
What kept bothering me with SIGN was not the reading side. It was the moment a claim gets admitted. A lot of systems look disciplined because every record is structured, signed, and easy to query. Then you look closer and realize the expensive failure starts earlier. The real risk is not only whether a claim can be stored cleanly. It is whether a claim that should have been stopped gets written cleanly enough to move through the rest of the workflow.
That was the point that changed the way I looked at Sign. A builder can define the schema, but the harder question is who gets to write into that lane and what happens when they should not. Sign's hook design matters here more than the easy attestation narrative. Hooks can run custom logic during creation or revocation, enforce attester controls like whitelists, and revert the whole call when the rule is violated. That means the trust layer can try to kill the bad fact before it ever becomes usable evidence.
The failure scene I keep coming back to is simple. An unauthorized partner submits a structurally valid attestation into a lane that downstream systems already treat as trusted evidence. The schema matches. The record lands. TokenTable consumes it for eligibility. Then a payout reviewer has to stop the flow and prove something that should have been settled before creation: this writer was never supposed to have issuance rights in the first place. By then the problem is no longer bad formatting or missing proof. The problem is that a bad fact entered the lane cleanly enough to contaminate later decisions.

That is why write-lane pollution feels worse to me than bad data. Bad data often announces itself. This does not. The record can look orderly, signed, and fully compatible with the schema. The hook was supposed to narrow the lane. The revert was supposed to stop the call. If that admission boundary stays loose, later operators are not using a trust layer. They are doing correction work inside something that still looks official.
What made SIGN feel more serious to me is that the stack does not pretend raw structure is enough. The useful project-native detail is not just schemas existing. It is that builders are given a place to enforce attester control before a record gets to live, and a failed rule can revert the whole transaction. That is a much more honest answer to the real bottleneck than acting like every properly formatted claim deserves space on the same evidence surface.
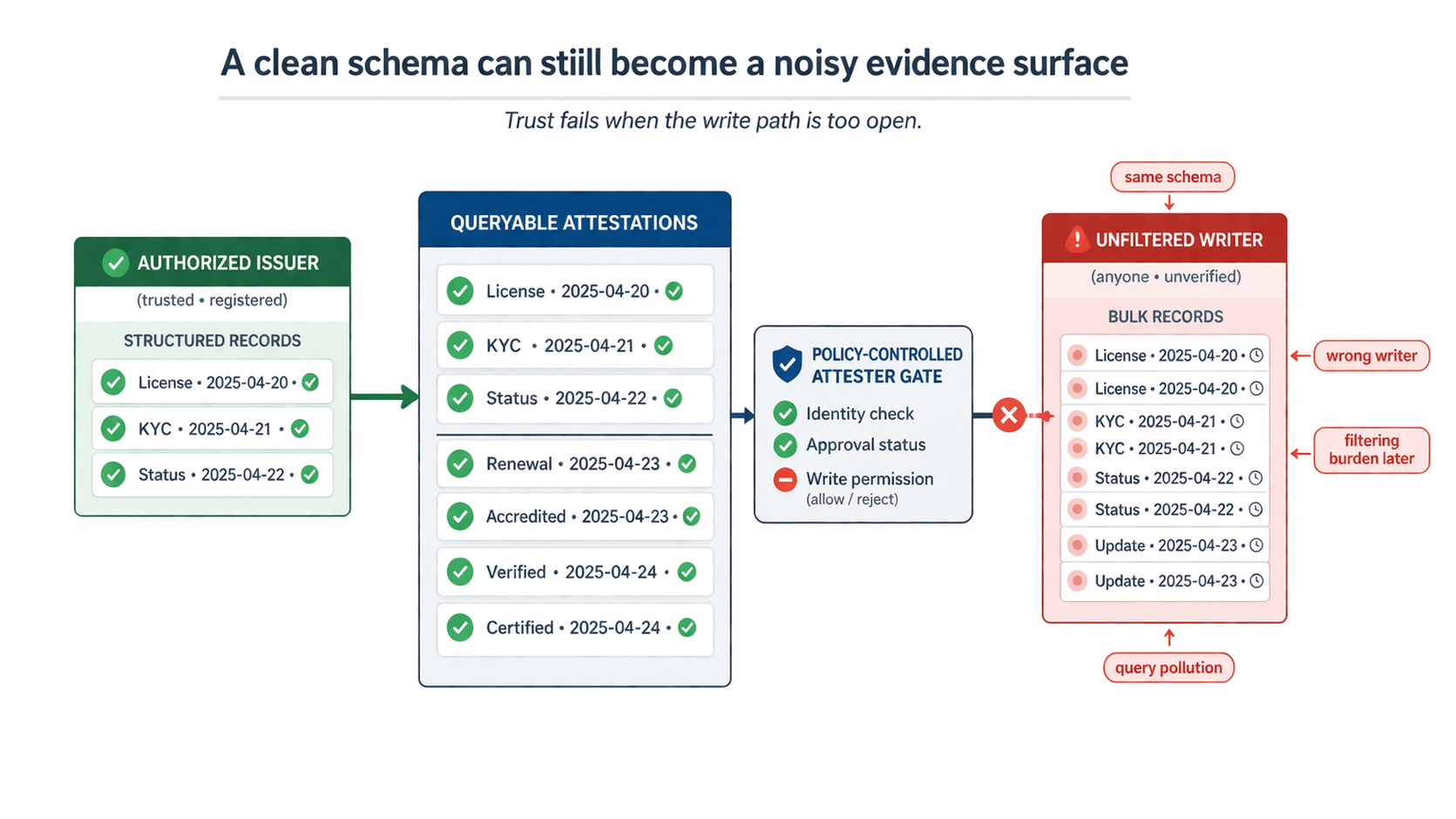
Once I saw that, the hard problem stopped looking like "how do we prove more things?" and started looking like "how do we keep the wrong writer from producing a valid-looking fact that downstream systems have to unwind later?" That is a smaller question, but it feels much more valuable. Plenty of systems can store claims. Far fewer can keep the write path narrow enough that later consumption still means something.
When polluted write lanes are cleaned too late, every correction, replay, and audit inherits the load, and that repeated burden is the first place $SIGN starts to feel mechanically relevant to me.
I am still watching the hard part. Do builders actually keep the attester lane tight with hooks, or does convenience slowly widen who can issue into the same schema? When more partners join one workflow, does TokenTable keep consuming clean evidence, or does it start inheriting records that only look trustworthy because rejection happened too late? That is the pressure point I care about most.
Because the trust layer does not usually break when a false claim gets rejected.
It breaks when the wrong writer is allowed to create a valid-looking claim before anyone stops it.
#SignDigitalSovereignInfra $SIGN @SignOfficial
