Eu continuo de olho em @OpenLedger e tentando descobrir se eles realmente resolveram a compensação justa para os colaboradores de dados de IA ou se apenas tornaram a extração mais transparente sem torná-la menos extrativa.
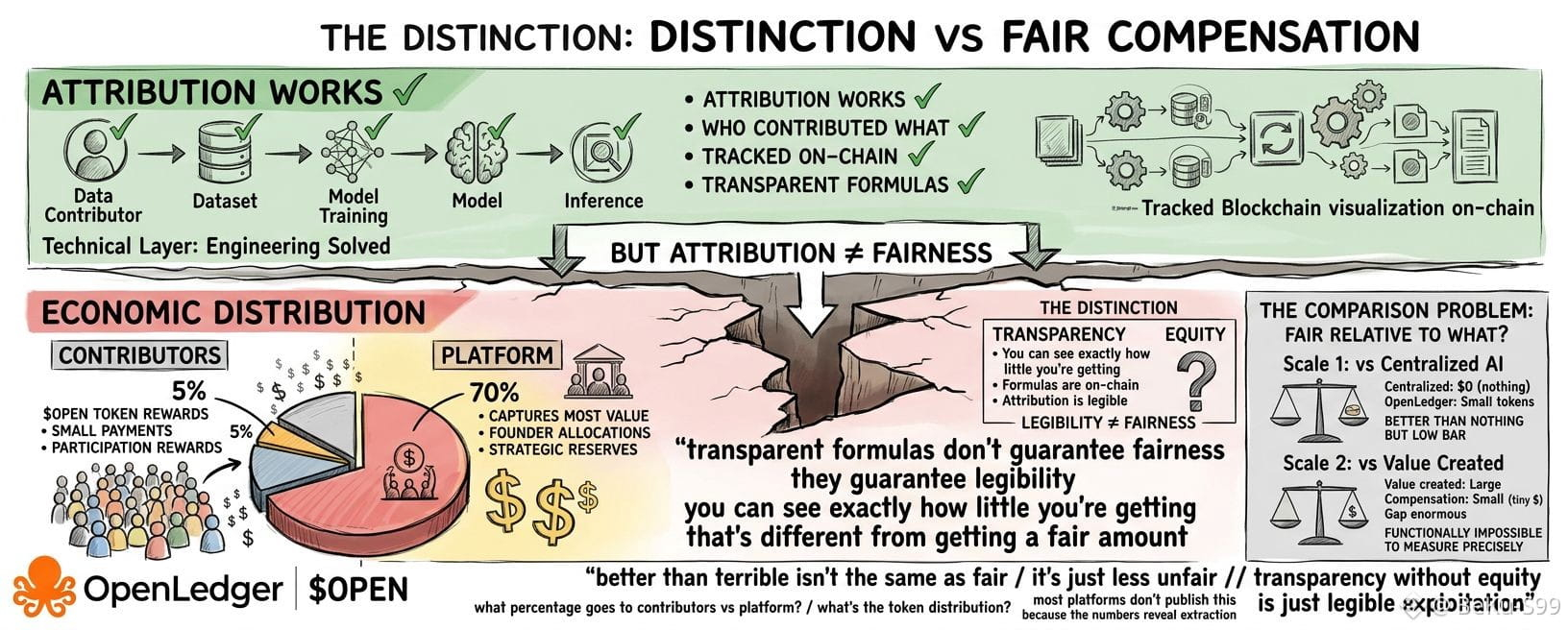
O que estou observando não é se a atribuição funciona tecnicamente. Rastrear quem contribuiu com quais dados para qual modelo é uma engenharia solucionável. O que estou observando é se a divisão econômica resultante dessa atribuição representa uma verdadeira justiça ou se é uma extração favorável à plataforma com um controle melhor.
O problema da compensação justa na IA descentralizada.
Não o mecanismo de atribuição. A questão fundamental é se rastrear contribuições se traduz em uma distribuição equitativa de valor ou se as plataformas ainda capturam a maior parte do valor enquanto os contribuintes recebem tokens representando reivindicações fracionárias sobre economias que não controlam.
Essa distinção importa porque transparência sem equidade é apenas exploração legível.
A OpenLedger diz que os contribuidores são compensados quando seus dados treinam modelos e quando esses modelos geram inferência. Os uploads de dados são verificados on-chain. Cada interação de IA se torna um evento monetizável para as pessoas que contribuíram.
O que não consigo determinar é se "evento monetizável" significa que os contribuintes capturam valor justo ou se significa que eles recebem pequenos pagamentos em tokens enquanto a plataforma captura a economia real.
O desafio é que "justo" requer comparação. Justo em relação a quê? Justo comparado a contribuir para a IA centralizada onde você não recebe nada? Essa é uma barra baixa. Justo comparado ao valor que sua contribuição cria? Isso requer saber qual parte do desempenho do modelo vem dos seus dados específicos, o que é funcionalmente impossível de determinar com precisão.
A maioria das plataformas descentralizadas resolve isso criando fórmulas de alocação de tokens. Sua contribuição é ponderada por algum algoritmo. Você recebe tokens proporcionais a esse peso. A fórmula é transparente e on-chain.
Mas fórmulas transparentes não garantem justiça. Elas garantem legibilidade. Você pode ver exatamente o quão pouco está recebendo. Isso é diferente de receber uma quantidade justa.
@OpenLedger usa $OPEN tokens para governança e compensação. Contribuintes ganham tokens com base na participação em datanets, treinamento de modelo e atribuição de inferência.
O que estou observando é se esses incentivos realmente se alinham ou se criam a aparência de alinhamento enquanto mantêm a extração favorável à plataforma.
A maioria das plataformas tokenizadas tem esse problema. Contribuintes iniciais obtêm propriedade significativa quando os tokens são baratos. Contribuintes tardios recebem recompensas de participação que não representam captura de valor significativa.
Talvez a OpenLedger tenha evitado isso. Talvez a distribuição de tokens deles crie uma propriedade ampla.
Talvez eles não tenham feito isso e este seja o manual padrão de cripto. Lançar com a narrativa de descentralização. Distribuir tokens para a aparência de participação. Manter controle através de alocações de fundadores.
Eu preferiria ver os números reais. Que porcentagem da receita de inferência vai para os contribuintes de dados versus a plataforma? Qual é a distribuição da propriedade dos tokens?
A maioria das plataformas não publica isso porque os números revelam a extração.
As apostas para a economia do contribuinte dependem de se a compensação é competitiva com as alternativas. Se eu contribuir com dados para a OpenLedger, ganho mais do que contribuindo para plataformas centralizadas?
Se a compensação é melhor do que as alternativas, isso valida o modelo.
Se a compensação não for melhor, então a proposta de valor é ideológica, não econômica. Você participa porque prefere extração transparente a extração opaca.
A maior parte do trabalho de dados de IA paga muito pouco. Rotular dados para plataformas centralizadas é um trabalho de baixa remuneração sem equidade. Se a OpenLedger paga um pouco mais e dá potencial de tokens, isso pode ser uma melhoria, mesmo que não seja justo.
A camada de atribuição é uma tecnologia interessante. Conseguir rastrear quais dados contribuíram para quais saídas de modelo é genuinamente útil.
Se isso se traduz em compensação justa ou apenas em uma extração mais sofisticada depende da estrutura econômica construída em cima.
Estou assistindo para ver em qual OpenLedger se torna.
O que estou observando particularmente é o comportamento dos contribuintes. Se as pessoas continuarem contribuindo após entender a economia, isso sugere que a compensação funciona. Se a contribuição cair uma vez que as pessoas calculam os retornos, isso sugere que não funciona.
A questão da compensação é fundamental. Você pode construir uma infraestrutura de atribuição impressionante. Você pode rastrear cada contribuição com precisão. Se a divisão econômica resultante dessa precisão não compensar justamente os contribuintes, você apenas tornou a extração mais eficiente.
E, honestamente, confio mais em plataformas que publicam claramente sua distribuição de valor do que em plataformas que enfatizam a transparência sem mostrar quem captura o valor.
