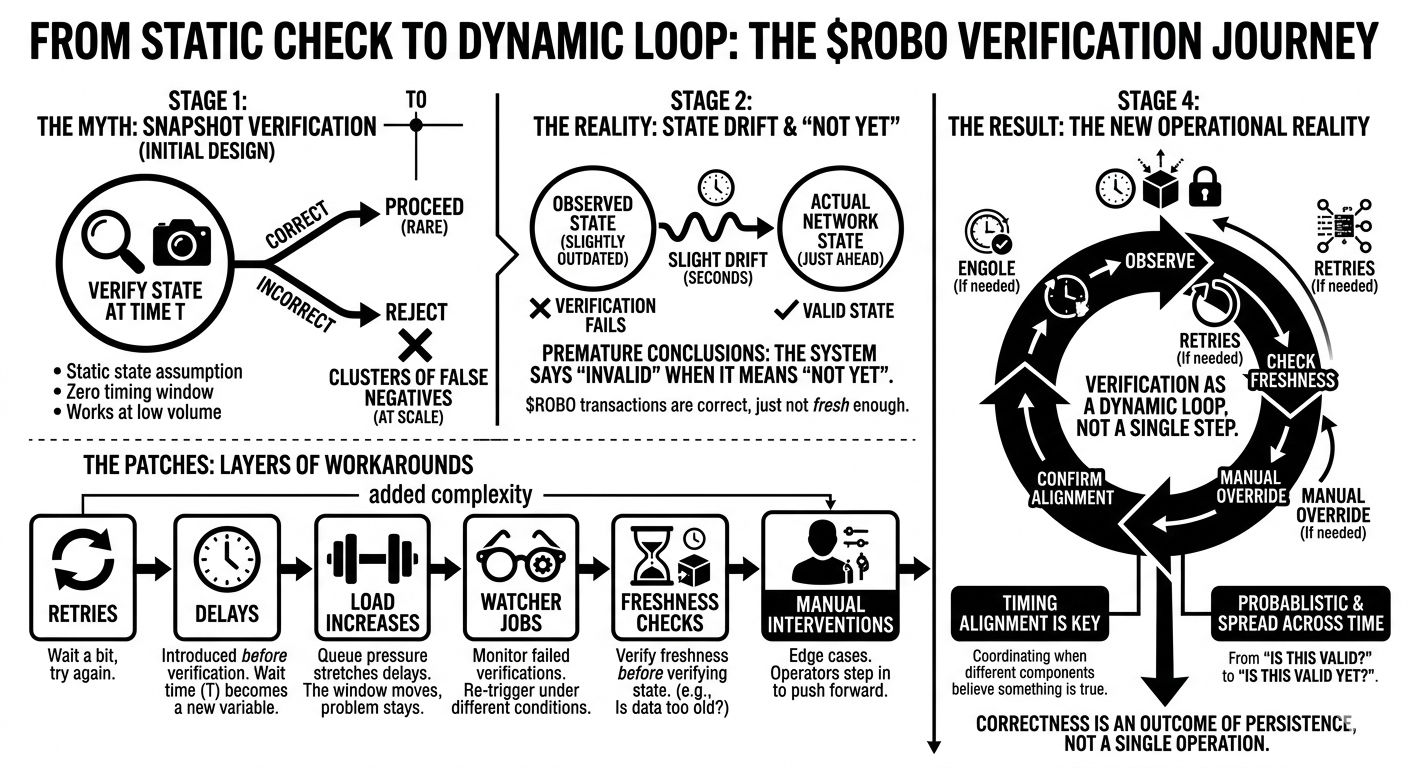
It showed up as a mismatch in a routine verification step.
Nothing dramatic. A worker picked up a task, checked the on-chain state, compared it with expected values, and flagged it as invalid. According to the logs, everything was working as designed.
But the state it rejected became valid a few seconds later.
That was the first hint.
The system assumed that verification was a snapshot operation. You read state, you validate, you move on. The underlying model treated state as if it were stable enough during that window.
In practice, it wasn’t.
We were verifying against something that was technically correct, but already outdated. Not stale in a traditional sense. Just slightly behind the actual progression of the network.
A few seconds of drift.
That’s all it took.
At low volume, this didn’t matter. Tasks would retry, succeed, and disappear. The inconsistency was absorbed without much noise.
At scale, it became visible.
We started seeing clusters of false negatives. Not errors, exactly. More like premature conclusions. The system was saying “invalid” when it really meant “not yet.”
So we added retries.
If verification fails, wait a bit, try again. That smoothed things out. Most tasks eventually passed. The system looked healthier.
But the underlying issue didn’t go away.
Because retries don’t fix freshness. They just delay the decision.
We added a small delay before verification. Just enough time for state to propagate and settle. That reduced the number of retries. It also introduced a new variable: how long is “enough”?
We didn’t have a clean answer.
So we tuned it empirically.
Then load increased.
Queue pressure started stretching those delays. Tasks sat longer before being processed. By the time verification happened, some states were fresh, others were already drifting again. The window moved, but the problem stayed.
We introduced watcher jobs.
They monitored failed verifications and re-triggered them under different conditions. Sometimes after a forced state refresh. Sometimes after a longer delay.
At this point, verification wasn’t a single step anymore.
It was a loop.
A loop with timing assumptions baked in.
We added freshness checks. Timestamps, block heights, “last updated” markers. If the data looked too old, we skipped verification and rescheduled. That helped avoid obvious mismatches.
But it also meant we were no longer verifying state directly.
We were verifying the freshness of state before verifying the state itself.
Two layers.
Then came manual checks.
Edge cases where automation couldn’t confidently decide. Operators would step in, inspect the state across multiple sources, and push the system forward. Not often, but enough to matter.
Those interventions weren’t part of the protocol.
But they were part of the system.
Over time, all these additions—retries, delays, watchers, freshness filters, manual overrides—started to look less like patches and more like structure.
They defined how the system actually behaved.
The original design said: verify state and proceed.
The real system said: wait, observe, retry, confirm freshness, then maybe proceed.
Different thing entirely.
What we’re really coordinating isn’t just state correctness.
It’s timing.
More specifically, alignment of when different parts of the system believe something is true.
In Fabric Foundation, Robo transactions don’t just need to be valid. They need to be observed at the right moment, by the right component, under the right timing conditions.
Otherwise, they fail. Temporarily. Quietly. Reversibly.
And we built layers to absorb that.
The uncomfortable realization is that verification is no longer a definitive check.
It’s a probabilistic one, spread across time.
We don’t ask “is this valid?”
We ask “is this valid yet?”
And the system keeps asking until it hears “yes.”
That works.
But it means correctness isn’t a property of a single operation anymore.
It’s an outcome of persistence.
And that’s a different kind of guarantee than we originally thought we were building.
$ROBO @Fabric Foundation #ROBO