$SIGN #SignDigitalSovereignInfra @SignOfficial

I stopped trusting on-chain data the moment I actually tried to use it.
Not read it. Not admire it. Use it.
You pull logs, decode events, stitch timelines together and still end up asking the same question: what exactly am I looking at?
That’s the part nobody says out loud.
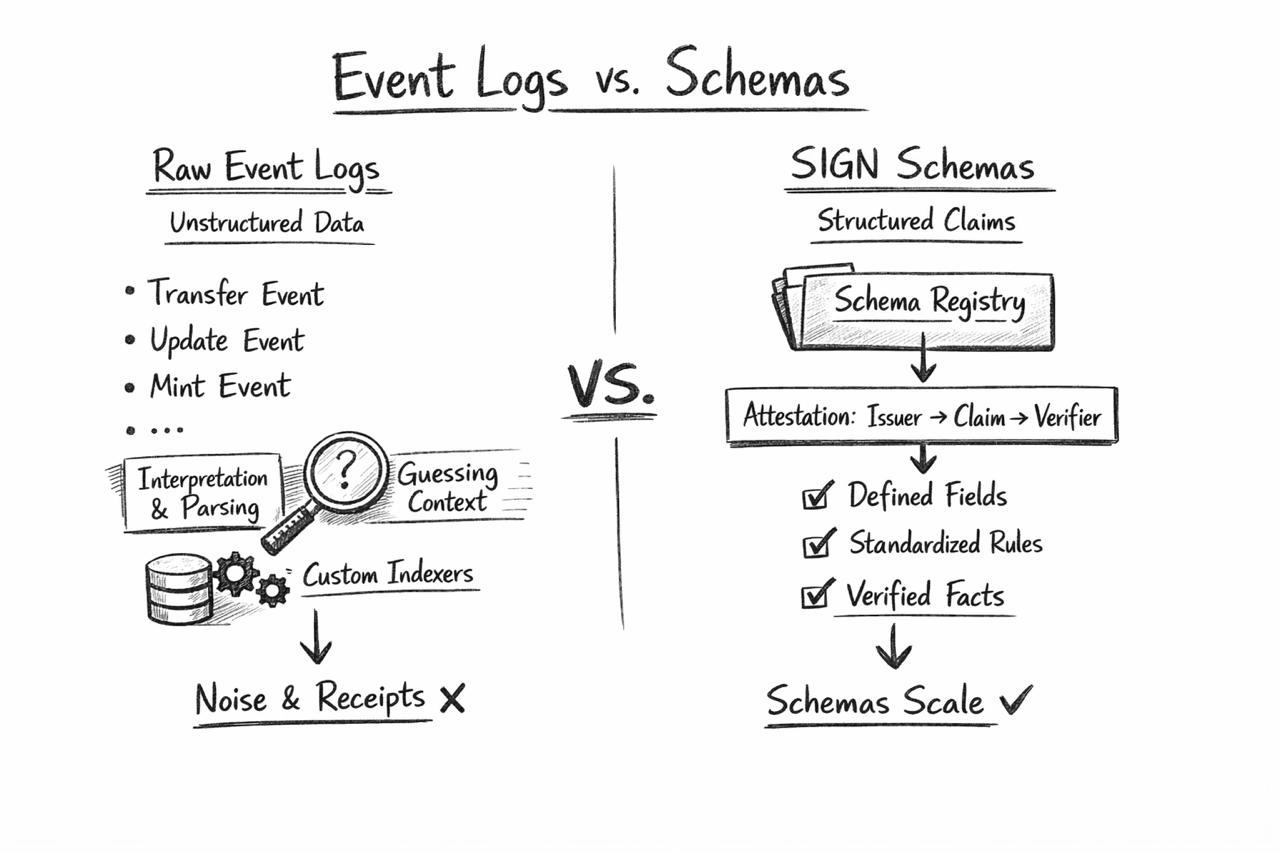
We’ve built an ecosystem obsessed with recording activity, but not defining meaning. And somewhere along the way, people convinced themselves that more logs equals more truth.
It doesn’t.
Logs are just receipts. And receipts don’t explain anything unless someone interprets them.
That worked when crypto was just transfers and swaps. It breaks the moment systems need to reason about identity, credentials, compliance anything that isn’t purely financial.
This is where I stopped looking at events as infrastructure.
And started looking at what @SignOfficial is actually doing with schema.
Because the difference is not cosmetic. It’s architectural.
SIGN doesn’t treat data as something to be decoded later. It forces structure at the moment a claim is created.
Through its schema registry, every attestation is tied to a predefined structure before it ever touches the chain. Not optional. Not inferred later. Defined upfront.
That changes everything.
Now the chain isn’t storing “something happened.”
It’s storing: this exact type of claim, with this structure, issued under this schema.
No guesswork. No reconstruction.
And once you see that, raw logs start to look like a dead-end abstraction.
Because logs scale in volume, not in meaning.
Schemas scale in understanding.
The part most people miss is how this plays out over time.
In a log-based system, meaning is always rebuilt downstream. Indexers interpret. Apps reinterpret. Different teams end up with slightly different conclusions from the same data.
You don’t notice it at small scale.
At system scale, it becomes fragmentation.
SIGN avoids that by locking meaning at the source.
The attestation lifecycle is not just “write and read.” It’s structured from the start:
an issuer creates a claim under a schema → the claim carries its structure on-chain → a verifier later executes against that same structure without redefining it.
No translation layer in the middle.
That’s the shift.
Interpretation is no longer a repeated cost. It’s eliminated.
And that’s where dominance starts to show.
Let me put it in a way that’s harder to ignore:
If your system relies on logs, you are rebuilding meaning every time you read data.
If your system relies on schemas, meaning is already there.
That’s not a design preference. That’s a difference in computational overhead, reliability, and interoperability.
And most current systems are still stuck in the first model.
Take something real.
A user completes a certification.
In a log-based setup, you’ll see events: course completed, token minted, maybe a flag updated somewhere. Another system later tries to interpret those signals and decide if the user qualifies for access.
It works, until it doesn’t.
Because every verifier is effectively guessing what combination of events equals “valid certification.”
With SIGN, the certification itself is an attestation defined by a schema in the registry.
Issuer signs it. Structure is fixed. Fields are known.
When a verifier checks it later, they’re not piecing together history.
They’re evaluating a claim.
That’s cleaner. But more importantly, it’s machine-executable without interpretation.
Same story with compliance.
Right now, most “on-chain compliance” is just off-chain decisions awkwardly mirrored on-chain.
It’s brittle. Not reusable.
In SIGN, compliance becomes a structured claim.
A schema defines what “KYC passed” actually means fields, issuer, validity.
The issuer attests.
Now any protocol doesn’t need to rerun checks or trust a black box.
They verify the claim through the issuer–verifier flow already defined by the schema.
No duplication. No re-interpretation.
You’re not sharing user data.
You’re sharing validated facts.
And that’s a completely different primitive.
Here’s the uncomfortable part.
Most of Web3 infra exists because logs don’t carry enough meaning.
Indexers. Custom parsers. Data pipelines. Half of it is just trying to answer: what does this data actually mean?
Schemas remove that question entirely.
And once that clicks, it’s hard to justify the old model.
Because you realize:
we didn’t need more data pipelines.
we needed better data structures.
What SIGN is doing with schema-first design is forcing that realization early.
Not letting apps define meaning loosely.
Not letting interpretation drift across ecosystems.
But anchoring claims to a shared structure that machines can execute against without hesitation.
That’s not just cleaner architecture.
That’s coordination at the data layer.
Because the moment two systems use the same schema, they don’t need adapters anymore.
They already agree on what a claim is.
So no, this isn’t about “better logs.”
It’s about abandoning the idea that logs were ever enough.
Because they weren’t built for machines to reason over.
They were built to record actions.
And we’ve been stretching them far beyond that.
Schemas don’t stretch.
They define.
And once you start working with systems that don’t need to reinterpret their own data…
you stop going back.
Not because it’s nicer.
Because anything else starts to feel broken.