Been going through the midnight network materials over the past couple days, mostly trying to understand where the zk layer actually sits in the execution model. at a surface level, the narrative is pretty clean: “confidential smart contracts using zero-knowledge proofs.” but honestly… that framing hides more than it reveals.
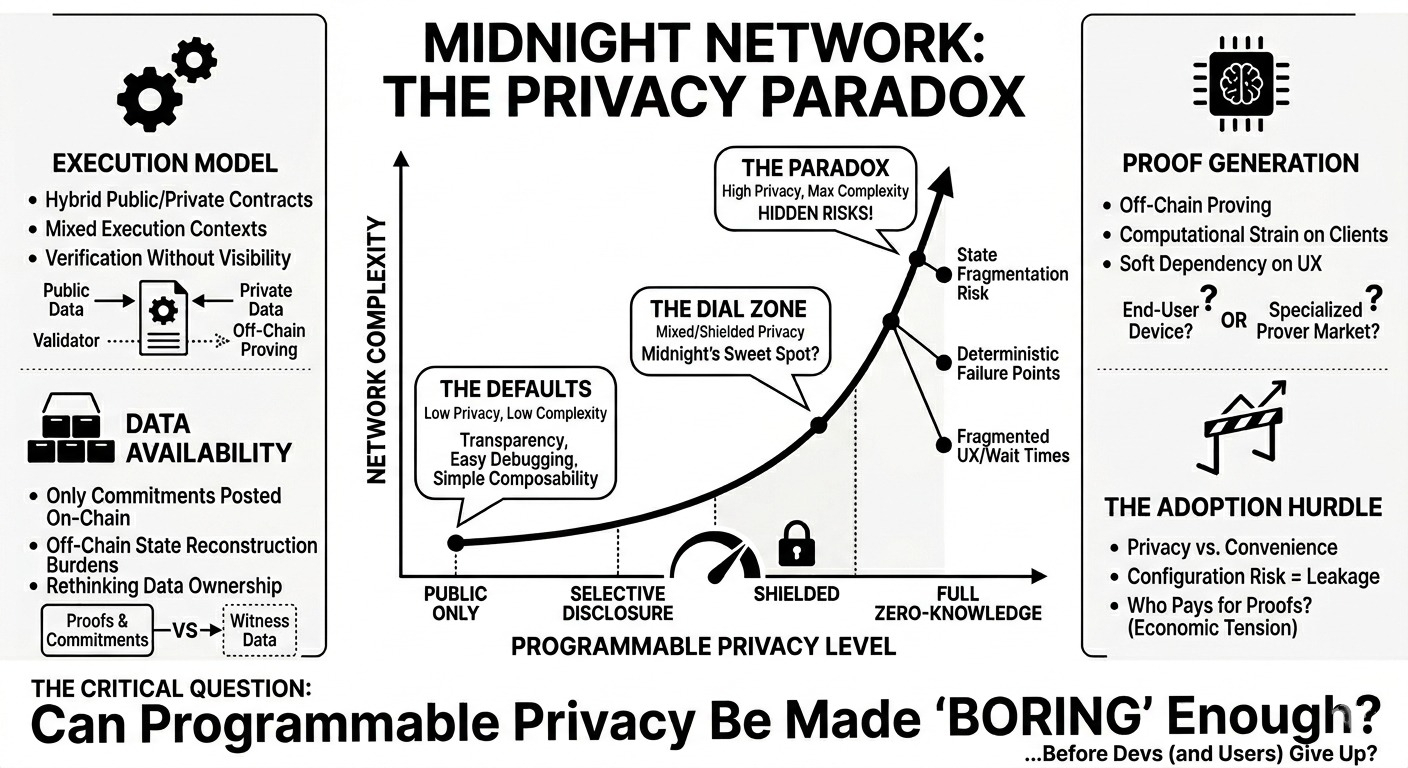
what most people seem to assume is that midnight is just another zk chain where everything is private by default. that’s not really accurate. it’s closer to a selective disclosure system where privacy is opt-in and programmable. the distinction matters, because it shifts complexity from the base layer into application logic and developer tooling.
a few components stood out to me:
first, the zk-enabled contract model itself. from what i can tell, midnight isn’t just wrapping transactions in proofs like a zk-rollup would. instead, contracts can define which parts of their state are shielded and which remain public. that’s interesting because it allows mixed execution contexts — some data verifiable on-chain, some proven off-chain. but it also raises questions about determinism. if parts of the state are hidden behind proofs, validators are essentially verifying correctness without visibility. that’s fine in theory, but debugging and composability start to get weird fast.
second, the role of “proof generation” off-chain. like most zk systems, proving is computationally heavy, so users or relayers generate proofs locally before submitting them. what caught my attention is that this introduces a soft dependency on client-side infrastructure. if proof generation isn’t standardized or optimized, you end up with fragmented UX or even centralization around specialized proving services. i haven’t seen a clear answer yet on whether midnight expects a market of provers or assumes end-user devices can handle it.
third, the data availability and interaction with the underlying network (since midnight is tied to the cardano ecosystem). there’s an implicit assumption that consensus and data availability layers remain robust enough to support these hybrid private/public transactions. but zk doesn’t eliminate the need for data availability — it just changes what data needs to be available. if only commitments or hashes are posted, then the burden shifts to off-chain actors to retain and reconstruct state when needed.
and here’s the thing — what’s not really discussed is how these pieces depend on each other in practice. selective disclosure only works if developers correctly specify what to hide and what to expose. that’s not trivial. a poorly designed contract could leak metadata even if the payload is private. similarly, the proving layer and the contract model are tightly coupled. if proving costs are high, developers will avoid using private state altogether, which undermines the whole premise.
there’s also an assumption that users care enough about data ownership to tolerate friction. maybe they do in certain verticals (identity, compliance-heavy finance), but in more general applications, privacy often loses to convenience unless it’s seamless.
on the risk side, timelines feel a bit fuzzy. zk systems tend to look clean in design docs but messy in production — especially when you introduce programmability. i’m not entirely sure how mature the tooling is for writing these mixed-visibility contracts. also, interoperability isn’t obvious. how does a midnight contract interact with a fully public contract on another chain without breaking its privacy guarantees? bridging private state sounds… non-trivial.
another tension is economic. if proof generation is expensive, who pays? users, developers, or some subsidized layer? if it’s users, adoption slows. if it’s subsidized, you need a sustainable incentive model.
i keep coming back to this: midnight is less about “making everything private” and more about giving developers a privacy dial. but dials introduce configuration risk.
watching:
* how developer tooling evolves (especially debugging for private state)
* whether a prover market emerges or if it stays client-side
* actual contract patterns — are people using privacy features or ignoring them?
* performance benchmarks once real workloads hit the network
not sure yet if this ends up being a niche system for specific use cases or something more general. i guess the real question is: can programmable privacy be made boring enough that developers actually use it correctly?
$NIGHT @MidnightNetwork #night