
Todo mundo está construindo a mesma coisa agora.
Mercados de dados de IA. Redes de contribuição. Infraestrutura de treinamento. A narrativa é idêntica: mais dados → melhores modelos → maiores valuations. História limpa. Lógica familiar. Chato pra caramba.
Eu acho que @OpenLedger está acidentalmente construindo algo mais estranho.
E o mercado ainda não sacou isso.
O Problema que Ninguém Está Falando
Aqui está o que eu continuo percebendo: as empresas de tecnologia são obcecadas pelo que os sistemas de IA podem aprender, mas gastam quase zero tempo pensando sobre o que esses sistemas deveriam lembrar.
Essa distinção não importava quando a IA gerava poemas ou respostas de chatbots. Importa muito quando a IA começa a influenciar decisões de empréstimos, fluxos de trabalho de conformidade, verificação de identidade ou sistemas de consultoria financeira.
Porque uma vez que a inteligência toma decisões reais, a memória deixa de ser um ativo passivo. Ela se torna uma superfície de responsabilidade.
A maioria das pessoas enquadra a #OpenLedger como infraestrutura para a contribuição de dados de IA. Contribuintes fornecem conjuntos de dados. Construtores os consomem. Modelos melhoram. $OPEN coordena incentivos. Manual padrão de criptomoeda.
Mas eu acho que a verdadeira história é ao contrário.
E se o próximo gargalo da IA não for aprender — for esquecer?
Pense sobre como a IA moderna realmente funciona. Uma vez que os dados são absorvidos em processos de treinamento, embeddings, camadas de recuperação ou comportamentos ajustados, a remoção não é como deletar um arquivo. A informação se difunde.
O desaprendizado da máquina é um campo de pesquisa inteiro que admite silenciosamente algo desconfortável: ensinar máquinas é fácil. Fazer com que elas esqueçam com precisão é quase impossível.
Isso era tolerável quando a IA ficava em caixas de areia. Não mais.
Os reguladores estão se tornando mais astutos. As empresas estão se tornando cautelosas. A IA está se movendo para fluxos de trabalho envolvendo pagamentos, identidade, comunicações internas, conformidade — superfícies onde erros custam dinheiro real.
E quando os sistemas tocam operações reais, a questão muda de "este modelo pode funcionar?" para "o que exatamente este modelo está levando adiante?"
Questão diferente. Consequências maiores.
O Jogo de Infraestrutura Oculta que a Maioria das Pessoas Está Perdendo
Aqui é onde a OpenLedger fica interessante:
Se a atribuição se tornar persistente e economicamente significativa, então a memória retida não é mais uma infraestrutura gratuita. Ela se torna um objeto econômico gerenciado.
Isso inverte completamente a estrutura de incentivos.
Neste momento, os sistemas de IA retêm informações porque a retenção é útil. Melhor personalização, melhor continuidade, melhores resultados. A suposição subjacente é simples: manter o contexto é sempre benéfico.
Mas em uma rede onde os contribuintes podem ser identificados e os fluxos de valor estão ligados à proveniência, a memória começa a ter custo.
E uma vez que a memória tenha custo, esquecer se torna racional.
Imagine um assistente de IA empresarial treinado em interações de clientes proprietárias. Seis meses depois, um cliente revoga as permissões de dados. Ou as regulamentações mudam. Ou a empresa decide que certas interações históricas criam exposição legal.
A questão não é apenas deletar logs. É decidir se a inteligência moldada por essas interações deve permanecer ativa operacionalmente.
A saúde torna isso ainda mais feio. Os sistemas financeiros também.

Por que essa narrativa importa agora
O boom da adoção de IA está criando uma crise de confiança que ninguém quer discutir.
As instituições não são alérgicas à IA. Elas são alérgicas à incerteza que não podem operacionalizar. E a memória retida sem atribuição cria exatamente essa incerteza.
É por isso que eu acho que $OPEN pode não estar competindo onde a maioria das pessoas pensa.
Não computação. Não acesso ao modelo. Não marketplaces de dados.
Infraestrutura para negociar o que os sistemas de IA podem lembrar, por quanto tempo eles lembram e quem é reconhecido economicamente enquanto essa memória permanece ativa.
Essa é uma tese muito menos glamourosa. E é exatamente por isso que pode importar.
O Caso Bull
Se essa tese se concretizar:
Cada implantação de IA empresarial precisa de infraestrutura de atribuição.
Os efeitos de rede se acumulam à medida que mais sistemas se integram.
A utilidade do token cresce além da especulação em uma necessidade operacional.
OpenLedger se torna a "tubulação chata" que captura um valor imenso.
As narrativas de infraestrutura envelhecem bem. Pergunte aos primeiros investidores em nuvem.
O Caso Bear
O risco de execução é real. A atribuição é tecnicamente difícil. O esquecimento da máquina é realmente complicado.
A economia do token pode se complicar demais. A infraestrutura privada muitas vezes vence porque a simplicidade operacional supera a pureza conceitual.
E há uma questão de demanda: por que a pressão orgânica sustentada existe em vez de uma especulação temporária?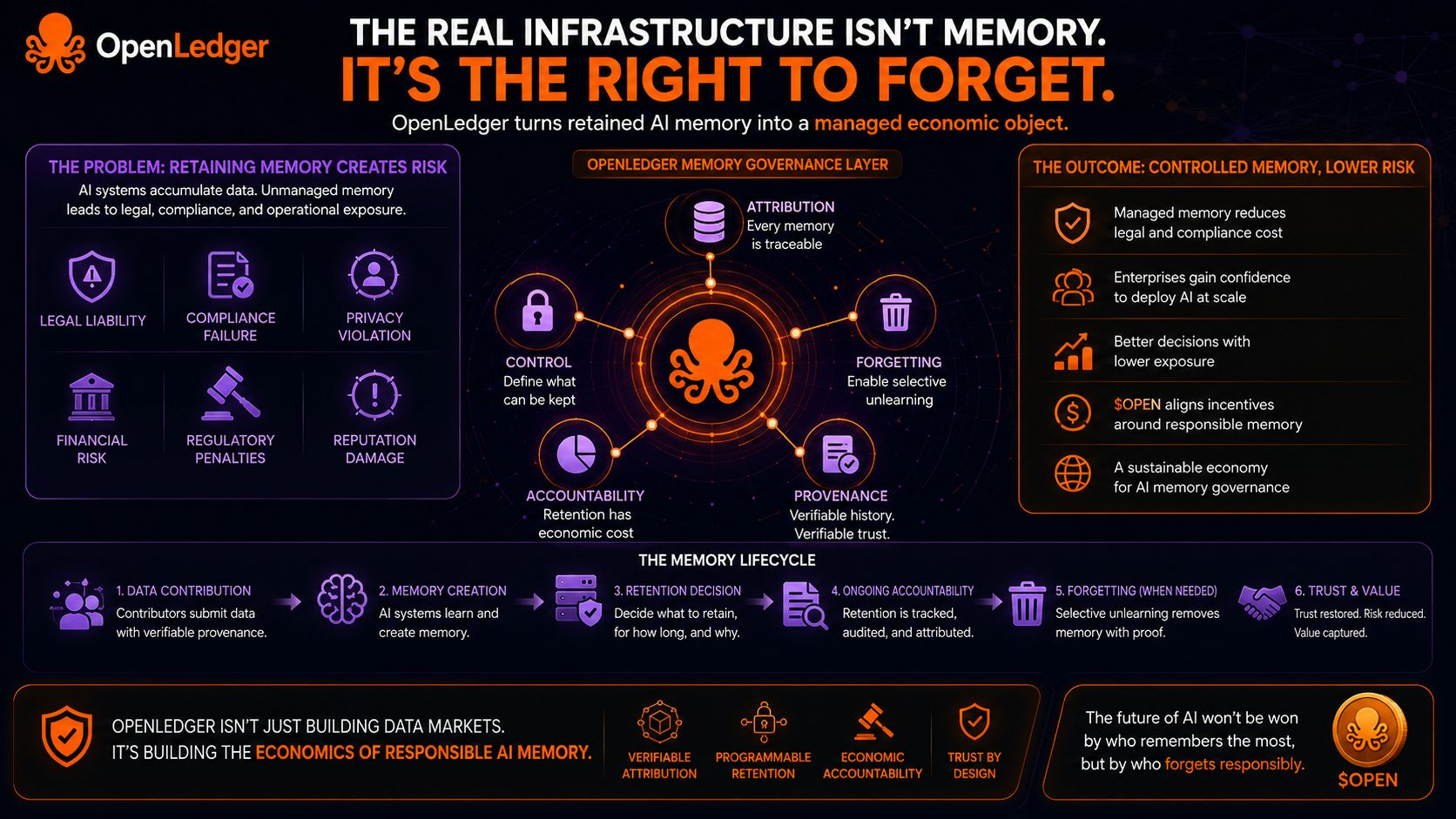
A Conclusão Contrária
O mercado de IA ainda se comporta como se a inteligência fosse o ativo escasso.
Estou cada vez mais pensando que a responsabilidade pode se tornar mais escassa do que a inteligência.
Se estou certo, @OpenLedger não está apenas tokenizando contribuições de dados. Está construindo infraestrutura de governança de memória para sistemas de IA que precisam esquecer corretamente.
Pergunte a si mesmo: em 12 meses, as empresas se importarão mais com a qualidade do modelo ou com a responsabilidade das decisões?
Porque se for o último, estamos todos avaliando mal o que realmente importa na infraestrutura.
#OpenLedger #AIInfrastructure #CryptoAi #DecentralizedAI #DataEconomy