

Certo, então... Eu continuo travando na palavra "qualidade" com @OpenLedger .
Não porque está errado.
Porque soa muito tranquila. Na verdade...
Qualidade parece tranquila até eu imaginar a aba de validação aberta às 2 da manhã, uma linha do OpenLedger Datanet marcada, e ninguém certo se é ruído ou a única coisa útil e feia do lote.
O pessoal diz que uma IA melhor precisa de dados melhores, como se essa frase resolvesse algo. Dados melhores. Dados mais limpos. Dados verificados. Dados específicos de domínio. Legal. Maravilhoso. Agora coloque essa frase dentro de um Datanet e peça para alguém decidir o que realmente merece treinar um modelo.
É aí que a versão legal começa a suar.
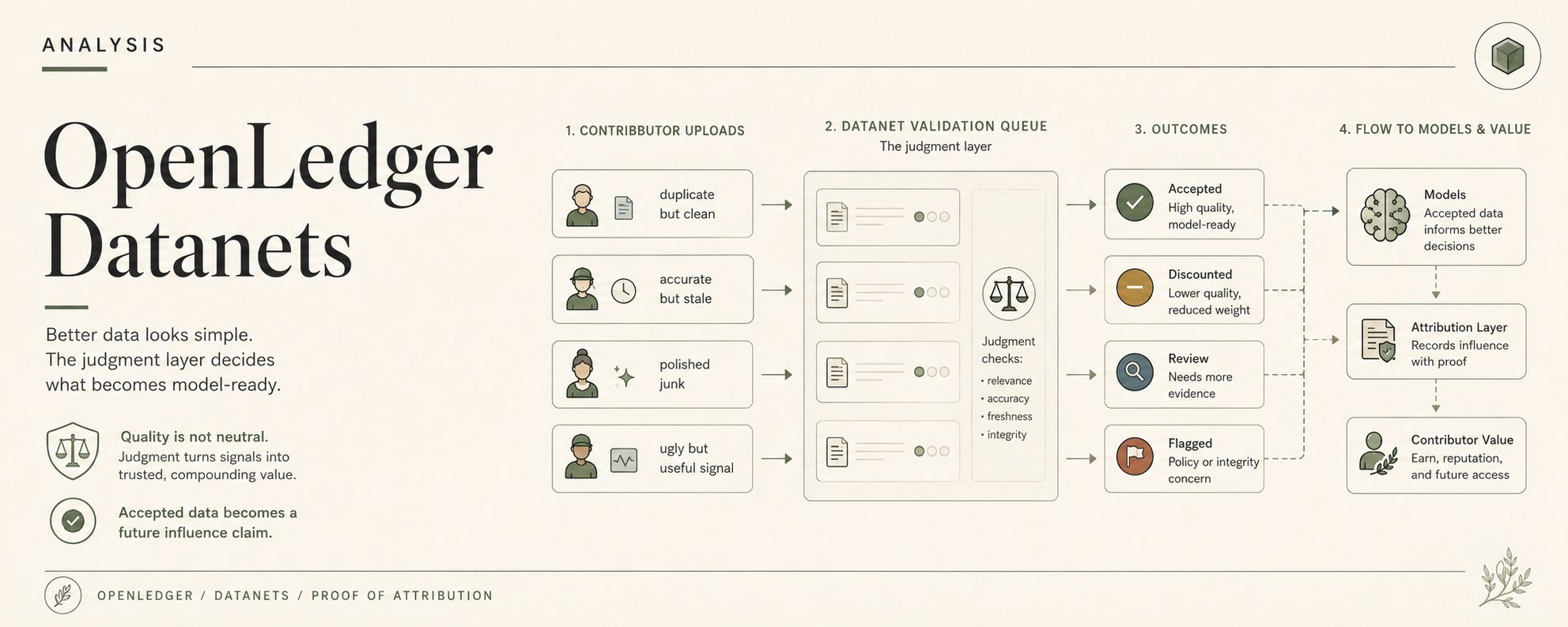
Um Datanet não é apenas uma pasta com ambição no OpenLedger. Ele coleta dados de domínio, sim, mas então as partes feias começam. Validação. Histórico de contribuição. Reputação do contribuinte. A questão de saber se esta linha deve chegar ao treinamento, recuperação, ajuste fino ou inferência posterior.
Isso soa prático.
É prático.
Esse é o problema.
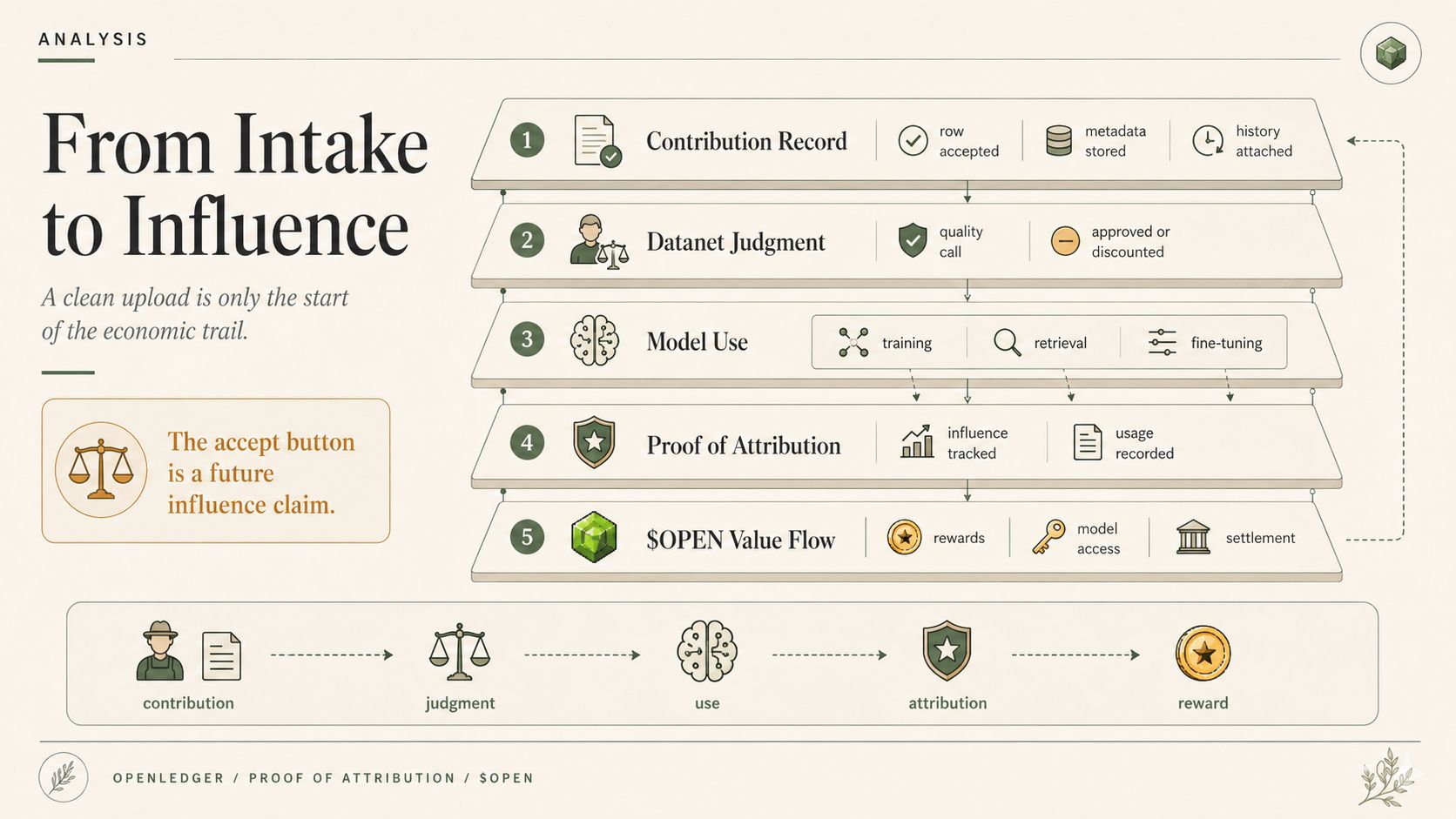
Porque uma vez que os dados se tornam utilizáveis, o OpenLedger tem que parar de tratá-los como um arquivo e começar a tratá-los como uma futura reivindicação de influência.
Não no sentido fofo da comunidade.
No sentido de "esta contribuição pode moldar o comportamento do modelo e talvez ganhar através da Prova de Atribuição mais tarde."
Humor diferente.
de qualquer forma.
Eu fico imaginando um Datanet construído para dados de risco DeFi. Contribuintes começam a enviar notas de incidentes de protocolo, histórico de liquidações, rótulos de exploração, casos de dívida ruim, exemplos de estresse de mercado, registros de falha de oráculo, talvez anotações de risco de governança se todos quiserem sofrer adequadamente. Os uploads parecem úteis. Metadados limpos o suficiente. Categorias preenchidas. Timestamps lá. Talvez uma linha de reputação do contribuinte já sentada ao lado da submissão como uma ameaça silenciosa.
A fila de validação faz aquela coisinha que os dashboards fazem. Campos verdes, verificações pendentes, um aviso que ninguém quer clicar porque clicar significa que o dia fica mais longo.
Bom.
Agora classifique.
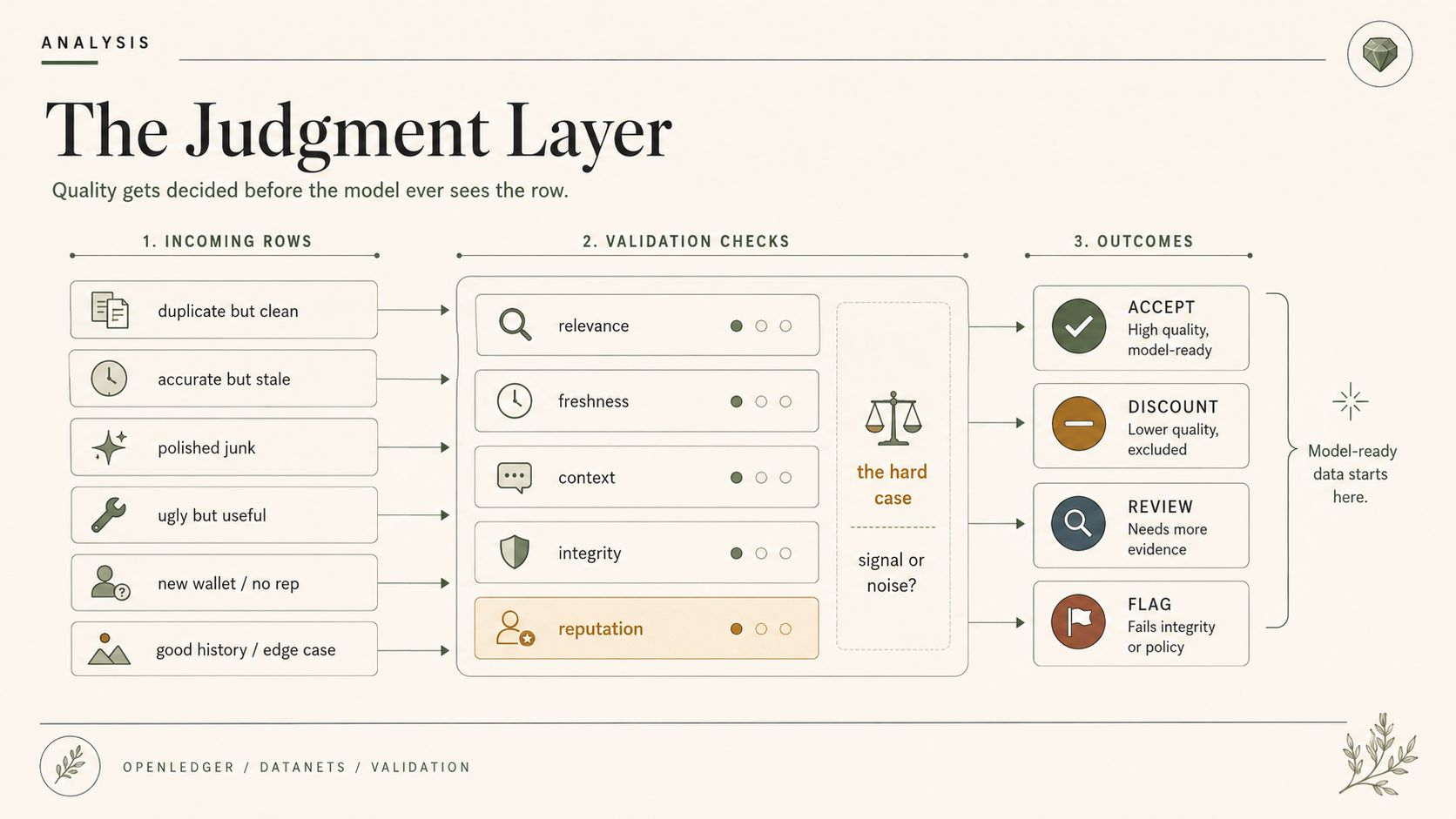
Não filosoficamente. No fluxo de contribuição do Datanet do OpenLedger. Aceitar, descontar, sinalizar, penalizar, roteirizar para revisão, talvez deixar a reputação inclinar a primeira leitura. Tudo muito limpo até que uma única submissão feia seja a única que realmente capturou o verdadeiro caso de borda.
Uma entrada é útil, mas duplicada. Uma é precisa, mas desatualizada. Uma é tecnicamente correta, mas falta o contexto de mercado que tornou o evento importante. Uma parece polida e é basicamente lixo com melhor formatação. Uma tem sinal real enterrado sob anotações feias. Uma veio de um contribuinte com um bom histórico. Outra veio de uma nova carteira sem trilha de reputação. Bom. Ótimo até. Dados melhores, aparentemente. Bom dia.
Essa é a pressão do Datanet sobre as pessoas do OpenLedger se achatar muito rapidamente.
OpenLedger está tentando evitar a bagunça usual da IA onde os modelos consomem metade da internet e ninguém sabe o que entrou neles. Os Datanets empurram na direção oposta: dados mais estreitos, origem mais forte, mais responsabilidade dos contribuintes, caminhos de uso mais limpos. Isso é útil.
Mas dados mais estreitos também tornam o julgamento mais afiado.
Porque uma raspagem geral pode esconder entradas ruins no pântano. Um Datanet não pode esconder tão facilmente. Se o Datanet deve alimentar um modelo especializado, então cada contribuição aceita começa a parecer mais responsável. Não moralmente. Operacionalmente. O modelo pode treinar com isso. Um fluxo de trabalho da OpenLedger ModelFactory pode selecioná-lo. Um adaptador OpenLoRA pode mais tarde se especializar em torno de saídas moldadas por isso. A Prova de Atribuição pode eventualmente conectar esses dados ao valor.
O que significa que o botão de aceitação não está apenas dizendo "bom o suficiente para o conjunto de dados." Ele está silenciosamente criando uma possível reivindicação futura sobre influência.
Tudo bem.
Algum construtor na ModelFactory não vê todo o argumento também. Eles veem um conjunto de dados aprovado, talvez um rótulo do Datanet, talvez confiança suficiente para clicar em frente. Adorável. A luta da entrada acabou de se tornar material de treinamento.
Então, o passo de validação no OpenLedger deixa de ser administrativo.
Começa a parecer comportamento de modelo antes mesmo do modelo ser executado.
Essa parte me incomoda.
Eu vi esse clima em salas de dados. Ninguém diz "estamos moldando os erros futuros do modelo." Eles dizem "esta linha está mais limpa," e de alguma forma isso soa responsável o suficiente.
Um contribuinte pensa que está enviando dados. O Datanet está na verdade decidindo se aqueles dados merecem se tornar parte do espaço de resposta futura. Isso soa dramático. Não é. É apenas o que acontece quando os dados não são mais armazenamento morto.
Se uma má submissão é rejeitada, tudo bem. Fácil.
Se uma submissão maliciosa é penalizada, tudo bem. Mais limpo.
Os casos mais difíceis são os normais. Dados que são meio úteis. Dados que são úteis apenas em um contexto estreito. Dados que repetem um padrão existente, mas o confirmam bem. Dados que conflitam com outra fonte e forçam o Datanet do OpenLedger a escolher qual versão se torna "pronta para o modelo." Isso não é coleta de lixo. Isso é curadoria com consequências econômicas.
E no OpenLedger, essas consequências não ficam apenas na tela de upload.
Essa é a parte que faz o Datanet parecer mais pesado.
Um registro de contribuição pode seguir o contribuinte. A reputação pode moldar como futuras submissões são tratadas. A Prova de Atribuição pode decidir mais tarde se os dados aceitos influenciaram uma inferência. ... pode depois passar por uso, recompensas, acesso ao modelo, gás e liquidação como se a decisão de entrada fosse óbvia o tempo todo. Portanto, quando um Datanet aceita ou desconta dados, não está apenas limpando um conjunto de dados. Está moldando silenciosamente quem será confiável mais tarde, quem será pago mais tarde e qual versão da realidade o modelo pode aprender.
Uma maquininha de ordenação legal.
Muito democrático até que a linha rejeitada pertencesse a você.
Eu já sei a resposta limpa. Governança comunitária. Fluxos de validação. Reputação do contribuinte. Lógica de penalidade. Histórico de contribuição no OpenLedger. Sim. Tudo bem. Máquinas necessárias. Sem isso, os Datanets se tornam fazendas de upload com marcação de IA colada na porta.
Ainda.
Essas mesmas ferramentas criam outra camada de poder.
Porque o controle de qualidade não é neutro uma vez que recompensas existem. Se os contribuintes sabem que os Datanets recompensam influência útil mais tarde, eles começam a otimizar para aceitação. Eles formatam mais limpo. Imitam exemplos aprovados. Evitam casos de borda estranhos porque casos de borda estranhos parecem arriscados. Eles enviam dados que parecem prontos para o modelo em vez de dados que capturam a verdade feia do domínio.
É aí que a qualidade começa a ficar estranha.
O Datanet pode ficar mais limpo e menos honesto ao mesmo tempo.
Nem sempre. Não automaticamente. Mas o suficiente para me fazer olhar para a camada de validação mais tempo do que para o botão de upload.
E sim, eu odeio que é aqui que eu acabo. Não no modelo. Não no agente. Na linha de entrada. Um trabalho muito glamouroso, olhando para uma linha e me perguntando se isso se torna a resposta futura de alguém.
Um domínio real é bagunçado. Incidentes de DeFi não chegam com rótulos limpos. Dados de saúde não chegam sem ressalvas. Dados legais não chegam sem sujeira jurisdicional. O comportamento de mercado não se encaixa perfeitamente porque os mercados são principalmente humanos criando bobagens caras em sequência. Se o Datanet recompensa contribuições limpas, reutilizáveis e facilmente validadas de forma muito agressiva, os dados ruins, mas importantes, começam a parecer um mau cidadão.
E é assim que um conjunto de dados pode se tornar de alta qualidade de uma maneira que torna o modelo ligeiramente menos preparado para a realidade.
Adorável.
O modelo mais tarde responde com confiança porque o Datanet embaixo dele foi curado em confiança.
Quando um adaptador OpenLoRA está servindo aquele comportamento estreito, a decisão de entrada feia não parece mais feia. Parece especialização.
Essa é a cicatriz.
Não dados ruins entrando. Todos veem esse risco.
A pior é a bagunça útil sendo filtrada porque torna o Datanet mais difícil de governar, mais difícil de validar, mais difícil de recompensar, mais difícil de transformar em uma trilha de atribuição limpa.
A arquitetura do OpenLedger torna isso visível porque a camada de dados não está oculta atrás de uma caixa preta. Datanets, registros de contribuição, reputação, Prova de Atribuição, uso do modelo, caminhos de recompensa. O sistema está basicamente dizendo: mostre a cadeia de suprimentos. Bom. Finalmente.
Mas uma vez que a cadeia de suprimentos está visível, a camada de julgamento se torna visível também.
Quem chamou isso de útil?
Quem marcou isso como redundante?
Quem penalizou a fonte estranha?... Seja lá o que for.
Quem deixou o lixo que parecia limpo passar?
Quem decidiu que esses dados estavam prontos para o modelo o suficiente para influenciar uma futura inferência?
Ninguém pode fingir que o modelo apenas "aprendeu."
Ok.
O Datanet ensinou o que era permitido.
E no OpenLedger, essa é a parte desconfortável. Os Datanets não apenas alimentam modelos. Eles pré-formatam o que a Prova de Atribuição pode recompensar mais tarde, o que a ModelFactory trata como material de treinamento seguro, em torno do que os adaptadores OpenLoRA podem se especializar, e o que ... eventualmente se estabelece como contribuição útil. Portanto, a camada de julgamento não está fora da economia de IA. Ela está sentada antes dela, decidindo silenciosamente o que a economia pode contar. Ótimo lugar para esconder poder. Bem na entrada.
É por isso que eu não compro a versão suave onde os Datanets simplesmente resolvem lixo entra, lixo sai. Eles não o resolvem como um filtro de lixo. Eles movem a luta para mais cedo. Antes do treinamento. Antes da inferência. Antes da resposta. Para o lugar onde contribuintes, validadores, regras de reputação e expectativas de recompensa decidem que tipo de dados se tornam legítimos.
Talvez isso seja melhor.
Provavelmente é melhor.
Ainda não está limpo.
Porque no momento em que um Datanet começa a decidir o que conta como qualidade, ele já está curando os erros futuros do modelo.
Não apenas sua precisão futura.
Os erros dele também.
E depois, quando o modelo diz algo confiante, talvez a Prova de Atribuição do OpenLedger possa mostrar a trilha, talvez a lógica da recompensa possa mostrar quem contribuiu, talvez a história do Datanet possa mostrar o que foi aceito.
Tudo bem.
Mas em algum lugar antes de tudo isso, alguém olhou para uma contribuição feia e decidiu se a bagunça era sinal ou apenas ruído vestindo uma jaqueta suja.
Essa decisão ainda está sentada dentro da resposta.
Saída limpa. Decisão suja do Datanet. Mesmo modelo.
E se a Prova de Atribuição pagar a trilha depois, a trilha começa daquela chamada de entrada.
Lugar adorável para um erro se tornar infraestrutura.