
Algumas noites atrás, eu me perdi em um buraco de coelho lendo sobre marketplaces de dados de IA de novo, e fiquei pensando em um caso antigo de uma startup em Cingapura. Eles alegavam ter milhões de registros de comportamento de usuários para treinar modelos de recomendação de compras. No papel, parecia incrivelmente valioso. Um grande conjunto de dados, narrativa de IA, ângulo empresarial, tudo.
Mas depois, um dos parceiros testou o modelo em uma campanha real e o desempenho mal melhorou. Uma boa parte dos dados era repetitiva, barulhenta ou simplesmente irrelevante fora de demos controladas.
Essa história ficou na minha cabeça porque me fez perceber algo desconfortável: dados não são automaticamente líquidos apenas porque existem.
E honestamente, esse é o pensamento exato que tive enquanto lia mais profundamente sobre a OpenLedger por volta das 2 da manhã.
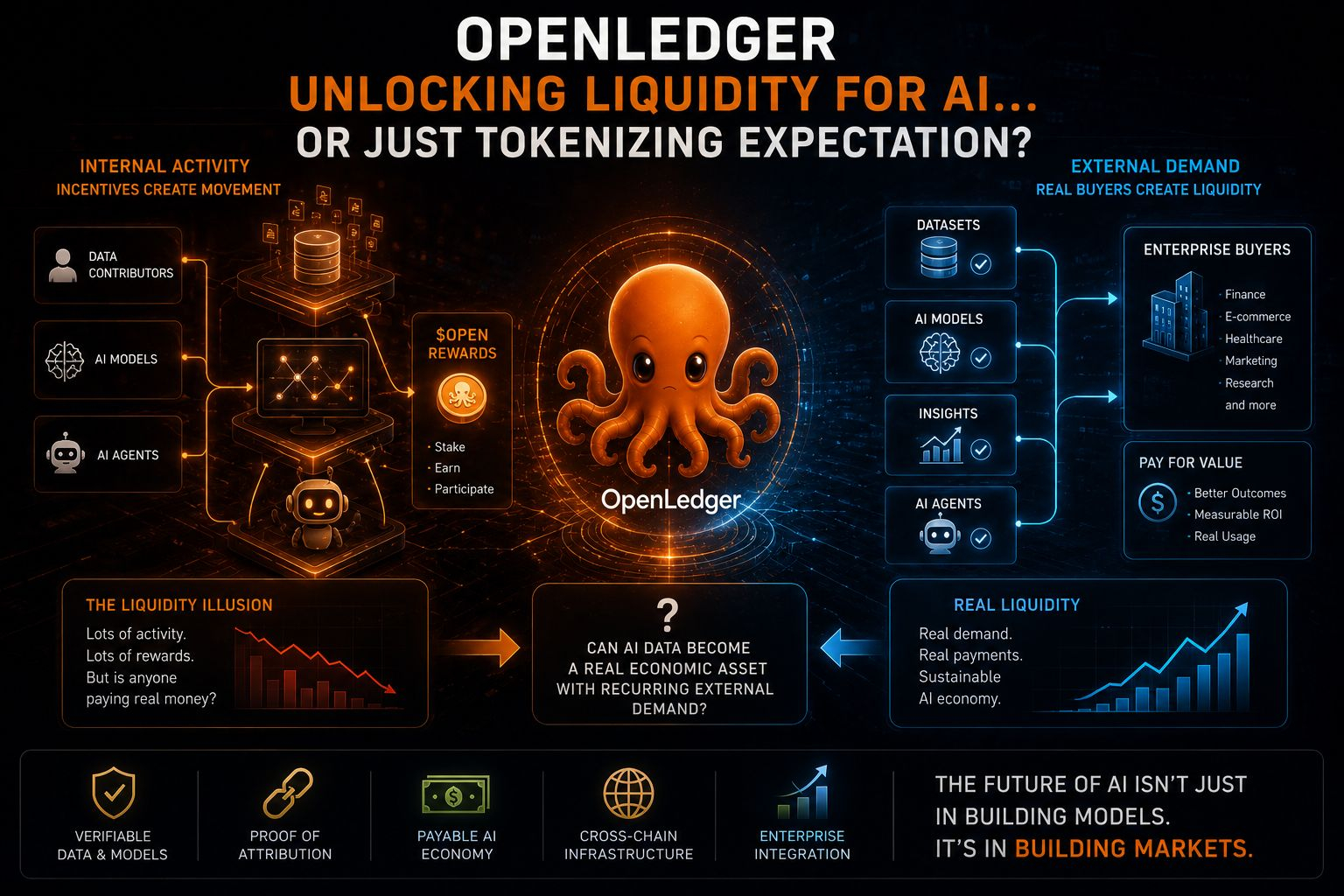
A OpenLedger está tentando construir uma economia onde conjuntos de dados, modelos de IA e agentes possam funcionar como ativos on-chain. Contribuintes carregam dados, modelos consomem esses dados, agentes executam tarefas, e todo o sistema está conectado por meio de incentivos OPEN. Em teoria, parece um marketplace de IA auto-reforçado.
A ideia é atraente porque as pessoas do crypto naturalmente adoram o conceito de transformar recursos inativos em ativos negociáveis. Mas eu acho que há uma distinção importante que às vezes se perde entre atividade e liquidez.
Atividade é movimento.
Liquidez é alguém realmente pagando.
Essa diferença importa muito mais do que as pessoas pensam.
Dentro da OpenLedger, um conjunto de dados pode gerar recompensas. Um modelo de IA pode gerar métricas de uso. Agentes podem interagir continuamente com o ecossistema e criar atividade visível on-chain. Painéis parecem vivos. Transações se movem. Participantes ganham tokens.
Mas nada disso prova automaticamente que existe demanda externa.
Eu mantive comparando na minha cabeça com Ethereum por um tempo. No Ethereum, os usuários pagam gas porque realmente querem espaço em bloco. Em redes de oráculos como Chainlink, as empresas pagam por dados porque suas aplicações dependem literalmente de seu funcionamento correto.
A OpenLedger está tentando algo mais difícil.
Está tentando criar um mercado onde os dados de IA se tornam o produto que as pessoas compram repetidamente.
E é aí que o desafio se torna muito real.
Imagine um agente na OpenLedger raspando tendências das redes sociais. Outro modelo treina nesse conjunto de dados para gerar percepções de marketing. Então, outro agente transforma essas percepções em geração de conteúdo automatizada. Cada camada recebe recompensas OPEN. Tecnicamente, o ecossistema está funcionando exatamente como planejado.
Mas se nenhuma empresa fora do sistema paga por essas percepções, então o que existe é uma circulação impulsionada por incentivos, não necessariamente criação de valor.
É por isso que continuo voltando ao que chamaria de problema da "ilusão de liquidez".
Um marketplace pode parecer extremamente ativo internamente, enquanto ainda carece de compradores genuínos.
A verdade desconfortável é que a maioria dos conjuntos de dados no mundo nunca se torna comercialmente valiosa. As empresas não pagam por dados porque são grandes. Elas pagam porque melhoram um resultado mensurável melhor do que seus sistemas existentes. A relevância importa mais do que o volume bruto.
E é aqui que acho que o sucesso a longo prazo da OpenLedger será realmente decidido.
Não por conta de os contribuintes carregarem dados. Os incentivos provavelmente podem resolver essa parte.
Nem mesmo por conta de agentes de IA conseguirem operar eficientemente em todo o ecossistema.
O verdadeiro teste é se as empresas eventualmente gastam dinheiro real com consistência suficiente para criar demanda externa fluindo para a rede em vez de recompensas circulando principalmente dentro dela.
Para ser justo, não acho que a equipe esteja ignorando essa questão. As parcerias empresariais, direção da API, narrativa de AI Pagável e modelo de compartilhamento de receita sugerem que eles entendem que a sustentabilidade a longo prazo depende de compradores externos, não apenas da participação dos contribuidores.
Eu também acho que incentivos em token fazem sentido durante a fase de bootstrap. Quase toda rede bem-sucedida usou incentivos no início para atrair oferta antes que a demanda chegasse totalmente.
Mas mecanismos de bootstrap se tornam perigosos se o sistema começar a otimizar pela atividade em si em vez de resultados úteis.
Porque eventualmente as pessoas aprendem a cultivar incentivos sem criar valor equivalente.
É por isso que acho que a OpenLedger eventualmente precisa de uma diferenciação mais forte entre dados que geram uso externo mensurável e dados que apenas geram atividade interna. Nem todo conjunto de dados deve ser recompensado igualmente apenas porque existe on-chain.
De certa forma, todo o projeto parece um experimento muito grande em torno de uma pergunta difícil:
Os dados de IA podem se tornar uma verdadeira classe de ativos econômicos com demanda externa recorrente, ou a tokenização simplesmente cria a aparência de liquidez antes que compradores reais cheguem?
Honestamente, ainda não sei.
Mas é exatamente por isso que continuo observando a OpenLedger de perto. Não por causa do hype, mas porque se eles resolverem isso corretamente, não estão apenas construindo mais uma cadeia de IA.
Eles estão construindo um verdadeiro mercado para inteligência de máquina.
E se eles falharem, o ecossistema pode parecer ativo por um longo tempo antes que as pessoas percebam que a maior parte do movimento era interno o tempo todo.
\u003cm-49/\u003e \u003cc-51/\u003e\u003cc-52/\u003e\u003cc-53/\u003e \u003ct-55/\u003e