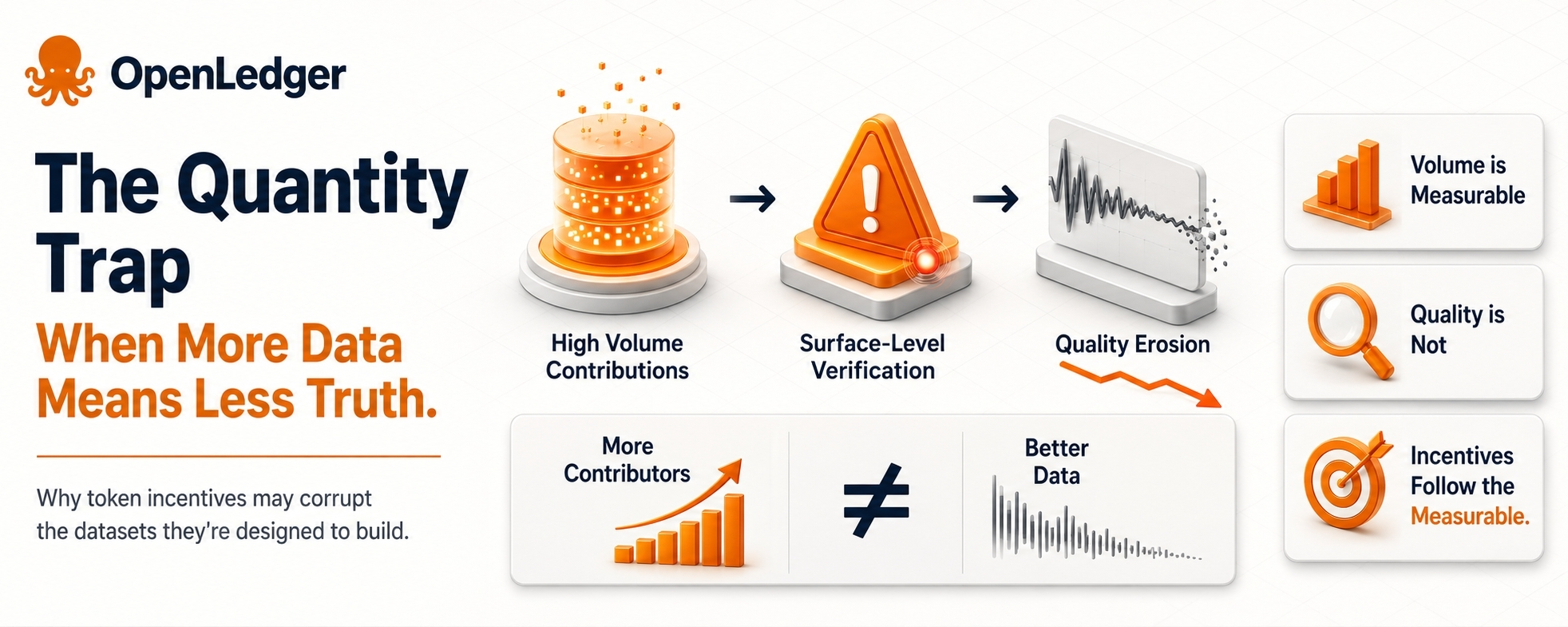
Existe um problema estrutural embutido em quase todas as redes de dados incentivadas por tokens que raramente é examinado diretamente: as pessoas mais motivadas a contribuir são frequentemente as menos qualificadas para determinar o que é valioso.
O modelo da OpenLedger depende de contribuintes fornecendo dados para um pipeline verificado e rastreado por atribuição. A recompensa em token é o mecanismo que impulsiona a participação. Mas as recompensas em token, por design, precisam ser legíveis — elas têm que se conectar a algo mensurável. E nas redes de dados, a mensurabilidade quase sempre recai sobre a quantidade em vez da qualidade, porque a qualidade é lenta, cara e contestada para verificar.

Isso cria uma distorção que opera silenciosamente na fundação do sistema.
Quando os contribuidores entendem que as recompensas estão atreladas ao volume — ou até mesmo a proxies de qualidade como conformidade de formato, completude de metadados ou diversidade de fontes — o comportamento se adapta a esses sinais em vez de à real utilidade. O conjunto de dados que é construído não é necessariamente o que os desenvolvedores de IA precisam. É o conjunto de dados que a estrutura de incentivos foi mais fácil de manipular em grande escala.
Essa não é uma crítica única ao OpenLedger. É um modo de falha conhecido nos mercados de dados crowdsourced de forma geral. Mas isso é especialmente consequente aqui porque a proposta de valor do OpenLedger se baseia em conjuntos de dados verificados e confiáveis — não apenas grandes. Se a camada de verificação for robusta o suficiente para capturar contribuições de baixa qualidade ou manipuladas, isso representa um custo de fricção significativo que reduzirá o throughput dos contribuidores. Se não for robusta o suficiente, os dados que se acumulam podem ter a aparência de verificação sem a substância.
A dinâmica mais profunda que vale a pena observar é o que acontece com o comportamento dos contribuidores ao longo do tempo, à medida que o preço do token flutua. Durante períodos de preços altos, o volume de contribuições provavelmente aumenta — mas o ruído também. Contribuidores que normalmente não participariam inundam o sistema, trazendo dados marginais que passam em verificações superficiais. Durante períodos de preços baixos, os contribuintes cuidadosos e específicos do domínio — aqueles que nunca foram puramente motivados economicamente — podem ser os únicos que restam. Ironicamente, a qualidade dos dados da rede pode estar inversamente correlacionada com o preço do token.
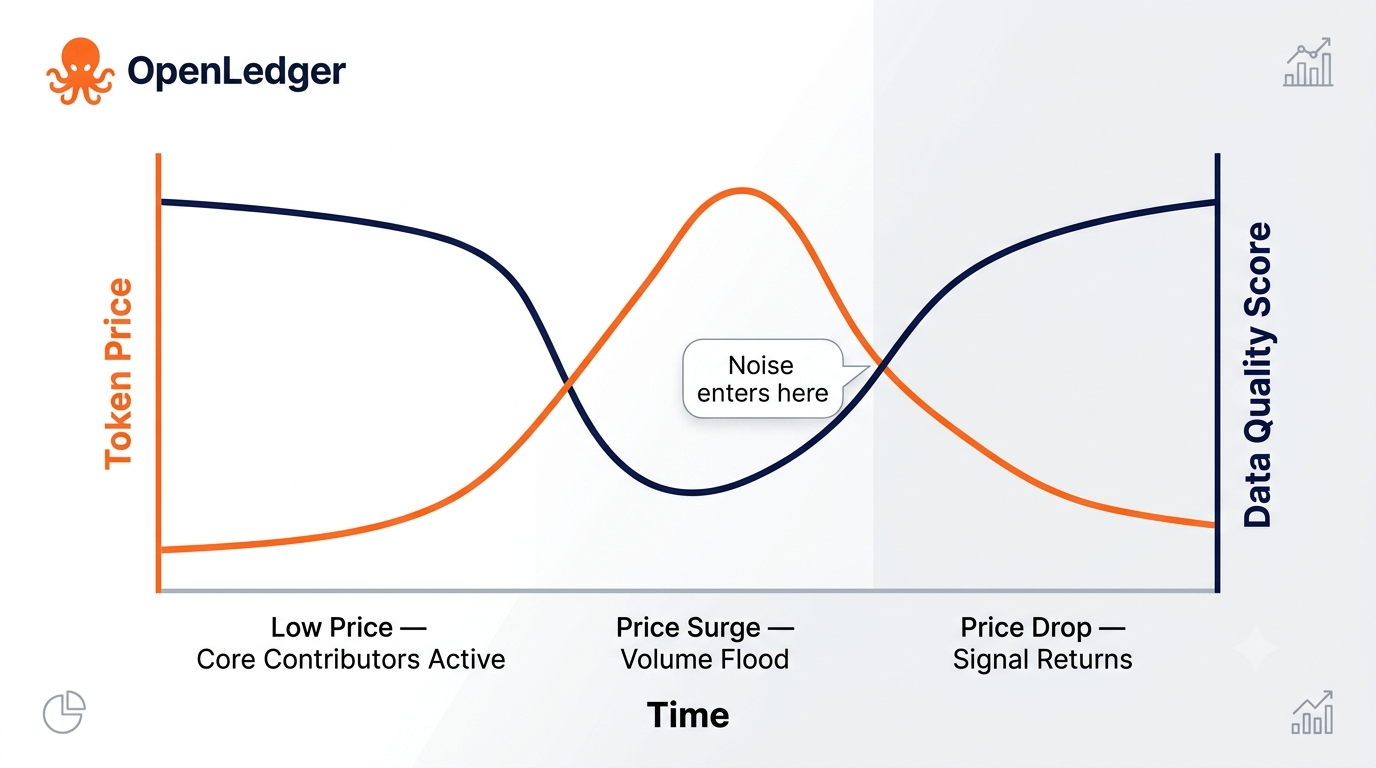
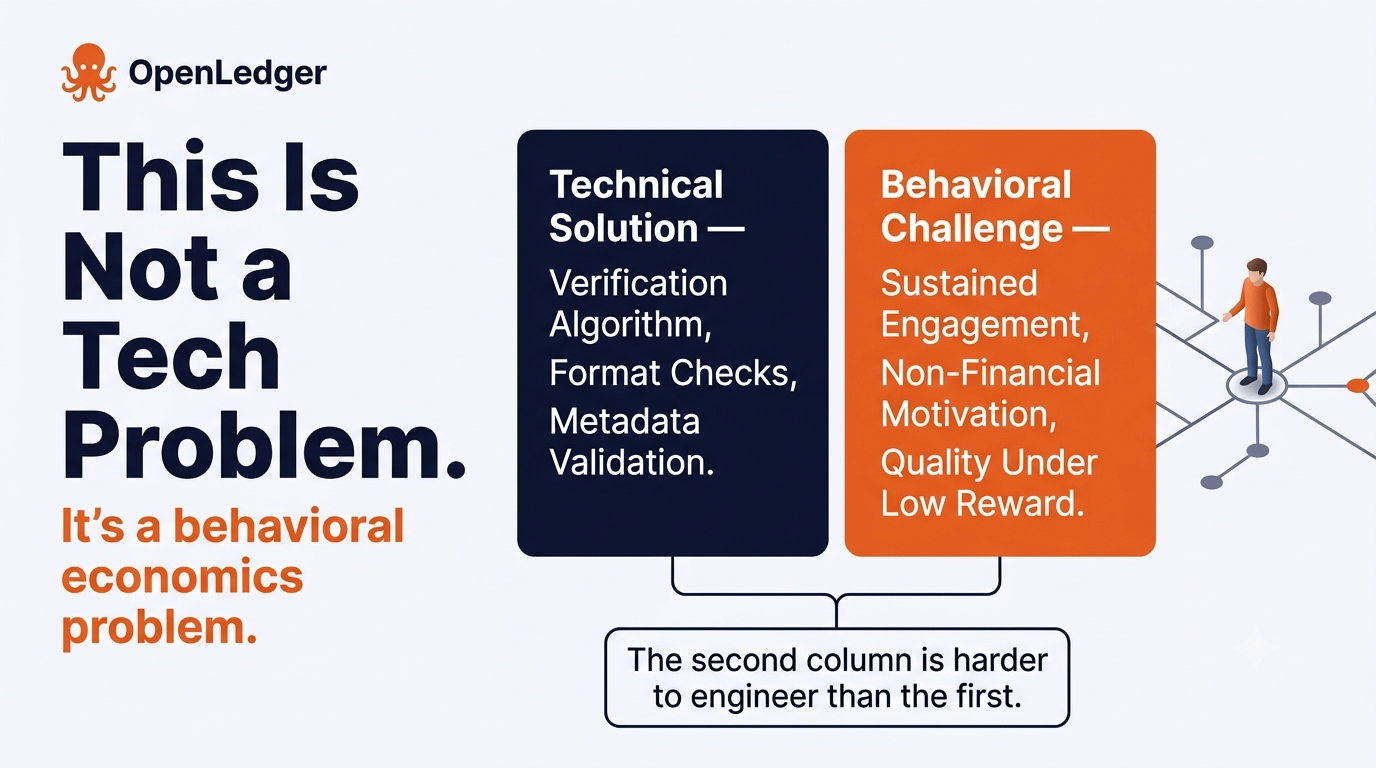
Isso sugere que a integridade de dados a longo prazo do OpenLedger não é principalmente um problema técnico. É um problema de economia comportamental. O sistema precisa de contribuidores que permaneçam engajados e forneçam dados úteis, mesmo quando o incentivo financeiro é fraco. Isso é muito mais difícil de projetar do que um algoritmo de verificação.
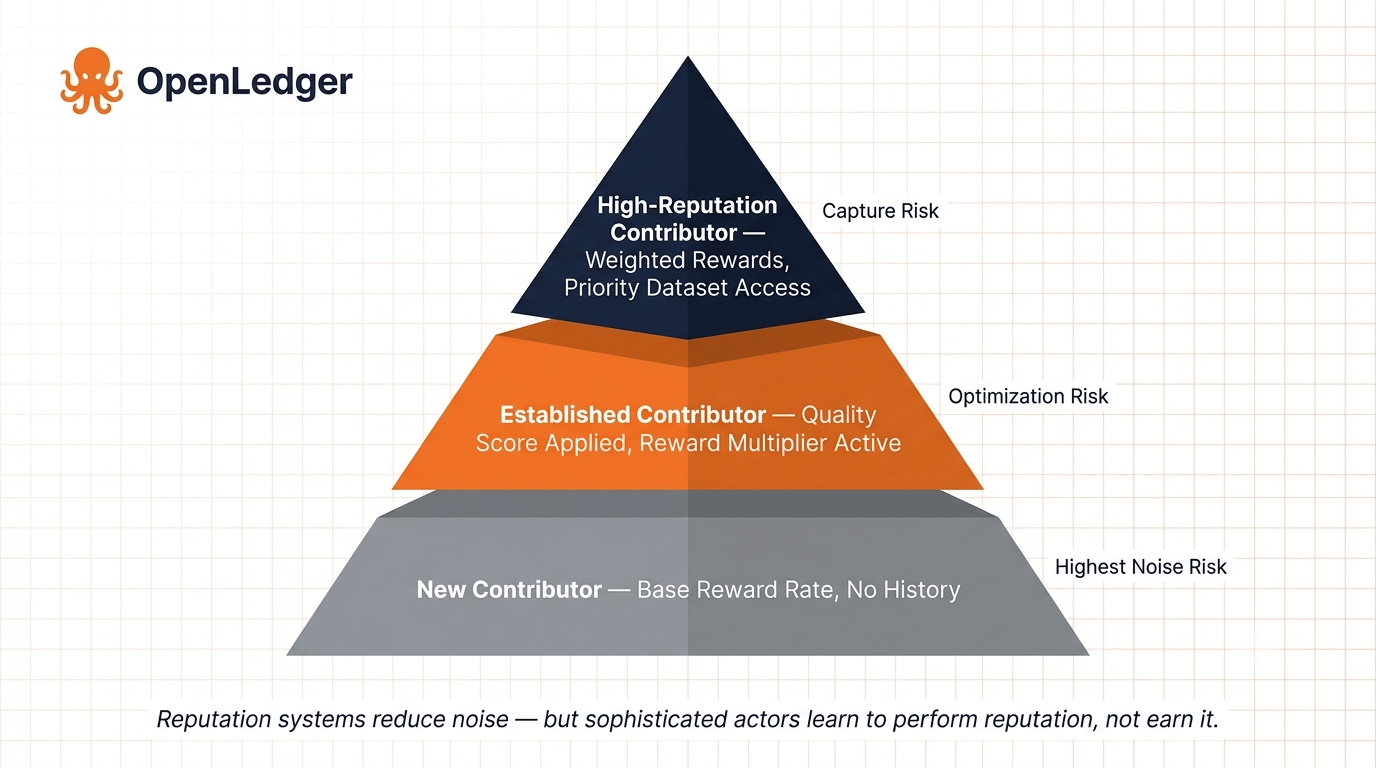
Uma possível solução parcial é a ponderação de reputação — onde as pontuações de qualidade histórica dos contribuidores influenciam os multiplicadores de recompensa futuros, criando um incentivo não financeiro para manter padrões ao longo do tempo. Se o OpenLedger implementou algo com dentes reais aqui, ou se é uma camada mais suave que contribuidores sofisticados podem eventualmente otimizar, é a questão que separa uma rede durável de uma bem arquitetada que se degrada sob carga.
A conclusão honesta não é que o OpenLedger não pode resolver isso. É que nenhuma rede de dados operando com incentivos de token resolveu isso completamente ainda. O projeto está construindo em um espaço onde o mecanismo econômico e o objetivo epistêmico estão em constante tensão. Observar como essa tensão é gerida — não no lançamento, mas dezoito meses depois — dirá mais sobre o valor do sistema do que qualquer whitepaper.