I'll be honest — when I first heard about another "data infrastructure for AI" project, my eyes glazed over. Been in crypto since 2021 and Ive seen maybe fifty projects promise to fix data provenance. Most of them are just oracles with a facelift and a better whitepaper design.
but last week I actually sat down with OpenLedger's material. Not the glossy stuff — the actual technical breakdown. And yeah, I was wrong to sleep on this.
Here's the problem nobody's talking about loudly enough: AI models are trained on garbage data, and nobody can prove it. You think that LLM is smart? It might've been trained on Reddit arguments, pirated books, and synthetic data loops. And the people selling you "AI-powered trading" have zero clue where their model's answers actually come from.
That's terrifying if you're putting real money behind an AI agent.
What OpenLedger actually does
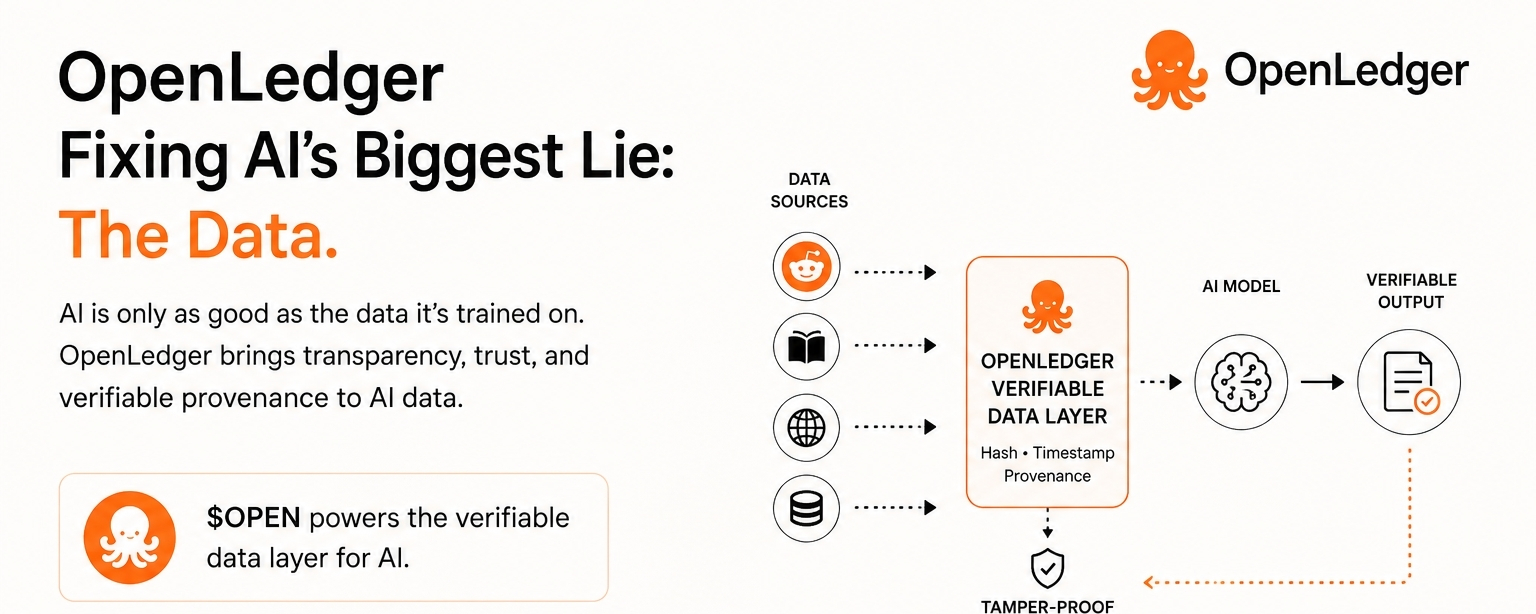
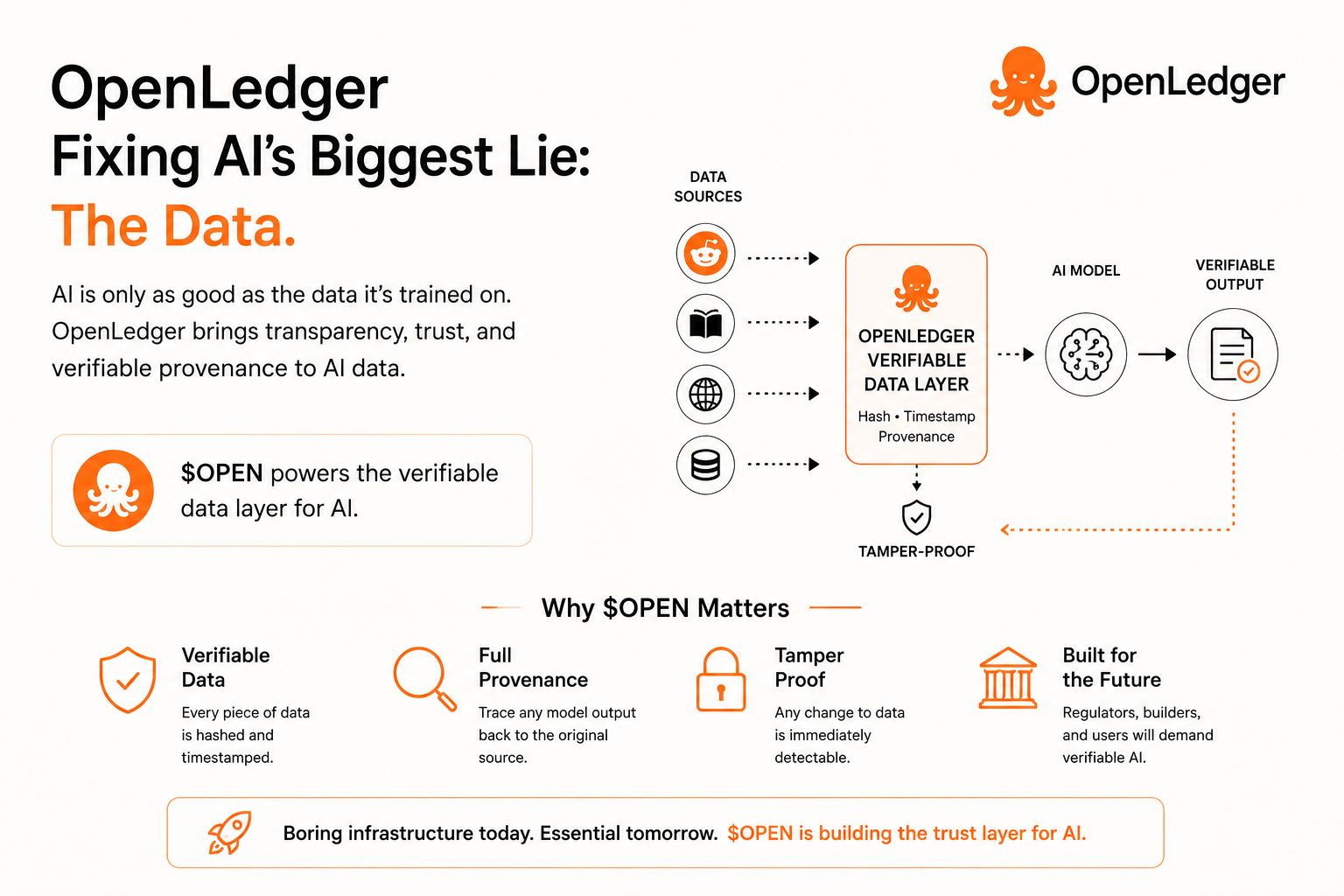
Instead of just saying "we bring data on-chain" (boring, done a thousand times), OpenLedger is building a verifiable data layer specifically for AI models. That means:
· Every piece of training data gets hashed and timestamped
· You can trace any model output back to its original data source
· Tampering becomes immediately obvious
Sounds simple. It's not. Doing this at scale without turning inference into a slow, expensive disaster is genuinely hard engineering.
Why OPEN is different from the noise
Most tokens in this space have zero reason to exist — they're just fundraising vehicles. $OPEN actually has a shot at capturing value because verification isn't optional. If you're building an AI agent for DeFi, healthcare, or anything that touches real money, you need provable data lineage. Regulators will demand it. Users will demand it.
My personal take? This is one of those "boring infrastructure" plays that suddenly becomes essential when the next big AI disaster happens. Remember when a trading algorithm went rogue because someone fed it bad data? That's going to happen again. And the projects that can prove their data is clean will be the only ones left standing.
Full disclosure — I screwed up before
I made a stupid trading mistake earlier this year. Bought into a "decentralized AI compute" project without checking if they even had a working data verification layer. Read the hype, ignored the gaps. Got rugged (politely — slow bleed, not a flash crash). Lost about 30% of that bag before I cut my losses.
Not making that same mistake with OPEN. I'm not saying ap into anything. I'm saying: do the homework, and when you do, you'll see why OpenLedger is solving a real problem instead of just naming a token after a buzzword.
Where I think this goes
If @OpenLedger executes — and that's always the real bet in crypto — we could see Open become the default standard for AI data verification. Not because of marketing, but because every serious AI project will realize they can't afford not to use it.
It's early. Like, really early. But that's also when the real gems actually get built, before the hype train shows up with the "in conclusion" crowd.