Andei estudando a arquitetura do openledger ultimamente, principalmente como eles lidam com a atribuição de dados e como planejam conectar modelos de IA off-chain com coordenação econômica on-chain. Para ser sincero, os diagramas técnicos me deixam com tantas perguntas quanto respostas neste momento.
A maioria das pessoas pensa que o openledger é apenas mais um token de IA + cripto onde você faz upload de um conjunto de dados, o token sobe, e de alguma forma substituímos os corretores de dados centralizados. Mas essa narrativa simplificada esconde o verdadeiro problema de engenharia, que é absurdamente difícil: construir um pipeline verificável desde os dados brutos até as saídas do modelo sem exigir que todos apenas confiem em um servidor central.
há alguns componentes que estou tentando entender.
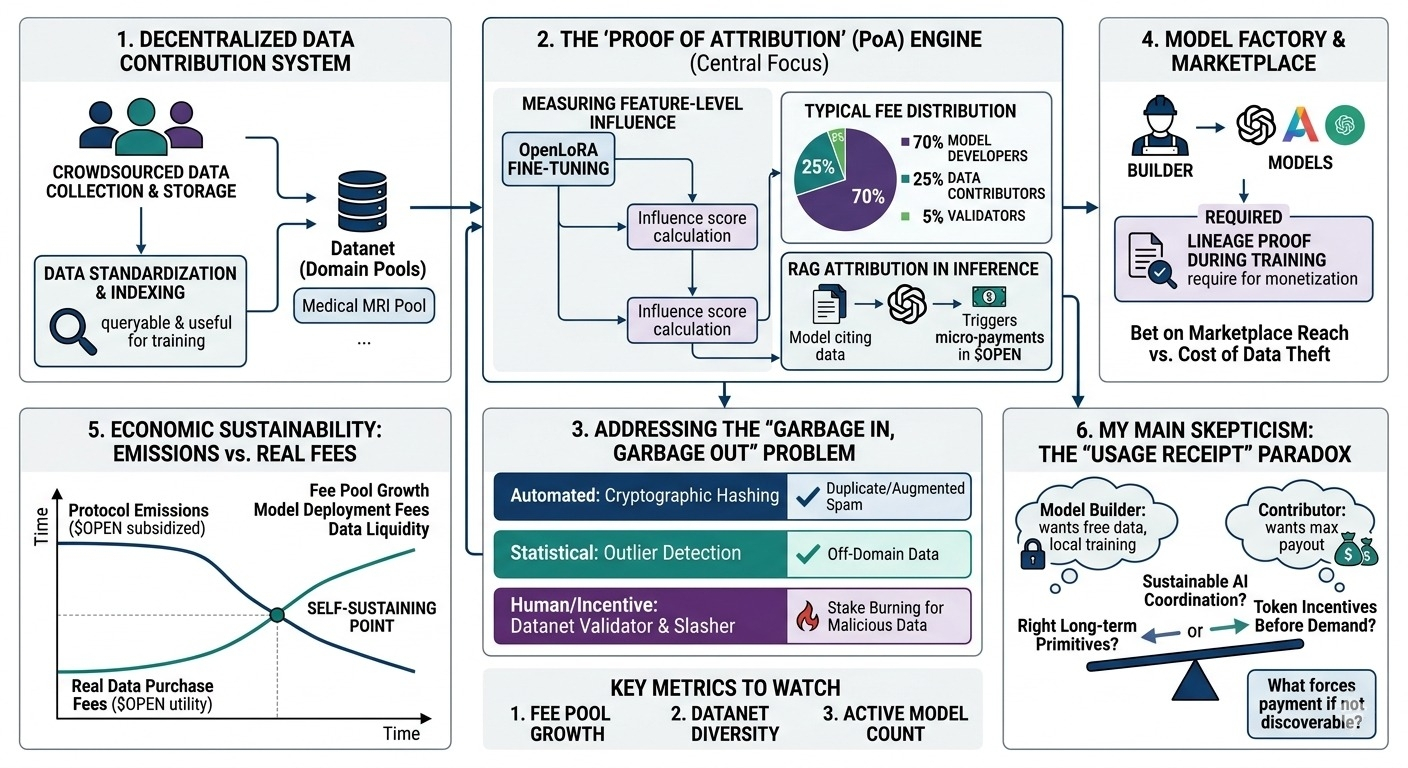
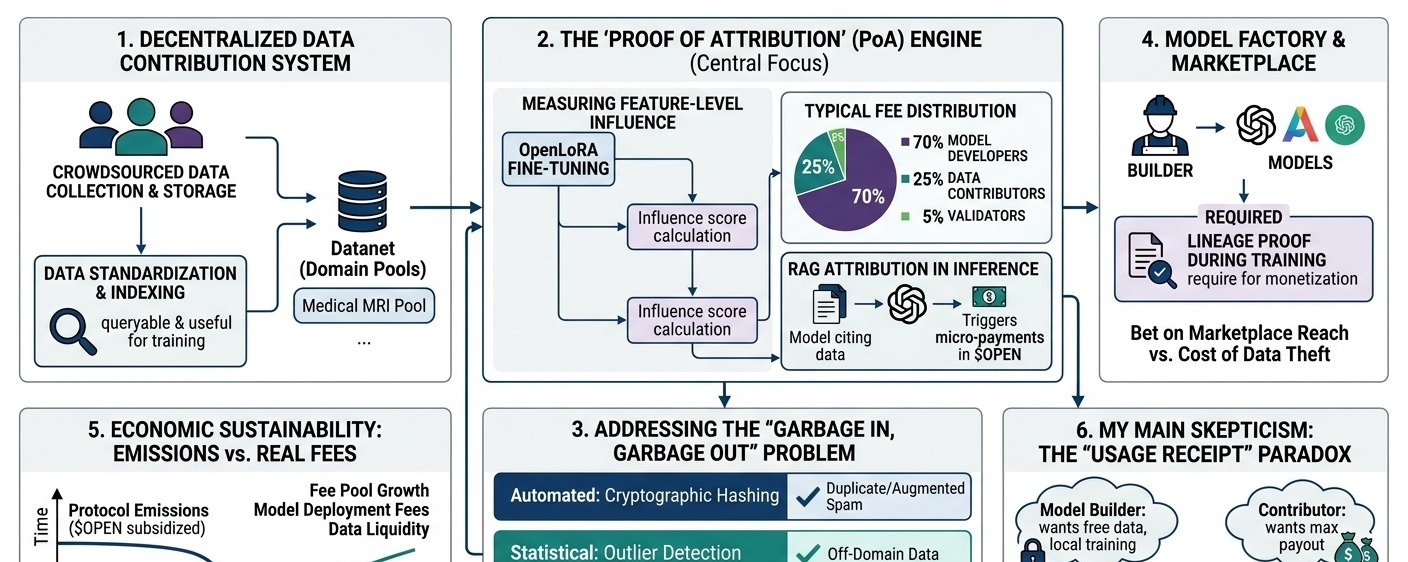
primeiro, o sistema descentralizado de contribuição de dados. eles estão construindo infraestrutura para coleta e armazenamento de dados crowdsourced. o que chamou minha atenção é que não estão apenas despejando arquivos brutos em armazenamento descentralizado; eles estão tentando padronizá-los para que sejam consultáveis e úteis para treinamento.
então temos o mecanismo de atribuição + recompensa. e essa é a parte que eu fico pensando... como você realmente atribui valor a um pedaço específico de dado depois que uma rede neural processou milhões deles?
também existem as dinâmicas do mercado de modelos/dados, onde os desenvolvedores precisam de dados e o protocolo fica no meio. e finalmente, os incentivos do token e a camada de verificação. a cadeia cuida da contabilidade, mas verificar se um modelo realmente usou os dados em larga escala requer um trabalho criptográfico pesado ou hardware confiável que não sei se está totalmente pronto ainda.
então, quem realmente cria valor nesse sistema? os contribuidores fornecem a matéria-prima, mas o valor só é realizado se um construtor de IA pagar para treinar com isso. o protocolo assume que os construtores vão querer comprar dados de forma parcelada de uma rede descentralizada em vez de apenas licenciar enormes corpora pré-limpas de plataformas centralizadas.
minha principal ceticismo é em torno de saber se essa atribuição permanece confiável. imagine um exemplo realista: uma equipe está treinando um modelo de diagnóstico médico especializado. eles precisam de milhares de ressonâncias magnéticas altamente específicas e anotadas. o openledger poderia teoricamente coordenar essa coleta em massa. mas se os incentivos do token estão atrelados ao upload, como você evita uma inundação de dados de spam de baixa qualidade ou levemente aumentados? você precisa de curadores ou cortadores automatizados, o que introduz atrito e gargalos centralizados.
digamos que um construtor de modelo puxe aquele conjunto de dados de ressonância magnética da rede, treine seu modelo localmente e o envie. como o openledger realmente faz cumprir o recibo de uso? se eles dependerem de auto-relato, há um grande desalinhamento de incentivos. os construtores querem dados gratuitos, os contribuidores querem o máximo de pagamento.
isso leva à clássica tensão dos tokens: emissões vs utilidade real. no início, as emissões do protocolo vão subsidiar as recompensas. os contribuidores vão ser pagos em tokens mesmo que ninguém esteja comprando os dados. esses incentivos podem permanecer sustentáveis ao longo do tempo uma vez que as emissões se esgotem? se a demanda real não se materializar, tudo isso desmorona em um disco rígido descentralizado de conjuntos de dados não utilizados.
não tenho uma conclusão perfeita aqui. quero acreditar que uma camada de coordenação de IA sustentável é possível, mas é difícil dizer se o openledger está construindo os primitivos certos a longo prazo ou apenas anexando incentivos de token à infraestrutura de IA antes que a demanda real exista.
assistindo:
- a proporção de emissões do protocolo em relação às taxas de compra de dados reais (quando a rede realmente se torna auto-sustentável?)
- taxas de rejeição de conjuntos de dados e disputas (isso vai sinalizar quanto spam está atingindo a camada de contribuição)
- presença de compradores de dados recorrentes (não apenas pilotos subsidiados por token de uma única vez)
se eles resolverem o problema de atribuição sem tornar a rede insana lenta ou cara, é genuinamente interessante. mas até lá, o que realmente força um construtor de modelo a seguir as regras e pagar uma vez que eles tenham os dados?