Vou ser honesto—quase passei para o próximo @OpenLedger quando ele apareceu pela primeira vez no meu feed. Outro token de infraestrutura de IA? O espaço já está cheio de projetos prometendo ser a espinha dorsal do aprendizado de máquina, e a maioria soa idêntica depois de um tempo.
Mas algo me fez parar e realmente investigar o que $OPEN está tentando construir. E quanto mais eu olhei, menos parecia uma infraestrutura típica de IA e mais parecia... seguro? O que soa chato, eu sei. Mas me escute.
Aqui está o que fez sentido para mim: todo mundo está obcecado em tornar a IA mais rápida, inteligente e poderosa. Isso é legal para criar demonstrações legais. Mas assim que a IA toca em algo sério—decisões de empréstimos, verificações de conformidade, verificação de identidade— a conversa muda completamente. Ninguém em uma sala de reuniões se preocupa com a velocidade do token. Eles se preocupam com uma pergunta aterrorizante: quem é responsável quando isso dá errado?
Essa pergunta é por que eu acho que a OpenLedger pode realmente ter uma oportunidade.
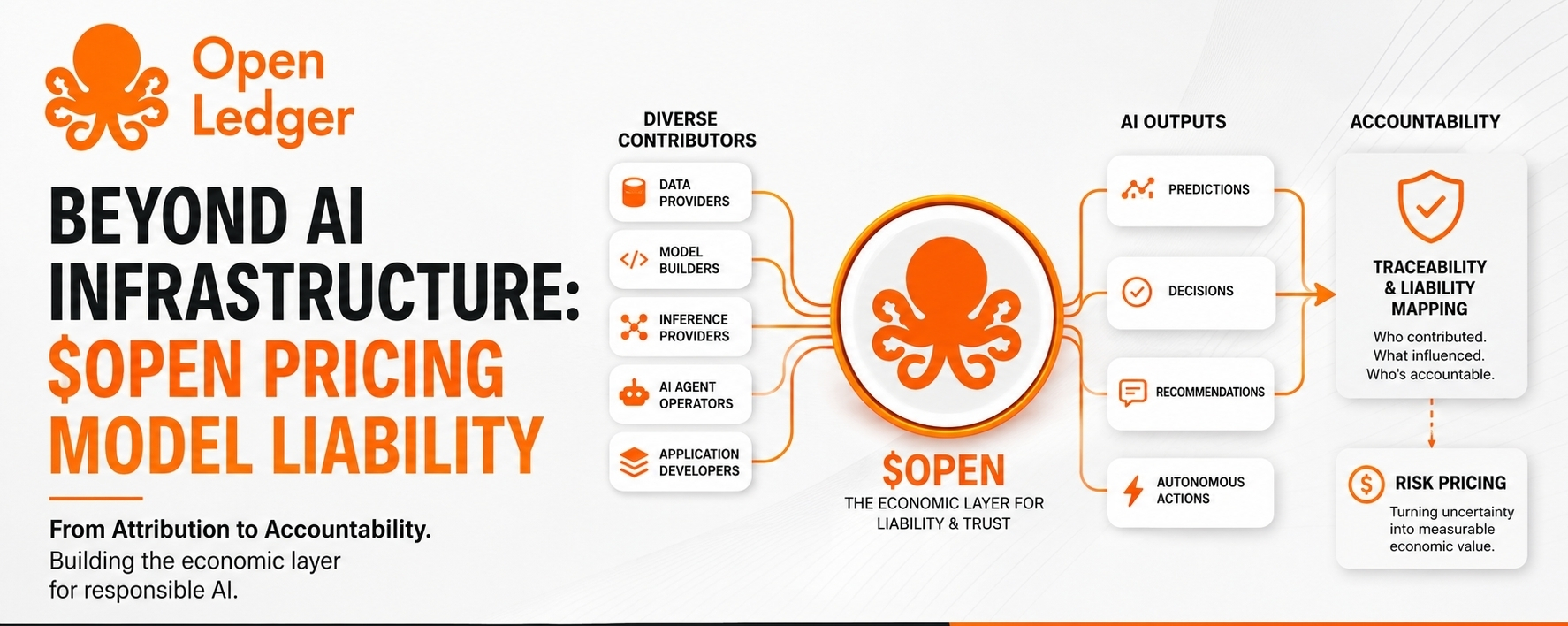
A maioria das pessoas fala sobre seu sistema de atribuição como se fosse apenas sobre recompensar os contribuidores de dados de forma justa. Boa história, marketing limpo. Mas eu acho que eles estão subestimando o verdadeiro ângulo. Em ambientes que realmente importam—finanças, saúde, jurídica—atribuição não é um mecanismo de recompensa. É um mapa de responsabilidades.
Pense nisso. Quando um agente de IA toma uma decisão falha por causa de dados de treinamento ruins, quem é culpado? Se cinco partes diferentes contribuíram para a saída daquele modelo, como você pode rastrear a responsabilidade? O software tradicional era bagunçado, mas pelo menos você sabia quem enviou o código. Sistemas de IA parecem que a responsabilidade foi jogada em um liquidificador.

E os mercados odeiam risco incerto. As empresas odeiam ainda mais.
Eu testei essa teoria pessoalmente no mês passado. Posição pequena em $OPEN em torno de $0.18, principalmente apenas para me forçar a prestar atenção. Observei como eles estão construindo trilhas de auditoria em sua camada de infraestrutura. Não é sexy. Não vai bombar no hype do CT. Mas quanto mais eu pensava sobre equipes de compras avaliando fornecedores de IA, mais percebia que esse pode ser o ângulo que realmente leva à adoção institucional.
Porque aqui está a questão: as instituições não são anti-inovação. Elas são anti-incerteza que não conseguem operacionalizar. Se a OpenLedger puder fazer sistemas de IA distribuídos parecerem governáveis—com linha de origem real, decisões explicáveis, caminhos de escalonamento claros—isso não está competindo com narrativas de computação.
Isso está competindo no mercado para reduzir a incerteza em torno das decisões da máquina.
Muito menos glamouroso. Também potencialmente muito mais necessário.

Ainda é cedo, ainda é arriscado, ainda estou de olho. Mas $OPEN parece menos um teatro de infraestrutura e mais a tubulação chata que pode realmente importar quando a IA passar das demonstrações para o dinheiro real. E eu prefiro estar cedo na infraestrutura chata do que tarde em vaporware emocionante.
Posição: Long pequeno, observando parcerias de governança de perto