Já encontrei uma situação bastante frustrante ao usar o Web3: sendo o mesmo tipo de prova, mas este aplicativo a considera suficiente para abrir o acesso, enquanto outro aplicativo quase não sabe como lê-la.
Com o mesmo credencial, a mesma carteira, mas através de cada sistema, é necessário reinterpretar o que isso significa desde o começo.
Foi aí que comecei a olhar @SignOfficial
Inicialmente, eu também pensava que a Sign estava fazendo principalmente uma camada de atestação: registrar um fato na cadeia, e isso seria tudo. Mas, quanto mais eu leio, mais percebo que, se for entendido apenas assim, isso é um pouco insuficiente. Na minha visão, o que é mais notável é que eles estão tentando transformar a prova em algo legível por máquina desde o momento em que é criada, ou seja, não apenas armazená-la, mas também garantir que tenha estrutura suficiente para que outros sistemas possam ler, consultar e usar em sua lógica.
Esta é uma grande diferença.
Porque uma prova no Web3, se existir apenas como um registro isolado, seu valor é bastante limitado. Ela pode provar que algo aconteceu, mas não necessariamente ajudará outros sistemas a agir mais facilmente.
O novo aplicativo ainda terá que construir sua própria maneira de ler os dados, entender por conta própria o que essa reivindicação significa, e decidir como usá-la. O resultado é que a confiança ainda é fragmentada entre os sistemas, enquanto a prova continua a se parecer mais com um pedaço de papel de verificação do que uma unidade de dados viva dentro do software.
Na minha visão, a Sign está tentando levar a prova a um estado diferente.
O primeiro ponto que me faz ver assim é o schema.
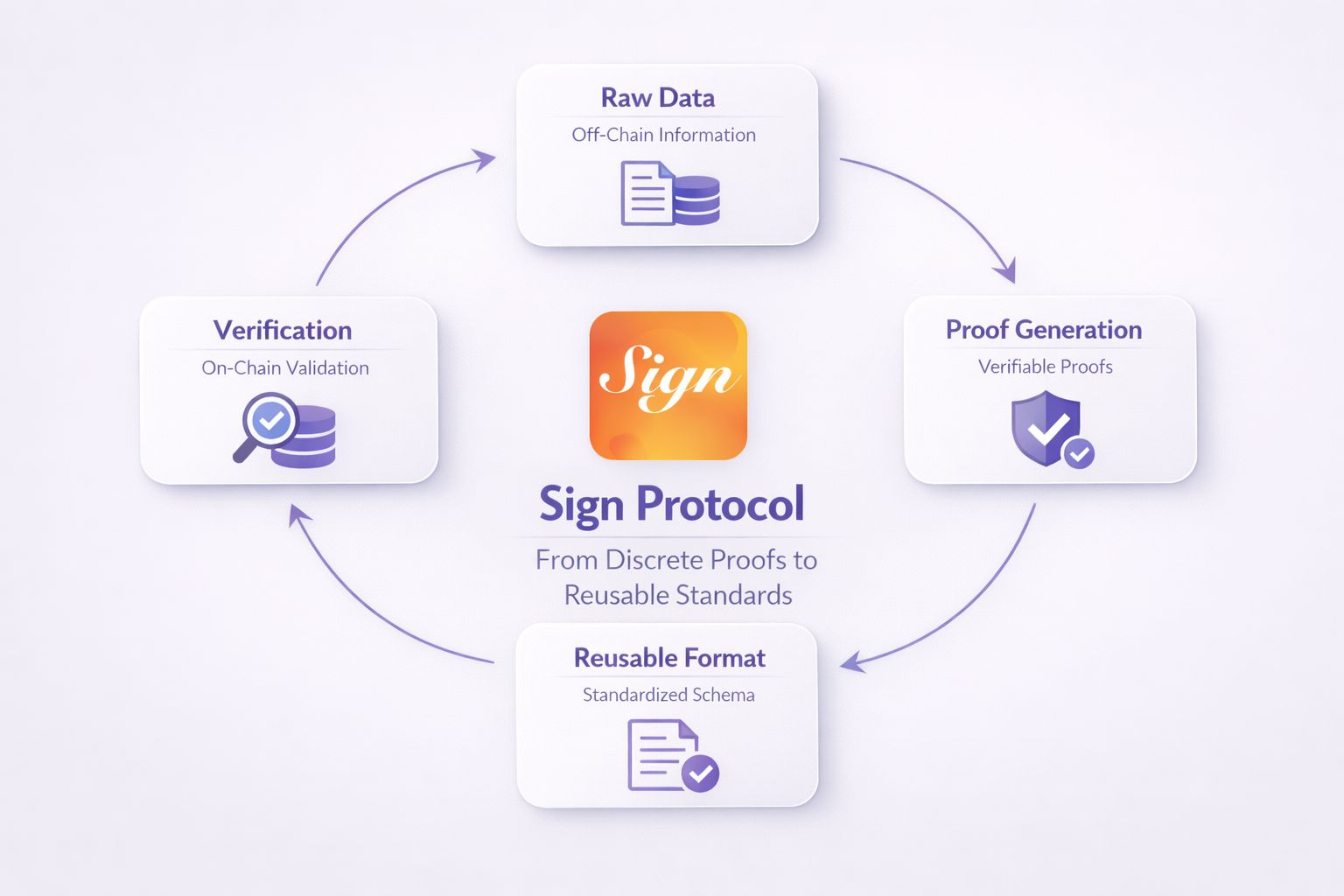
Se uma prova quer ser legível por máquina desde o momento de sua criação, não pode ser apenas um pedaço de dados aleatórios gravados na cadeia.
Ela precisa ser colocada em uma estrutura suficientemente clara: quais campos existem, que tipo de dados são usados, que lógica acompanha, qual é a validade, e se pode ser revogada ou não. Aqui é onde o schema da Sign se torna muito mais importante do que parece.
Acredito que muitas pessoas veem o schema apenas como uma questão de formato de dados organizado. Mas na verdade, o schema aqui está fazendo algo maior: está forçando a prova a ser gerada dentro de uma estrutura que a máquina possa entender de maneira consistente.
Na minha visão, este é o primeiro passo para que a prova não seja mais uma marca de verificação ambígua, mas se torne um objeto com um contexto claro dentro do sistema.
Nesse caso, outros aplicativos não precisarão adivinhar o que uma atestação está descrevendo. Eles podem ler a prova como ler uma estrutura que já foi padronizada anteriormente.
Aqui é onde vejo que a Sign vai muito além do tipo 'armazenar provas na cadeia'.
O segundo ponto que me faz ver que a Sign realmente está transformando a prova em algo legível por máquina são os schema hooks.
Esta é a parte muito valiosa no design deles. Se o schema ajuda a prova a ter um formato claro, então os hooks permitem adicionar lógica automática ao próprio momento em que a prova é criada ou revogada. Na minha visão, este é o momento em que a prova começa a se tornar algo que vive dentro do software, e não apenas um registro parado na cadeia.
Uma ferramenta de atestação comum pode registrar que 'isto é verdade.' Mas com os schema hooks, a Sign está permitindo que o sistema diga mais: 'e quando isso for registrado, então faça a próxima tarefa.'
É exatamente aí que se cria uma grande diferença.
Por exemplo, uma atestação de whitelist não é mais apenas a prova de que o usuário foi aceito. Ela pode também ativar simultaneamente o acesso. Uma prova de fundos não é apenas um registro de verificação financeira, mas pode ser acompanhada de lógica para abrir a participação em um produto específico.
Uma aprovação de atestação pode desencadear pagamento, controle de acesso ou um fluxo de trabalho seguinte sem precisar que outro aplicativo junte tudo desde o início.
Na minha visão, esta é a linha de demarcação entre a prova armazenada e a prova que é interpretada pela máquina desde o momento de sua criação.
O terceiro ponto é indexação e consultabilidade.
Uma prova pode ter um bom schema, mas se permanecer parada na cadeia, ainda não resolverá muito. Legível por máquina no sentido forte não significa apenas 'pode ser lido se você se esforçar para analisar'. Deve ser 'fácil de ler o suficiente para que outros aplicativos possam reutilizá-la sem ter que construir toda uma infraestrutura própria.'
A Sign parece entender muito bem esse ponto, então eles não param no schema e na atestação. Eles também estão impulsionando a parte de indexação, consulta e agregação.
Na minha visão, esta é a peça que faz com que a prova realmente entre no fluxo de trabalho do produto.
Porque os construtores lá fora não precisam apenas de um lugar para verificar se um fato foi registrado. Eles precisam de uma maneira de chamar aquela prova corretamente quando necessário, encontrá-la de acordo com um padrão comum, e usá-la como uma entrada na lógica de sua aplicação.
Se não houver essa camada, cada aplicativo ainda terá que construir sua própria lógica de verificação, indexar dados, e definir como consultar. E então, a prova, por mais bem estruturada que seja, ainda ficará presa em cada sistema separado.
Esta é a razão pela qual vejo que a Sign não está apenas padronizando dados, mas está tentando padronizar todo o fluxo no qual os dados são usados.
O quarto ponto que me faz ver que este argumento tem mais peso são as atestações cross-chain.
Se a prova é apenas legível por máquina em um aplicativo ou em uma única cadeia, então a história ainda é muito pequena. Na minha visão, a prova só vale realmente quando pode transitar entre muitos sistemas, mantendo seu significado de verificação.
E aqui está o ponto muito notável. Porque quando a prova é criada de acordo com um schema suficientemente claro, com lógica de hook, com indexação para consulta, e ainda há um fluxo para ser lido e usado em outros ambientes, a Sign não se parece mais com uma ferramenta que apenas registra fatos.
Começa a se assemelhar a uma camada de evidência, onde a prova gerada já possui estrutura para que outros sistemas possam entender e processar.
Acredito que esta é a razão pela qual muitas pessoas veem $SIGN
O mercado geralmente consegue ver campanhas, badges, airdrops ou whitelists mais facilmente. Essas coisas são realmente casos de uso fáceis de espalhar. Mas se olharmos de perto, a maior parte da tese está em outro lugar: a Sign está tentando transformar a prova de algo que é lido por humanos em algo que também é legível por máquinas desde o momento em que é criada.
Este é um grande avanço, pois se a prova for legível por máquina desde o início, a verificação não será mais uma ação manual repetida em cada aplicativo.
Começa a se tornar um ativo de dados que pode ser transportado, recuperado e utilizado novamente. E quando isso acontece, a confiança no Web3 também se torna muito menos fragmentada.
Mas aqui está a parte que quero dizer claramente: ir na direção certa não significa que o problema já foi resolvido.
Legível por máquina não significa automaticamente que todos os aplicativos serão acionáveis por máquina da mesma maneira. Uma prova pode ser criada de forma muito precisa, analisada de maneira muito bonita, consultada rapidamente, mas no final, cada aplicativo ainda pode estabelecer políticas próprias sobre até onde aceita essa prova.
Isso significa que a Sign está padronizando fortemente a gramática da prova. Quanto ao significado final da prova em cada produto, isso ainda dependerá da adoção e do efeito de rede.
Na minha visão, este é o verdadeiro teste deles.
Se um número suficiente de aplicativos começar a usar o mesmo schema, consultar a mesma camada de atestação, e permitir que as máquinas ajam com base nessas provas, então a Sign não será mais apenas um protocolo de atestação. Eles se tornarão uma verdadeira infraestrutura de evidência.
Portanto, se você me perguntar se o Sign Protocol está transformando a prova em algo legível por máquina desde o momento em que é criada, a resposta é: sim, e isso provavelmente é a parte mais ambiciosa no design deles.
Eles não querem apenas que a prova seja registrada. Eles querem que a prova gerada já tenha estrutura, contexto, capacidade de ser lida por máquinas, consultada e integrada a outros fluxos de trabalho. Na minha visão, isso é o que faz a Sign merecer ser vista como uma camada de infraestrutura de evidência em vez de uma ferramenta de verificação isolada.
Se eles conseguirem uma adoção suficiente para essa direção, o que a Sign está padronizando não será apenas dados. Será a maneira como o Web3 cria e usa provas desde o início.
@SignOfficial #SignDigitalSovereignInfra $SIGN