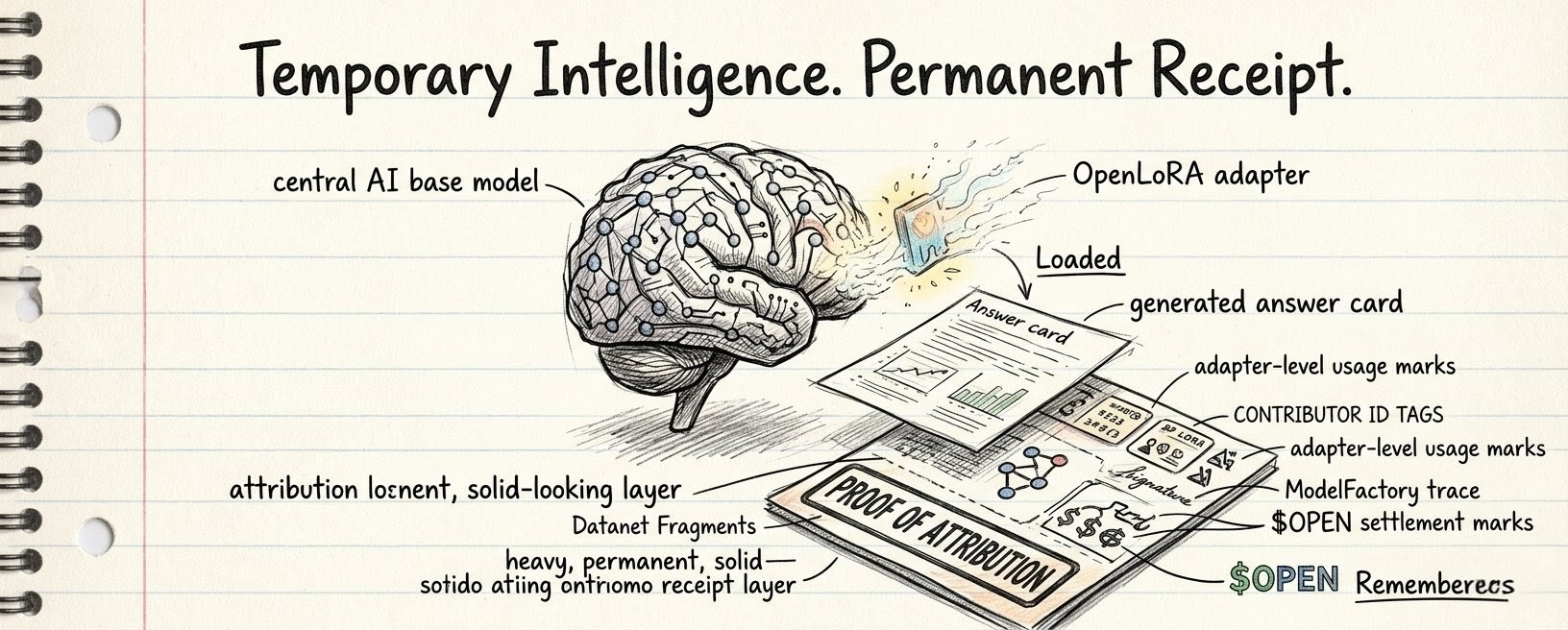

OpenLoRA inside OpenLedger (@OpenLedger ) keeps making me think about intelligence that does not stay loaded.
not a full model sitting there like some permanent brain. not this heavy thing that always exists in one fixed shape. more like a small specialization waking up for a narrow job, bending model behavior, then slipping back out of the active compute path like it was never trying to become the whole system.
that feels useful, obviously.
but it also feels suspicious in a way i can’t ignore.
because if an adapter only appears for a moment, does the OpenLedger system still remember what it changed?
or is temporary just another word for easy to erase?
that is the part that keeps bothering me on OpenLedger. OpenLoRA sounds clean when people describe it from the compute side. cheaper specialization. less waste. many fine-tuned paths without forcing every narrow skill to become its own giant expensive model. fine. that matters. decentralized AI cannot pretend GPU cost is some background detail. if specialization is too expensive, only the big centralized platforms get to specialize at scale.
but inside OpenLedger, OpenLoRA is not just a cost trick. at least that is not the interesting part to me.
the interesting part is that temporary intelligence still leaves behavior behind.
the whole point is that specialization does not have to become a full permanent model every time. it can load as a smaller adapter, adjust the model for one narrow need, then leave the active compute path. not a new giant model identity. not some heavy standalone machine. just a temporary weight shift that made the model act differently for that moment.
and once the model acts differently, something happened.
that sounds obvious, but AI systems are very good at pretending the middle never mattered.
on openLedger, adapter can load because a user needs DeFi reasoning, medical context, code understanding, or some narrow Datanet-shaped skill that the base model does not carry well enough on its own. the model suddenly gets sharper in one direction. not forever maybe. not as a new permanent identity. just for that request, that specialization path, that brief little moment where the base model was not enough.
and then what?
does the adapter leave a trace in Proof of Attribution? does the Datanet behind that specialization stay attached to the behavior it helped create? does the model path record that this was not just “the model,” but the model plus a temporary weight shift, plus compute, plus a data history sitting behind that adapter?
or does the behavior walk away clean?
that would be the old problem wearing better infrastructure.
because normal AI already does this trick all the time. it hides the middle. users see one answer and assume one model made it. maybe there were retrieval layers, fine-tunes, routing systems, prompt wrappers, human labels, hidden tools, whatever. but the answer arrives smooth, and smoothness makes everything underneath feel irrelevant.
OpenLedger cannot afford that kind of smoothness.
not if the whole point is attribution.
OpenLoRA makes this more delicate because the specialization is not always loud. it might not look like a new model. it might not announce itself to the user. it might just bend the behavior a little. a better risk explanation here. a cleaner code suggestion there. a trading signal interpreted with less generic noise. the adapter does not need to dominate the whole response to matter.
sometimes a tiny weight shift is the whole reason the model stopped sounding generic.
that line feels small but it opens the whole thing up.
because if the adapter helped, then something helped before the adapter ever loaded. some Datanet shaped it. some contributor’s data gave it signal. some ModelFactory path may have made it usable. compute loaded it at the right moment. the active model path carried it for one narrow task. and if OpenLedger ($OPEN ) later touches usage or reward logic, the system cannot pretend the adapter was just a temporary ghost.
temporary should not mean unaccountable.
that is probably the sharpest way i can say it.
and honestly, this is where OpenLoRA feels more native to OpenLedger than it would inside a normal AI platform. in a normal platform, temporary specialization is mostly an efficiency story. reduce cost, improve task performance, serve more users. good, but boring. the platform still owns the whole surface. contributors still disappear. data influence still becomes fog. the adapter helps the model behave better and nobody outside the platform knows what it borrowed.
inside OpenLedger, the adapter path becomes part of the attribution question.
who made the temporary skill possible?
which Datanet gave it enough domain shape?
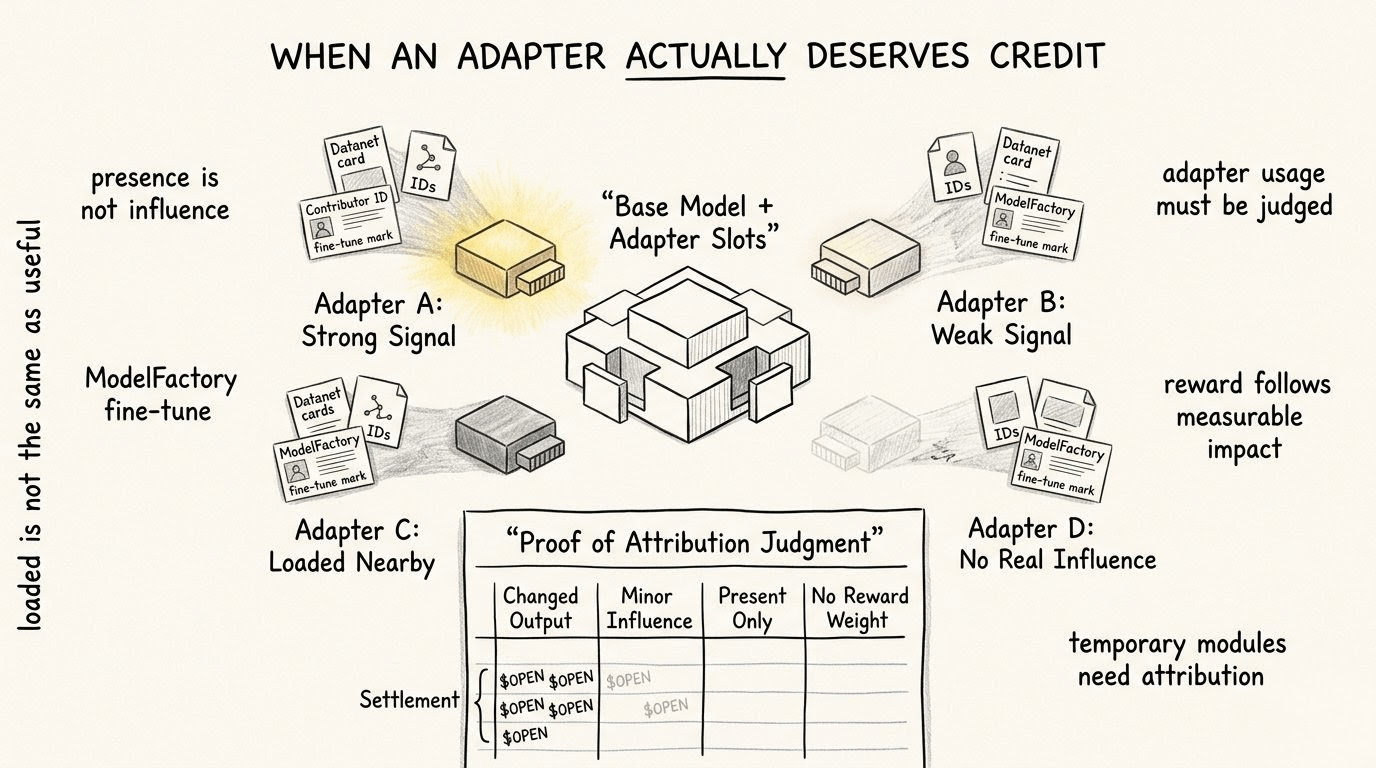
did the adapter actually bend the model, or was it just loaded nearby?
did it change the response enough to deserve weight in the attribution path?
and if it did not, should the system count it at all?
that last question matters because OpenLoRA could otherwise become another place where people confuse presence with impact. an adapter was loaded, okay. but did it matter? did it shape the model behavior? did Proof of Attribution see real influence, or just a component sitting in the path like decoration?
not every loaded thing deserves credit.
not every specialization earns just because it appeared.
that is the uncomfortable side. people like specialization because it sounds powerful. they like adapters because they sound efficient. they like the idea of many tiny AI skills available on demand. but once model usage becomes tied to attribution and OpenLedger flows, the system needs more than “adapter was used.” it needs to know whether the adapter changed anything worth counting.
because what if it didn’t?
what if the adapter showed up, cost compute, looked important in the stack, but the model barely leaned on it?
then calling it influence would be fake.
otherwise temporary intelligence becomes a loophole.
load an adapter, claim importance, disappear.
no. that cannot be the economy.
OpenLedger’s architecture has to make the temporary path legible enough that the adapter cannot become a black box inside the anti-black-box system. because that would be funny in the worst way. building an attribution chain, then letting the most flexible compute layer become the place where influence hides again.
the hidden part always tries to come back.
and maybe this is why OpenLoRA keeps feeling strange to me. it makes the model less fixed. less singular. less like one brain and more like a body that keeps borrowing small nervous systems for different tasks. a base model can sit there, but the useful behavior may come from these narrow temporary attachments.
so when the model behaves differently, what are we even tracking?
the base model?
the adapter?
the Datanet that shaped the adapter?
the compute that loaded it at the right time?
the builder who made the adapter available?
the demand that exposed whether it was useful?
messy question. good question.
because future AI probably does not look like one giant model doing everything. it looks more modular, more task-shaped, more temporary. little skills loading and unloading. domain-specific behavior appearing only when needed. cheaper, faster, less wasteful. but that also means the attribution problem becomes more fragmented, not less.
the more modular intelligence gets, the easier it is for credit to fall between the pieces.
OpenLoRA forces OpenLedger to deal with that.
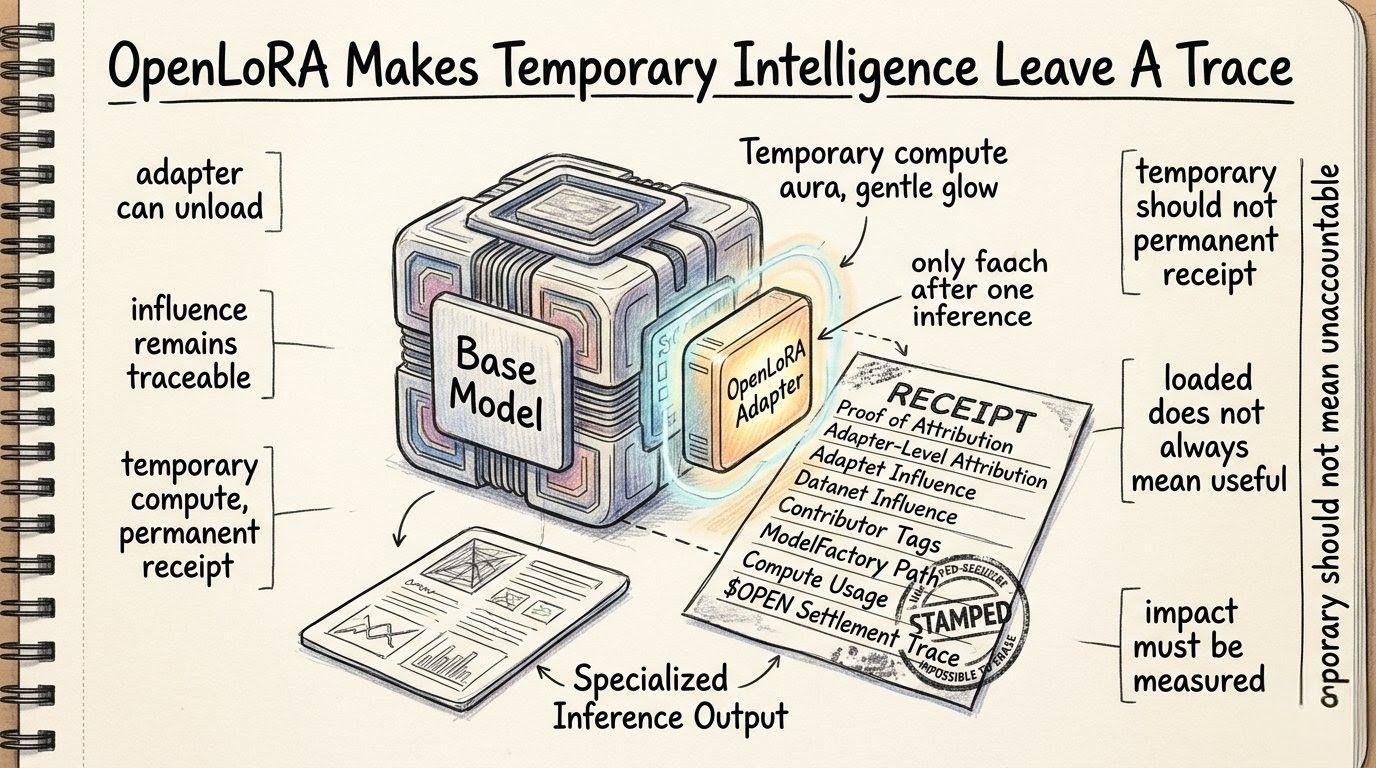
a temporary adapter can be economically real even if it is computationally temporary. it can shape one response. it can help one workflow. it can turn a generic model into something useful for one request. and if that request creates value, the adapter’s influence should not vanish just because the adapter is no longer loaded.
on openLedger, Proof of Attribution has to be sharper than normal provenance talk.
not only tracking big obvious training histories. not only saying this Datanet contributed to that model in some broad way. but following the smaller moment where a LoRA adapter becomes the difference between generic behavior and useful behavior.
what did this adapter add?
what did it borrow from the data layer?
what did it change in the model?
and did that change matter enough to stay in the trail?
i like that because it makes OpenLedger’s AI economy feel less theatrical. the system is not just rewarding grand contributions. it has to handle small influence. temporary influence. partial influence. the kind that normal platforms erase because it is too annoying to explain.
but AI value is often annoying like that.
a little domain signal. a slight behavior shift. a narrow adapter. one moment where the model worked because it was briefly not itself.
briefly not itself. that sounds weird, but maybe that is OpenLoRA’s whole tension.
the model becomes something else for a moment, and OpenLedger has to remember the moment.
not forever in a dramatic way. just enough to know what happened.
because if it does not, then the behavior becomes clean in the wrong way again. the user sees usefulness. the builder sees performance. maybe the marketplace sees demand. but the contribution trail behind the adapter fades out. the Datanet becomes background. the people who made the specialization possible become invisible. and the system starts repeating the same old AI habit where usefulness rises upward and credit sinks somewhere nobody can reach.
that is what OpenLedger is trying not to become.
so OpenLoRA is not just about cheaper specialized models. it is about whether specialized behavior can stay accountable when it is modular, temporary, and easy to swap. because the future probably has a lot of this. adapters for finance, adapters for science, adapters for regional data, adapters for code, adapters for workflows that need one narrow skill for one narrow action.
and each one will ask the same boring hard question.
did you actually matter?
some adapters will. some will barely change anything. some will probably get loaded because a path thought they were useful and then prove almost silent. some will carry real Datanet influence and become the reason the model behaved well. the system has to tell the difference, or else the adapter layer becomes another place where credit gets blurry.
and maybe that is the part people will underestimate. not the adapter loading. not the compute saving. the judgment after it. because a temporary skill can look valuable from the outside just because it appeared at the right moment. but appearance is not influence. OpenLedger cannot let “loaded” become the same thing as “useful.”
OpenLedger’s stronger version is the one where even temporary specialization leaves a record. not a giant dramatic record maybe. not some huge public story every user has to read. just enough memory for the value path to stay honest.
because if intelligence is going to become modular, then accountability has to become modular too.
that is the part i keep coming back to.
the adapter can disappear from the compute path.
the influence should not.
and maybe that is the quiet beauty of OpenLoRA inside OpenLedger (#OpenLedger ). it lets intelligence become lighter without letting it become weightless. it lets models specialize without pretending specialization came from nowhere. it lets temporary behavior still carry a payable history when OpenLedger starts moving through usage and reward.
not permanent model identity.
not invisible magic either.
something in between. a borrowed skill with a trace.
and honestly, that feels closer to where AI is going than the old fantasy of one model knowing everything forever. the future might be full of temporary brains. little pieces loading, helping, leaving.
OpenLedger’s question is colder.
when they leave, what do they still owe?