I have enough. The angle is sharpening: the "biggest problem nobody wants to fix" is data attribution — AI companies eat trillions of words from creators and pay back zero. Everyone talks about capability; nobody talks about the theft underneath it. OpenLedger's Proof of Attribution is one attempt. The contrarian turn: attribution sounds nice on paper, but proving which data shaped which output is genuinely hard, and the incentive to pay shrinks the moment the model is good enough.
One idea. Let me write.
The biggest problem in AI nobody wants to fix — $OPEN
Market felt kind of flat today. Nothing moving, nothing tanking, just that mid-week drift where you scroll and refresh and nothing actually changes. I left the charts open and started doing something else — cleaning out my notes folder, weirdly enough.
And while I was clicking through old saved threads I came across a screenshot I forgot I took. It was just a tweet from some writer complaining that her entire blog archive had been scraped into a training dataset. No notice, no credit, nothing. She found out because the model could quote her almost word for word.
I closed it, went back to the charts, but it sat with me for a bit.
So I started looking at $OPEN again. I'd glanced at it during the listing — saw the 200% pump, saw the airdrop noise, moved on. AI token, fine. Another one. But this time I actually read what they're doing instead of just looking at the chart.
And the thing that hit me wasn't the tech. It was how quietly everyone has accepted something insane.
We talk about AI like the problem is hallucinations, or safety, or compute. Those are real. But the thing nobody really wants to touch is that the entire industry is built on data that nobody paid for. Every model you use was trained on someone's writing, someone's code, someone's art, someone's recorded voice. And the people who built those datasets just… got nothing. That's the foundation. The whole thing.
And the wild part is — nobody wants to fix it. Because fixing it costs money. And the labs benefit from the current setup. So it just keeps going.
OpenLedger's pitch, basically, is "Payable AI." The idea is that contributors get rewarded automatically when their data shapes an AI output, through something they call Proof of Attribution. So if your dataset influenced an answer, you get paid. Not as charity. As infrastructure. Built into the chain. DL News
I sat with that for a minute because the assumption people have is that attribution is impossible — that once data goes into a model it's blended forever, you can't trace it back. And honestly that's been the polite excuse the industry hides behind for years. We'd love to pay you, we just can't tell which words were yours. OpenLedger's bet is that you actually can, if you build the rails for it from the start.
But here's the part that bothers me.
Attribution at this layer is technically hard. Like, really hard. Tracing which slice of training data shaped which token in an output is not a solved problem in ML research. It's an active area. So when a chain says "we attribute fairly and pay accordingly" — I want to know what the resolution actually is. Are we attributing at the dataset level? The document level? The sentence level? Because the difference between those is the difference between a real economy and a vibes-based payout system.
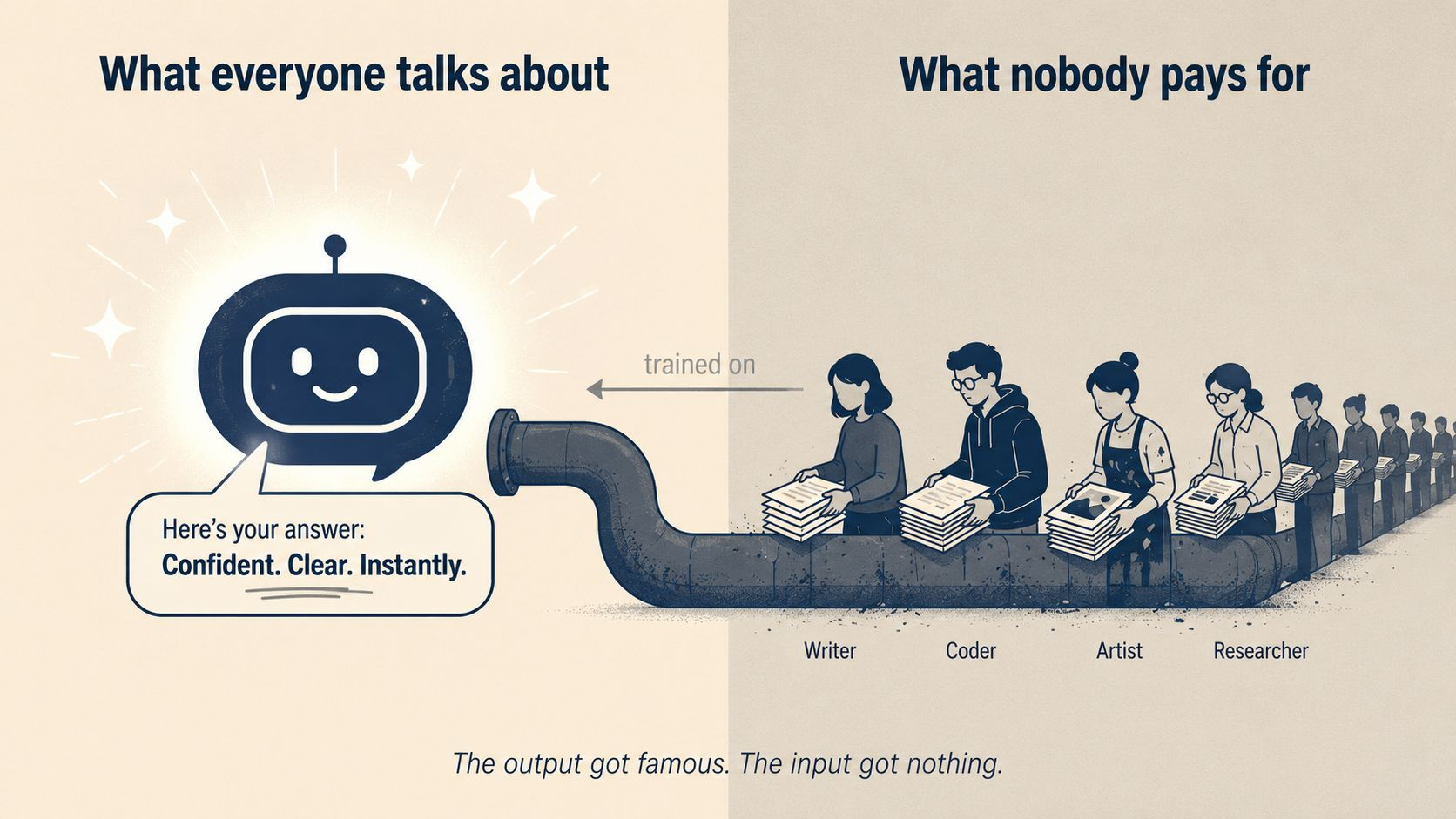
And there's a second thing nagging me. Even if attribution works perfectly, the incentive to use an attributed model only exists if there's no cheaper unattributed model right next to it. And right now there is. There always is. The Big Labs are not lining up to plug into a network that forces them to share revenue with the people whose words they took. Why would they.
So the question isn't really "does the tech work." It's "can a parallel economy grow big enough that contributing to it becomes more attractive than getting scraped for free." That's a much harder bet. Not impossible — crypto has done weirder things — but harder than the listing chart suggests.
I think that's why this stuff matters more for the people who make the data than the people who trade the token. Writers, researchers, small dataset curators — they've been the silent input for ten years. If even one chain figures out how to route value back to them, the whole conversation around AI shifts. From "look what it can do" to "look who actually built it."
I don't know if $OPEN ends up being the one. The tokenomics still have a lot of unlocks ahead, and the chart already did its first move. Could chop sideways for months. Could go anywhere.
Anyway — coffee's gone cold. Going to go close some tabs. The market still feels like nothing's happening today, which is probably the best time to read something that isn't a chart.
@OpenLedger #OpenLedger $OPEN