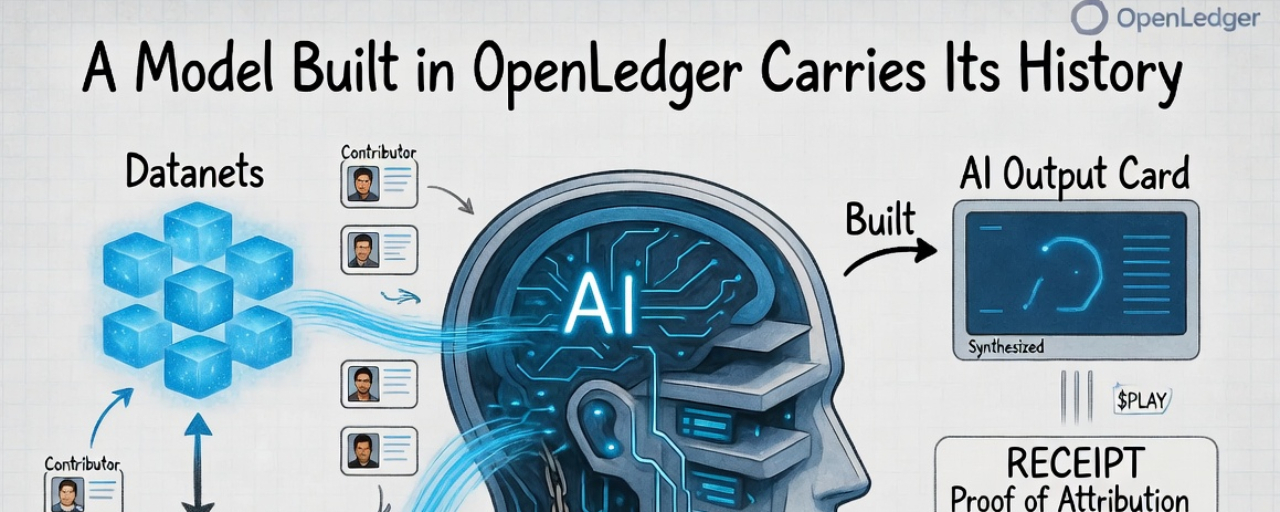
I keep returning to OpenLedger’s ModelFactory. At first glance, my mind slots it into the familiar “no-code AI builder” category and tries to move on. Clean interface, reduced operational headaches, the ability to spin up specialized models without managing GPU clusters at odd hours. Practical. Efficient. But that label feels too narrow for what’s actually happening.ModelFactory doesn’t just produce models. It creates something that immediately begins accumulating obligations—obligations of attribution, of provenance, of memory.
Once a model draws from Datanets and approved datasets, it stops being a blank slate. It has origins. It has contributors whose work now sits beneath its weights, even when the final outputs appear seamless and self-generated.This is the deeper current running through OpenLedger.Traditional model builders often work hard to conceal the mess. Upload your data, pick hyperparameters, train, deploy, and celebrate the accuracy bump. The narrative focuses on the shiny new capability while quietly erasing the question of where the meaningful signal actually came from. Which dataset carried the weight? Which contributors shaped the behavior that now performs?

In OpenLedger, that question refuses to vanish after training finishes.The model isn’t merely trained. It is tied to its sources.That’s why ModelFactory feels significant. Selecting data from a Datanet isn’t just a technical choice—it’s the moment a model begins carrying a traceable path. Proof of Attribution can later reopen that path when value starts flowing.
The system is designed so the model cannot easily pretend it emerged from nowhere.This honesty stands out. Most AI pipelines treat training as a sealed black box: data enters, gradients flow, performance improves, and the original signals dissolve into the final artifact. Contributors fade into the background. The model becomes a product, and the product gets monetized without looking back.OpenLedger flips the emotional texture of that process.
When you build in ModelFactory, you’re not just picking “high-quality data.” You’re choosing which contributor histories will travel with the model, which Datanets will underpin its capabilities, and which validation trails will inform its future accountability. Whether the model later serves inference, powers agents, or routes through OpenLoRA adapters, the attribution chain persists.It makes model creation feel heavier in a meaningful way.
The surface experience might actually be smoother—fewer infrastructure burdens, a more direct route from curated data to deployable model. Yet underneath, the accounting sharpens. The builder starts not from a void but from a network of Datanets, reputation signals, and validated contributions. Once trained, success isn’t measured only by performance, but by whether the system can still identify which parts of the supply chain actually mattered.What does it mean to create models inside a system that remembers?
The easy story is “democratizing AI.” The more interesting one is: if building becomes easier, who tracks what these new models owe? Without attribution, wider access simply accelerates the old pattern of extraction at scale. More models, more outputs, same forgotten inputs.OpenLedger’s architecture pushes against that by design. Datanets provide the structured sources. Proof of Attribution evaluates real influence. OpenLoRA enables efficient, modular specialization. Together they form a pipeline where creation, deployment, usage, and rewards stay connected to the same underlying question: who actually helped this thing become useful?That question can be uncomfortable.
It reveals uneven contributions. It can show that a flashy dataset added little while a narrow, high-signal Datanet carried disproportionate weight. Influence scoring becomes a form of judgment rather than just another dashboard metric.In this light, ModelFactory starts to resemble the entry point for a longer accountability chain. A model is built from chosen sources, fine-tuned, deployed, perhaps used by agents. When value accrues—through usage fees, agent actions, or other flows—Proof of Attribution follows the trail back through data, adapters, and execution to determine fair recognition.This creates data debt in the truest sense. Not guilt, but settlement. The model drew value from somewhere; the system now has mechanisms to decide what that influence deserves in return. “Data ownership” sounds noble and abstract.
Debt feels more grounded because it demands resolution.Specialized models amplify this dynamic. As demand grows for finance-specific, research-focused, or domain-narrow AI, the data behind them matters even more. ModelFactory lowers the barrier to creating these, but OpenLedger raises the importance of mapping their debts accurately.The tradeoff is clear: easier creation paired with harder forgetting. Most AI development makes both easier—outputs look more original even as their sources blur. OpenLedger bets that a thriving model economy requires the opposite balance. Models can proliferate, but they should not escape their supply chains entirely.This matters more as AI moves beyond chat interfaces into agents that act—researching, trading, executing workflows, routing value.
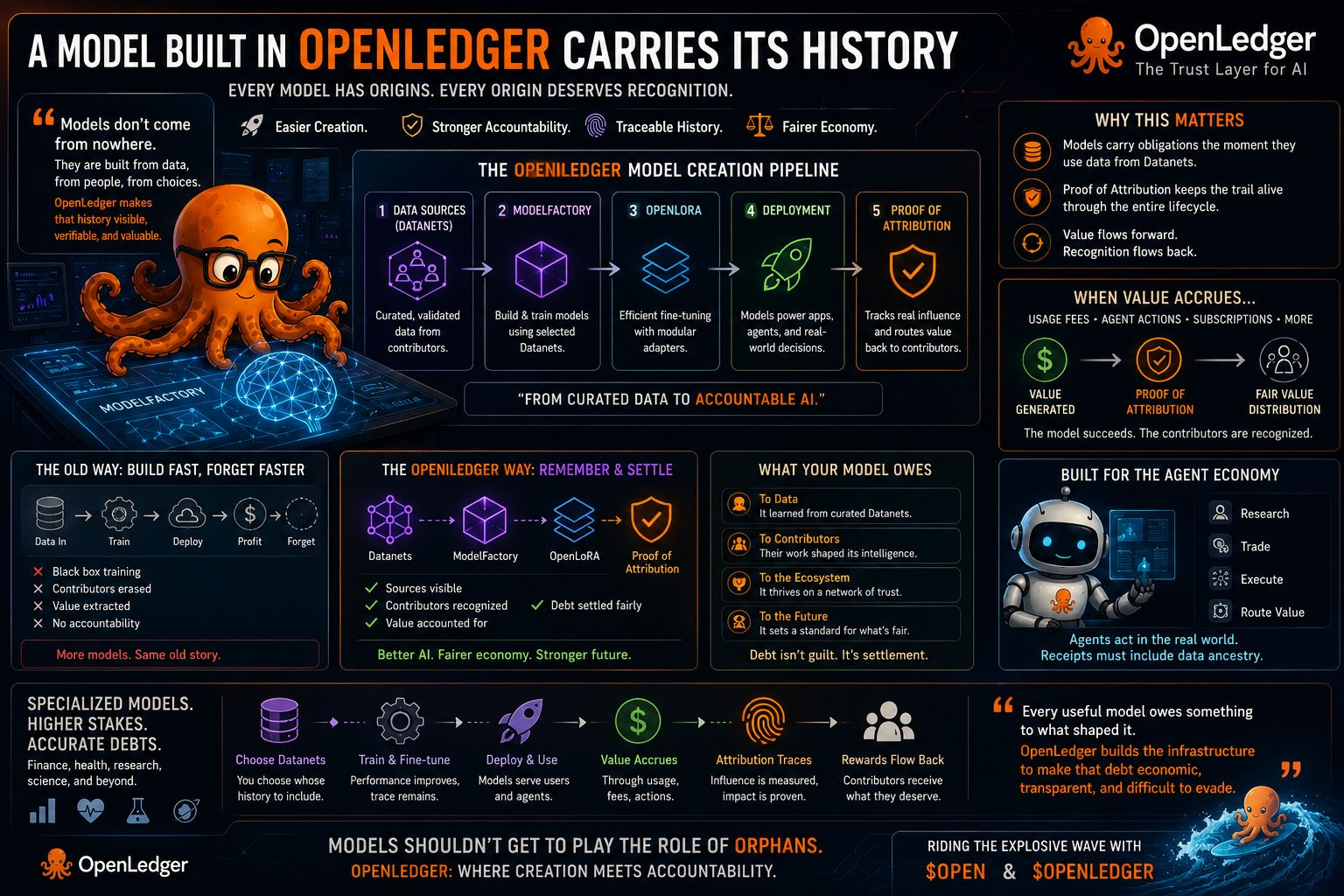
A model with hidden influences making high-stakes decisions creates different risks than one whose provenance is traceable. When an agent acts, the receipt should include the data ancestry underneath.ModelFactory is not the most glamorous piece of the stack, but it may be one of the most consequential. It determines the kind of memory a model begins with, long before it starts behaving as if it invented itself.Every useful model owes something to what shaped it.
OpenLedger is building the infrastructure to make that debt economic, transparent, and difficult to evade — riding the explosive wave with $AT and $PLAY . In an AI economy, models shouldn’t get to play the role of orphans.