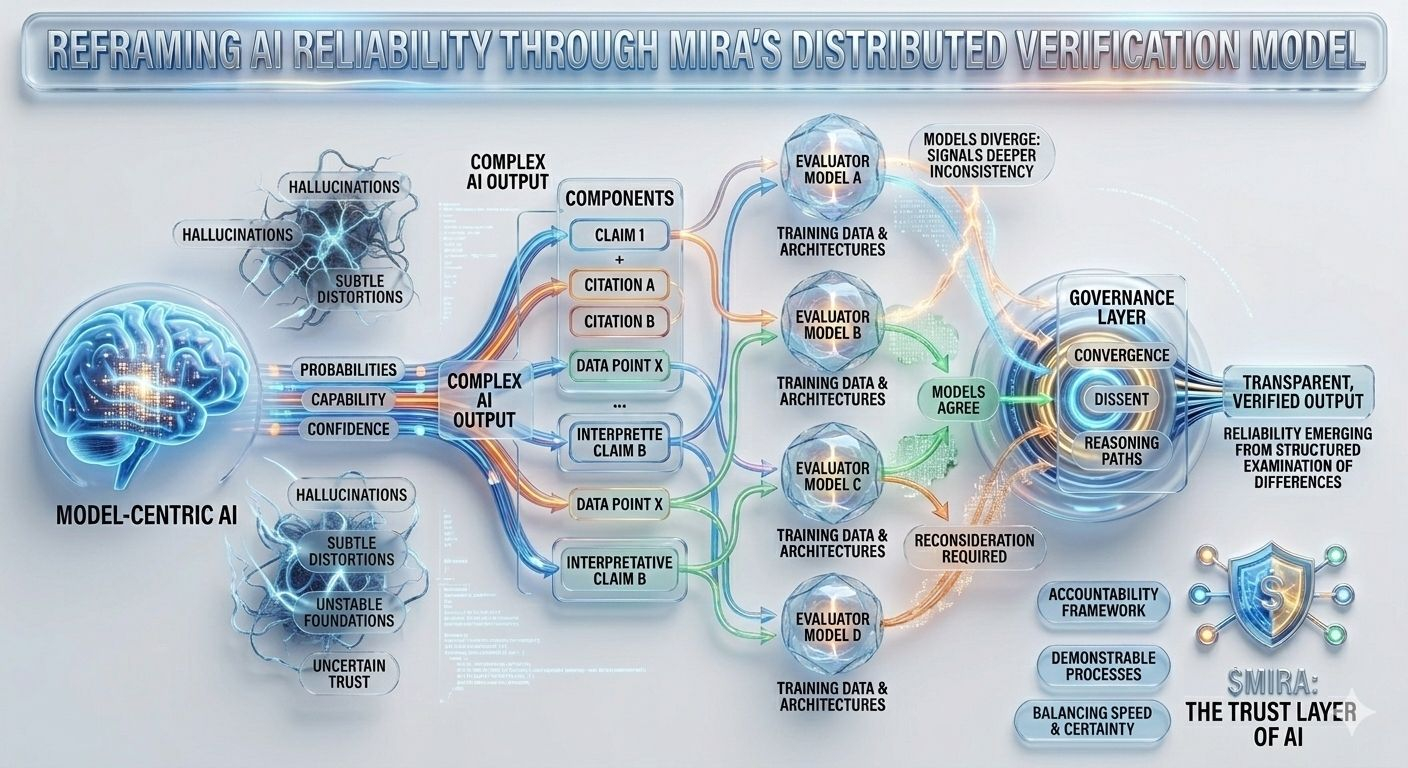
Em última análise, o futuro da IA confiável pode depender menos de alcançar um acordo perfeito entre modelos e mais de definir como esse acordo é interpretado, como sinais dissidentes são analisados e quais salvaguardas são ativadas quando o consenso começa a se fraturar. A verdadeira medida de confiança não será se as máquinas sempre produzem a resposta certa, mas se os sistemas que as cercam são projetados para questionar, testar e validar essas respostas antes que o mundo confie nelas.
$MIRA
