
Eu continuo percebendo como as pessoas falam sobre IA e cripto como se já soubessem para onde tudo está indo, o que é estranho porque a maioria dessa infraestrutura ainda parece inacabada, experimental, quase instável por baixo da superfície. A confiança às vezes soa artificial. Muito limpa. Muito ensaiada. Uma semana, cada protocolo está "construindo o futuro da inteligência", na semana seguinte ninguém se lembra qual problema aqueles sistemas deveriam até resolver. Os mercados se movem rápido assim. As narrativas se movem ainda mais rápido. Mas, por trás de todo o barulho, ainda existem alguns projetos tentando resolver problemas que realmente importam estruturalmente, e a OpenLedger está em algum lugar nessa categoria, embora eu ainda não tenha certeza se o mercado entende completamente o que ela está tentando se tornar.
Ou talvez o mercado o entenda perfeitamente e simplesmente não se importe ainda.
Isso também é possível.
Porque o OpenLedger força as pessoas a entrarem em uma conversa que é menos empolgante do que superinteligência artificial e menos emocionalmente viciante do que especulação impulsionada por memes. Ele faz perguntas sobre propriedade, atribuição, coordenação, roteamento econômico, infraestrutura invisível. Tópicos não glamourosos. Não é o tipo de coisa que as multidões de varejo costumam se reunir. Mas às vezes as camadas menos empolgantes acabam se tornando as mais importantes porque determinam silenciosamente onde o valor flui sob tudo o mais.
E, honestamente, eu acho que a indústria de IA já tem um problema de propriedade, mesmo que a maioria dos usuários esteja muito distraída pela qualidade do produto para perceber isso claramente. Os dados fluem para cima em sistemas centralizados constantemente. O comportamento humano se torna material de treinamento. Conversas se tornam material de treinamento. Preferências se tornam material de treinamento. Indústrias inteiras estão efetivamente gerando combustível informacional para sistemas de IA enquanto a monetização permanece concentrada em um número relativamente pequeno de entidades controlando a infraestrutura de computação e distribuição. As pessoas aceitam isso porque a conveniência geralmente vence. Quase sempre vence. Esse é o padrão desconfortável se repetindo pela internet repetidamente.
Os usuários dizem que querem propriedade até que a propriedade introduza atrito.
Então a conveniência esmaga a ideologia em cerca de cinco segundos.
O crypto aprendeu essa lição repetidamente. A IA provavelmente também aprenderá.
Ainda assim, o OpenLedger parece estar operando sob a suposição de que eventualmente as economias de máquinas se tornam grandes o suficiente, autônomas o suficiente e economicamente significativas o suficiente para que a atribuição não possa permanecer opaca para sempre. E essa suposição é interessante porque desloca a discussão da hype de IA para a responsabilidade econômica. Uma vez que agentes de IA começam a gerar valor de forma independente, a pergunta deixa de ser "quão inteligente é o modelo?" e começa a se tornar "quem recebe pagamento quando o modelo produz algo valioso?"
Isso soa chato inicialmente.
Até você pensar sobre isso por mais tempo.
Porque de repente todo o sistema se torna bagunçado.
Imagine agentes de IA autônomos conduzindo pesquisas, escrevendo código, gerenciando logística, gerando mídia, executando decisões financeiras, negociando contratos, talvez até operando negócios eventualmente. Se esses sistemas forem treinados em conjuntos de dados distribuídos contribuídos por milhões de pessoas, instituições ou máquinas, como exatamente você rastreia a contribuição econômica? Como você mede influência? Como você verifica a proveniência? E talvez a pergunta mais difícil de todas: como você evita que a camada de incentivo em si colapse em manipulação uma vez que a atribuição se torne financeiramente valiosa?
Essa última parte continua me puxando de volta porque os humanos são incrivelmente previsíveis uma vez que recompensas entram na equação. Todo sistema de incentivo eventualmente ensina as pessoas a explorá-lo. É quase inevitável. A internet ficou cheia de cultivo de engajamento porque algoritmos recompensavam atenção. O crypto ficou cheio de mercenários de liquidez porque protocolos recompensavam participação de curto prazo. Sistemas de atribuição de IA provavelmente experimentarão sua própria versão disso. Conjuntos de dados sintéticos fingindo ser valiosos. Manipulação coordenada. Ataques Sybil. Contribuições envenenadas disfarçadas de informações úteis. Atividade falsa otimizada puramente para extração.
E, honestamente, eu acho que muitos protocolos de IA subestimam quão agressivos esses comportamentos se tornam uma vez que incentivos econômicos reais aparecem.
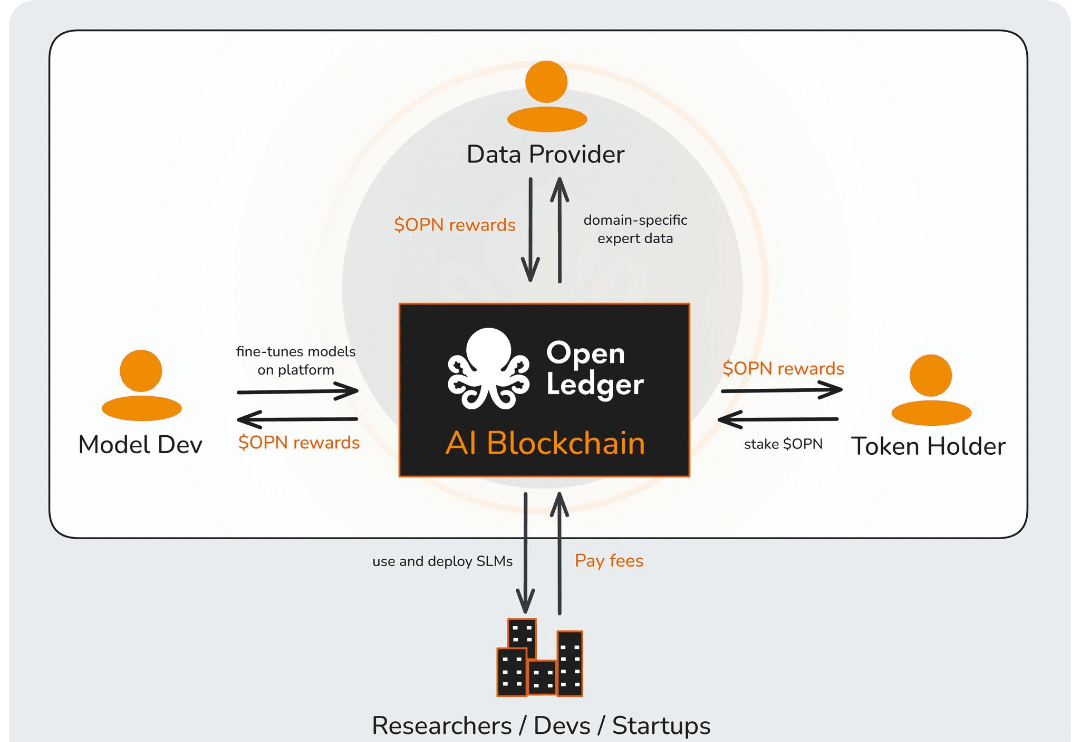
O OpenLedger tenta abordar isso por meio de sua estrutura de Prova de Atribuição e arquitetura Datanet, que é essencialmente uma tentativa de transformar contribuições de dados em ativos econômicos rastreáveis ligados à geração de saída de IA. Em um nível conceitual, a lógica faz sentido. Se um modelo produz valor usando inputs informacionais distribuídos, então os contribuintes deveriam teoricamente participar do upside econômico conectado a essa saída. O protocolo tenta formalizar essa relação em vez de deixá-la totalmente dentro de estruturas corporativas opacas.
Ideia simples.
Realidade complicada.
Porque a atribuição dentro do aprendizado de máquina não é matemática limpa. Modelos absorvem padrões probabilisticamente em enormes espaços de parâmetros. A influência torna-se não linear. Um ponto de dado obscuro pode alterar o comportamento dramaticamente enquanto milhões de outros inputs mal importam. Tentar isolar a contribuição precisa dentro de sistemas neurais pode parecer quase impossível às vezes. Não impossível em teoria talvez, mas operacionalmente feio. Caro também.
Essa é outra coisa que as pessoas evitam falar o suficiente.
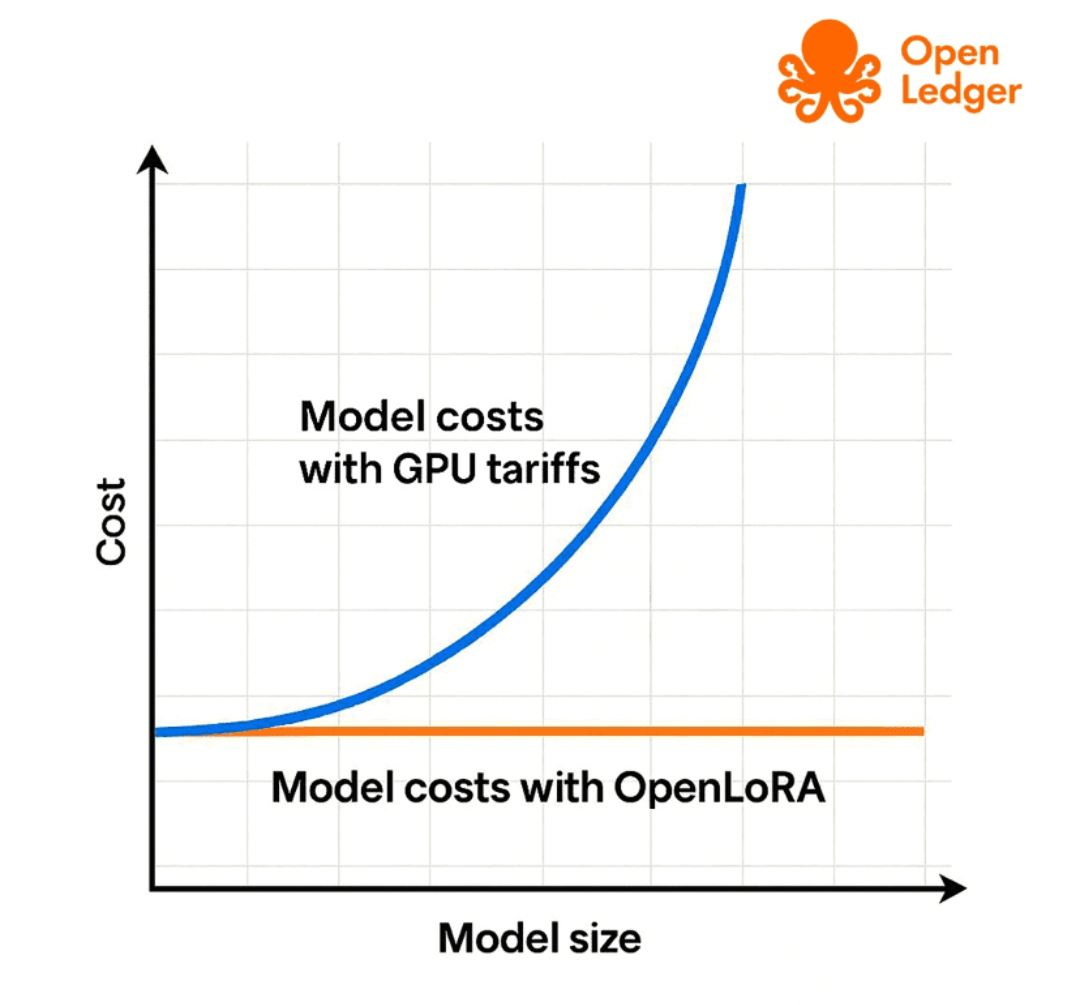
O ônus computacional.
A infraestrutura de IA já consome enormes recursos antes que a descentralização entre na imagem. Treinar modelos é caro. Executar inferência em escala é caro. Armazenamento é caro. Camadas de validação introduzem sobrecarga adicional. Coordenação em blockchain introduz latência. Sistemas de verificação consomem mais recursos. Cada garantia de confiança cria arrasto operacional em algum lugar na arquitetura, e é aqui que a fantasia da descentralização sem atrito geralmente colide com a realidade física.
Sistemas de IA naturalmente otimizam para eficiência.
Blockchains naturalmente otimizam para verificação.
Esses objetivos não se alinham perfeitamente. Às vezes, eles se combatem ativamente.
E eu acho que o OpenLedger entende essa tensão melhor do que algumas das narrativas mais ruidosas de IA flutuando por aí no crypto agora. Pelo menos o protocolo parece mais focado na infraestrutura econômica e na mecânica de atribuição do que em fingir que a descentralização remove magicamente as restrições de engenharia. Não remove. A física ainda existe. A escassez de computação ainda existe. As limitações de largura de banda ainda existem. A internet às vezes fala sobre descentralização como se fosse um feitiço moral capaz de resolver automaticamente todos os problemas de coordenação. Não é. As trocas permanecem inevitáveis.
Sempre.
Talvez seja por isso que eu acho o protocolo mais interessante a partir de uma perspectiva de primeiros princípios do que de uma perspectiva especulativa. Porque a verdadeira questão aqui não é se a IA se torna descentralizada em algum sentido ideológico puro. A verdadeira questão é se as futuras economias de máquinas exigem camadas de coordenação auditáveis uma vez que sistemas autônomos começam a interagir financeiramente entre si em escala.
E eu acho que eles provavelmente fazem.
Não porque a descentralização soa nobre.
Porque sistemas opacos eventualmente criam instabilidade econômica quando valor suficiente flui através deles.
Imagine agentes de IA transacionando continuamente através de mercados financeiros, cadeias de suprimento, sistemas de saúde, infraestrutura legal, operações empresariais. Em algum momento, a proveniência se torna mais do que uma preocupação filosófica. Torna-se infraestrutura contábil. Instituições se importam com rastreabilidade uma vez que a responsabilidade aparece. Empresas se importam com auditabilidade uma vez que o dinheiro se move. Governos se importam uma vez que a conformidade entra na conversa. De repente, os sistemas de atribuição param de parecer opcionais.
Essa possibilidade parece importante.
Mas há outro lado nisso que me incomoda um pouco.
Talvez os usuários simplesmente não se importem.
Talvez a IA centralizada permaneça tão eficiente, tão conveniente, tão operacionalmente superior que as pessoas estejam dispostas a trocar transparência por desempenho indefinidamente. Isso não seria sem precedentes. A maioria dos usuários da internet já depende de sistemas que mal entendem. A conveniência tem uma habilidade aterrorizante de normalizar a opacidade ao longo do tempo. As pessoas raramente examinam infraestrutura invisível a menos que falhe catastroficamente.
E o OpenLedger, de uma forma estranha, está apostando contra essa complacência.
Ou talvez não exatamente contra isso. Talvez o protocolo esteja apostando que, mesmo que os usuários médios permaneçam indiferentes, as economias de máquinas em si eventualmente exigem camadas de responsabilidade sob a superfície, quer os humanos as percebam ativamente ou não. Essa é uma tese mais sutil. Menos ideológica. Mais infraestrutural.
A ironia é que a infraestrutura bem-sucedida muitas vezes se torna invisível. Ninguém pensa em trilhos de pagamento durante uma transação normal. Ninguém pensa em sistemas DNS enquanto navega na internet. Ninguém pensa em orquestração em nuvem enquanto transmite mídia. A infraestrutura desaparece uma vez que funciona de maneira confiável o suficiente. Talvez os sistemas de atribuição evoluam da mesma forma eventualmente. Camadas de coordenação silenciosas sob economias movidas por máquinas, operando continuamente enquanto os usuários interagem apenas com aplicações polidas por cima.
Se isso acontecer, protocolos como o OpenLedger podem importar mais do que as pessoas atualmente assumem.
Ou talvez eles falhem completamente porque a complexidade operacional se torna esmagadora.
Essa possibilidade não deve ser ignorada também.
Há riscos genuínos em toda parte aqui. Sistemas de incentivo tokenizados frequentemente atraem comportamentos de extração antes de comportamentos produtivos. A atenção especulativa pode distorcer as prioridades de desenvolvimento da infraestrutura. Estruturas de governança tornam-se vulneráveis à concentração. Mecanismos de validação de dados tornam-se difíceis de escalar de forma justa. Sistemas de reputação podem ser manipulados. Métricas de atribuição podem se tornar economicamente manipuláveis de maneiras que ninguém antecipa totalmente inicialmente.

E, honestamente, ainda há uma incerteza mais ampla pairando sobre todo o setor de IA. Ninguém realmente sabe como é a arquitetura dominante das futuras economias de máquinas ainda. As estruturas de modelos continuam mudando. A eficiência de hardware continua evoluindo. A pressão regulatória continua mudando. Suposições inteiras sobre treinamento, inferência e propriedade podem parecer ultrapassadas surpreendentemente rápido. Infraestrutura construída muito cedo às vezes resolve problemas temporários em vez de duradouros.
Esse risco parece real.
Mas esperar tempo demais cria um problema diferente porque os incumbentes centralizados solidificam o controle enquanto todos os outros hesitam.
Então, esses protocolos existem em uma zona intermediária estranha onde estão tentando arquitetar sistemas para economias que ainda não existem completamente. Esse é um território perigoso. A especulação em infraestrutura sempre é. Ferrovias eram especulativas uma vez. A infraestrutura inicial da internet parecia irracional uma vez. A computação em nuvem soava desnecessária uma vez. Às vezes, sistemas importantes parecem economicamente absurdos antes que o ambiente circundante amadureça o suficiente para justificá-los.
Outras vezes, eles simplesmente falham.
A parte difícil é dizer a diferença cedo.
E talvez essa incerteza seja exatamente o motivo pelo qual a conversa em torno da infraestrutura de IA parece tão estranha agora. As pessoas falam sobre inevitabilidade constantemente, mesmo que quase tudo permaneça não resolvido sob a superfície. Propriedade não resolvida. Atribuição não resolvida. Descentralização de computação não resolvida. Design de incentivos não resolvido. Governança não resolvida. Restrições comportamentais não resolvidas. No entanto, a confiança permanece estranhamente alta de qualquer maneira, talvez porque os mercados recompensem a certeza mesmo quando a certeza é artificial.
Pessoalmente, eu confio mais em sistemas quando eles reconhecem abertamente as trocas operacionais em vez de fingir que a perfeição existe em algum lugar logo ali.

Resiliência sobre perfeição importa mais.
Sempre foi.
Um sistema não precisa eliminar cada falha para se tornar útil. Ele só precisa permanecer funcional sob pressão enquanto resolve um problema de coordenação real melhor do que as alternativas existentes. Esse limiar importa. E o OpenLedger, no mínimo, parece focado em um problema de coordenação que realmente parece estruturalmente importante em vez de apenas impressionante cosmeticamente.
Quem possui o valor gerado por máquinas?
Essa pergunta continua crescendo à medida que a IA avança.
Porque uma vez que a inteligência se torna economicamente produtiva em escala, a atribuição deixa de ser filosofia abstrata. Torna-se arquitetura financeira. Os sistemas que rastreiam a influência informacional podem silenciosamente determinar quem captura valor sob a próxima geração de economias digitais.
E talvez a maioria das pessoas ainda não perceba.
Talvez as interfaces se tornem tão suaves que os usuários nunca pensem sobre a infraestrutura embaixo delas. Talvez as economias de IA operem em trilhos de atribuição invisíveis da mesma forma que as finanças modernas operam em sistemas de liquidação invisíveis hoje. Máquinas silenciosas. Movimento constante. Muito pouca atenção pública até que algo quebre.
Ou talvez a conveniência vença novamente e modelos centralizados absorvam tudo permanentemente porque os usuários priorizam resultados sobre estruturas de propriedade.
Honestamente, eu não estou totalmente convencido de que qualquer um dos cenários é impossível.
Essa provavelmente é a posição mais realista agora.
Incerteza.
Não a certeza polida que o mercado gosta de fabricar, mas o tipo desconfortável onde múltiplos futuros permanecem plausíveis simultaneamente. O OpenLedger parece uma tentativa de se preparar para um desses futuros antes que ele chegue totalmente. Talvez cedo. Talvez necessário. Talvez ambos.
E há algo estranhamente humano nisso, mesmo dentro de toda essa discussão sobre infraestrutura de máquinas. As pessoas continuam construindo sistemas para resolver problemas que ainda não se materializaram completamente porque esperar pela certeza geralmente significa chegar tarde demais. Às vezes, essas apostas remodelam indústrias inteiras. Às vezes, elas desaparecem silenciosamente sob arquiteturas mais novas que ninguém previu.

Mas a tensão subjacente permanece independentemente.
Conveniência versus propriedade.
Eficiência versus verificação.
Opacidade versus responsabilidade.
A IA vai forçar esse conflito a se tornar evidente eventualmente.
Eu não acho que estamos prontos para quão bagunçado esse processo se torna uma vez que o verdadeiro poder econômico começa a fluir através de sistemas autônomos em escala.
Talvez protocolos como o OpenLedger sejam vislumbres precoces da infraestrutura tentando se preparar para essa realidade antes que o resto da internet perceba que isso já está acontecendo.
@OpenLedger #OpenLedger $OPEN
