estou refletindo sobre a atualização do motor de atribuição de janeiro de 2026 há algumas semanas.
na superfície, parece um progresso simples. a openledger atualizou seu sistema de prova de atribuição para manter os links de saída de dados intactos enquanto os modelos de IA são ajustados e evoluídos ao longo do tempo. bom. é exatamente esse tipo de problema de infraestrutura que define ou quebra um sistema de recompensas para contribuintes.
mas quanto mais eu pensava sobre a mecânica por trás dessa atualização, mais desconfortável eu ficava.
é isso que quero dizer.
a prova de atribuição funciona rastreando quais dados de treinamento influenciaram qual saída do modelo. os dados do colaborador A moldaram o modelo em uma direção mensurável, a inferência acontece, a atribuição é calculada, a recompensa flui de volta. o ciclo faz sentido quando o modelo é estático, treinado uma vez, implantado, utilizado.
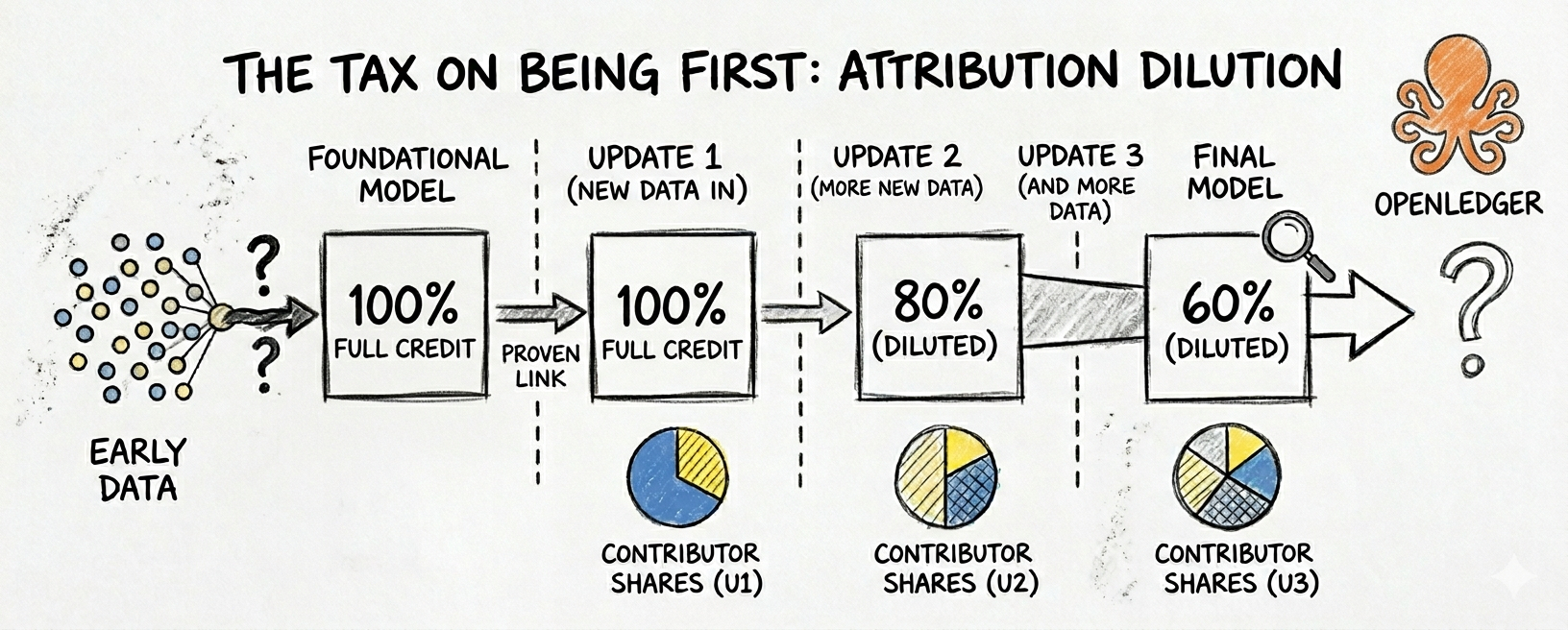
o problema é que os modelos de IA não permanecem estáticos. eles são ajustados. atualizados. melhorados. novos dados são sobrepostos a dados antigos. cada ciclo de ajuste fino desloca o comportamento do modelo gradualmente para longe do que os dados de treinamento originais produziram.
então, o que acontece com a pontuação de atribuição do colaborador A depois que o modelo foi ajustado três vezes pelos colaboradores B, C e D?
a atualização do motor de atribuição diz que os links são "mantidos", mas mantidos como, exatamente? se o modelo se desviou 40% de sua distribuição de treinamento original através de ciclos sucessivos de ajuste fino, o colaborador A ainda está recebendo crédito por 100% de sua influência original? ou a parte da atribuição dele está sendo diluída a cada melhoria subsequente?
eu não consegui encontrar uma resposta pública clara para essa pergunta em lugar nenhum na documentação. e isso importa mais do que parece. 🔍
pense sobre como é o incentivo para o colaborador se a diluição de atribuição for real.
você contribui com dados de domínio de alta qualidade cedo. sua pontuação de atribuição é forte inicialmente. então os desenvolvedores começam a ajustar o modelo. cada melhoria desloca levemente a distribuição de saída. a influência da sua contribuição original nas saídas atuais diminui a cada atualização. seu fluxo de recompensa diminui silenciosamente ao longo do tempo, não porque seus dados pioraram, mas porque o modelo melhorou ao seu redor.
isso é o oposto do que a estrutura de recompensa deveria fazer. deveria criar retornos compostos para os primeiros colaboradores de alta qualidade. se o ajuste fino dilui a atribuição em vez disso, cria um sistema onde ser cedo é na verdade uma desvantagem; você contribuiu antes que o modelo fosse valioso o suficiente para gerar demanda de inferência significativa, e quando a demanda de inferência chega, sua parte de atribuição foi erodida por todos que melhoraram o modelo depois de você.
eu assisti algo semelhante se desenrolar na provisão de liquidez durante o verão da defi.
os primeiros LPs forneceram liquidez antes que os pools tivessem volume. eles assumiram o maior risco. eles tiveram a pior execução. então, quando o volume chegou e as taxas começaram a fluir, os LPs posteriores entraram a melhores preços, enfrentaram menos risco de perda impermanente e capturaram uma parte desproporcional da receita de taxas. ser cedo não foi recompensado. foi diluído pelas pessoas que chegaram depois que o risco já havia sido absorvido.
o problema de diluição de atribuição da openledger tem a mesma forma se minha leitura da mecânica estiver certa.
a atualização de janeiro abordou o rastreamento da evolução do modelo, o que significa que a equipe claramente identificou isso como uma preocupação real que vale a pena engenhar. isso é, na verdade, um sinal que eu considero genuinamente encorajador. você não constrói infraestrutura para um problema que você não acha que existe.
mas a descrição da atualização é vaga o suficiente que eu não consigo dizer se resolveu o problema da diluição ou apenas o rastreou de forma mais precisa. esses são resultados muito diferentes. um significa que os primeiros colaboradores estão protegidos. o outro significa que o sistema agora tem melhor visibilidade sobre quanto eles estão sendo diluídos.
o que eu não estou totalmente convencido é qual realmente foi lançado.
o risco honesto aqui é específico. se a diluição de atribuição é real e se acumula, a openledger eventualmente enfrentará um problema de retenção de colaboradores que não se parece em nada com um problema de aquisição de colaboradores. as datanets vão se encher. o volume de contribuições parecerá saudável. e sob essa superfície, os colaboradores mais antigos e de maior qualidade, aqueles cujos dados realmente moldaram as capacidades fundamentais do modelo, estarão silenciosamente ganhando menos e menos pelo trabalho que mais importava.
isso não é uma falha catastrófica. é uma falha estrutural lenta. o tipo que não aparece nas métricas em cadeia até que os colaboradores que notam isso já tenham parado silenciosamente.
o que eu gostaria de ver da openledger e ainda não vi é uma divisão transparente de como as partes de atribuição evoluem ao longo da história de ajuste fino de um modelo. não uma descrição em paper branco do mecanismo. dados reais em cadeia de uma datanet ao vivo mostrando o que aconteceu com as recompensas dos primeiros colaboradores após a atualização do modelo. essa divulgação específica me diria se a atualização do motor de atribuição de janeiro resolveu o problema ou apenas o nomeou de forma mais precisa.
até que esses dados existam publicamente, estou observando a atividade de ajuste fino em datanets ativas mais de perto do que qualquer outra coisa sobre este protocolo.
