Continuo de olho em @OpenLedger e tentando descobrir se as datanets contribuídas pela comunidade produzem dados de qualidade ou se descentralizar a coleta de dados significa apenas descentralizar lixo em grande escala.
O que estou observando não é se a infraestrutura de atribuição funciona. Rastrear quem contribuiu com o quê é uma engenharia resolvida. O que estou observando é se os dados sendo contribuídos são realmente valiosos ou se incentivar a contribuição cria quantidade sem qualidade.
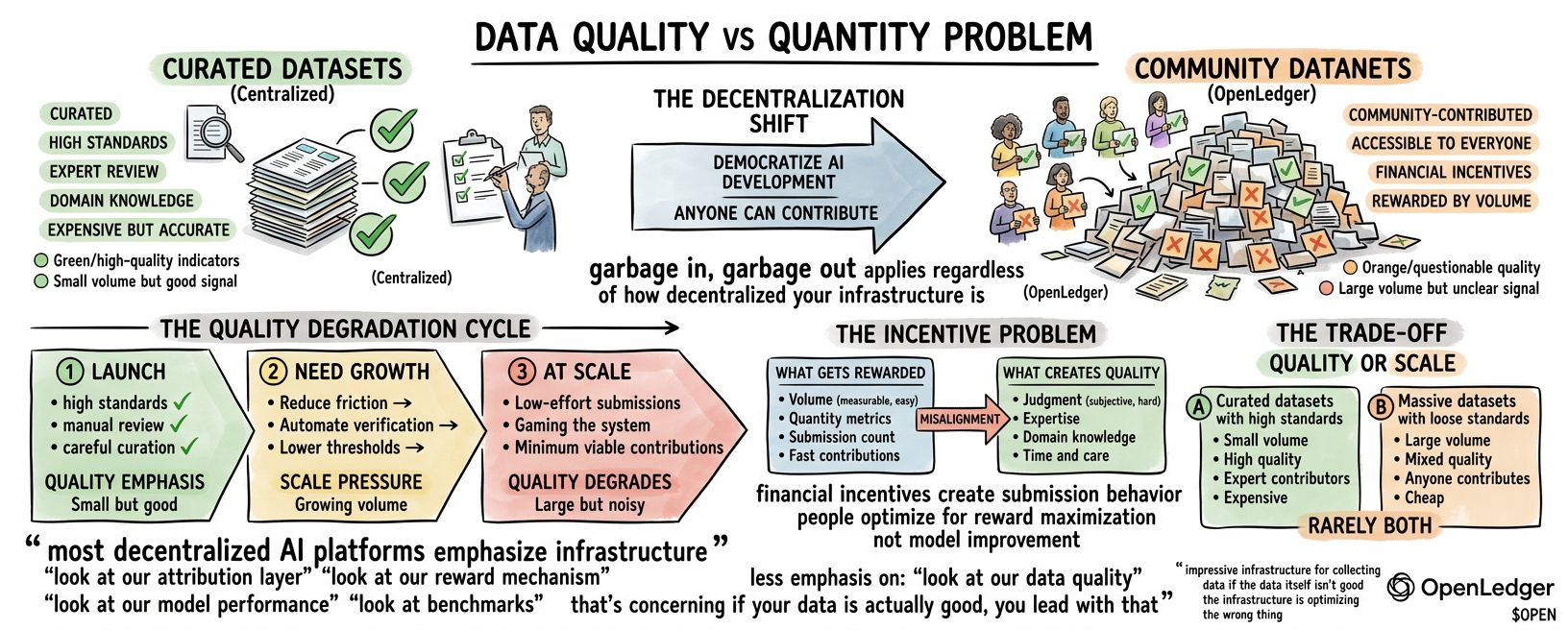
O problema da qualidade dos dados na IA descentralizada.
Não o mecanismo de verificação. O desafio fundamental de garantir que, ao recompensar pessoas por contribuir com dados, elas contribuam com bons dados, em vez de manipular o sistema de recompensas com envios de baixo esforço que passam nos padrões mínimos, mas não melhoram o desempenho do modelo.
Essa distinção é importante porque lixo entra, lixo sai se aplica independentemente de quão descentralizada é sua infraestrutura.
A OpenLedger permite que qualquer um crie datanets ou contribua com as existentes. Os contribuintes enviam dados, têm a verificação na blockchain e ganham recompensas. Quanto mais você contribui, mais você ganha.
O que eu não consigo dizer é se 'acessível a todos' produz conjuntos de dados valiosos ou se produz ruído que dilui o sinal.
O desafio é que incentivos financeiros criam comportamentos de submissão. Quando você paga as pessoas para contribuir com dados, elas contribuem com dados. Mas os dados que elas contribuem otimizam para a maximização de recompensas, não necessariamente para a melhoria do modelo.
A maioria da coleta de dados crowdsourced enfrenta esse problema. Você precisa de volume. Então você diminui as barreiras. Recompensa quantidade.
E você recebe envios de baixo esforço. Manipulando o sistema. Contribuições minimamente viáveis que qualificam para pagamento, mas não agregam valor.
@OpenLedger tem mecanismos de verificação. Os dados são revisados. Há controle de qualidade.
O que estou observando é se esses mecanismos funcionam em escala ou se funcionam inicialmente e quebram quando o volume aumenta e a verificação se torna cara em relação às recompensas.
A maioria das plataformas começa com padrões altos. Então elas precisam de crescimento. Então, reduzem a fricção. Automatizam a verificação.
E a qualidade degrada. Gradualmente. O conjunto de dados cresce, mas a qualidade média das contribuições diminui.
Talvez a OpenLedger tenha resolvido isso. Talvez sua verificação escale sem degradação.
Talvez eles não tenham feito isso e estejam enfrentando o mesmo dilema. Qualidade ou escala. Você pode ter conjuntos de dados curados com altos padrões. Ou conjuntos de dados massivos com padrões baixos. Raramente ambos.
Os riscos para o desempenho do modelo dependem se os incentivos de contribuição estão alinhados com qualidade ou apenas com quantidade. Se recompensas correlacionam com a melhoria real do modelo, os contribuintes otimizam para qualidade. Se as recompensas correlacionam com volume, os contribuintes otimizam para volume.
A maioria dos sistemas de recompensa otimiza para coisas mensuráveis. Volume é mensurável. Qualidade é subjetiva. Então, os sistemas recompensam volume e esperam que a qualidade siga.
Normalmente, não funciona. Qualidade requer julgamento. Especialização. Conhecimento de domínio. Tempo. Isso é caro. Volume é barato.
Eu preferiria ver evidências de que as datanets da OpenLedger produzem modelos melhores do que alternativas centralizadas. Não apenas conjuntos de dados maiores. Melhor desempenho do modelo.
Se os modelos treinados com dados da OpenLedger apresentarem desempenho semelhante ou pior, então a descentralização não está agregando valor.
A questão da qualidade dos dados é importante porque os modelos de IA são tão bons quanto seus dados de treinamento. Você pode ter uma infraestrutura perfeita, atribuição transparente, compensação justa. Se os dados subjacentes forem medianos, seus modelos serão medianos.
A maioria das plataformas de IA descentralizadas enfatiza sua infraestrutura. Olhe para nossa camada de atribuição.
Menos ênfase em: olhe para a qualidade dos nossos dados. Olhe para o desempenho do modelo.
Isso é preocupante. Se seus dados são realmente bons, você lidera com isso. Se sua infraestrutura é impressionante, mas seus dados são questionáveis, você fala sobre a infraestrutura.
Talvez a OpenLedger tenha dados fortes. Talvez seus modelos se saiam bem. Talvez eu não tenha visto os benchmarks porque eles ainda não os publicaram.
Talvez os dados sejam medianos e eles estejam esperando que o volume compense a qualidade.
Isso pode funcionar para alguns casos de uso. Mais dados podem superar uma qualidade inferior se você tiver poder computacional suficiente.
Não funciona para domínios especializados. Dados médicos, dados legais, dados científicos. Você não pode compensar contribuições de baixa qualidade com volume.
Estou de olho para ver que tipo de IA a OpenLedger se tornará. Modelos genéricos onde o volume importa? Ou modelos especializados onde a qualidade é crítica?
A questão da qualidade dos dados é fundamental. Você pode construir uma infraestrutura impressionante para coletar e atribuir dados. Se os dados em si não forem bons, a infraestrutura está otimizando a coisa errada.
E, honestamente, confio em plataformas que enfatizam o desempenho do modelo em vez de plataformas que enfatizam a infraestrutura enquanto evitam comparações de desempenho.
