QUANDO OS DADOS COMEÇAM A EXIGIR VALOR : O EQUILÍBRIO SILENCIOSO DO OPENLEDGER ENTRE LIBERDADE E FILTROS
Honestamente, a primeira impressão de sistemas como esse é sempre a mesma — “muitas regras, muito controle, muitos limites.”
Mas quanto mais você se aprofunda no OpenLedger, mais começa a parecer menos uma restrição… e mais uma arquitetura intencional. E essa diferença importa.
A maneira como eu vejo @OpenLedger após ler a documentação é simples:
isso não é apenas mais um projeto de infraestrutura de IA — é um experimento em torno de uma ideia central:
Os dados podem se tornar algo que as pessoas ganham através da contribuição em vez de algo que as plataformas simplesmente extraem?
E quando você pensa bem sobre isso… essa ideia é muito maior do que parece.
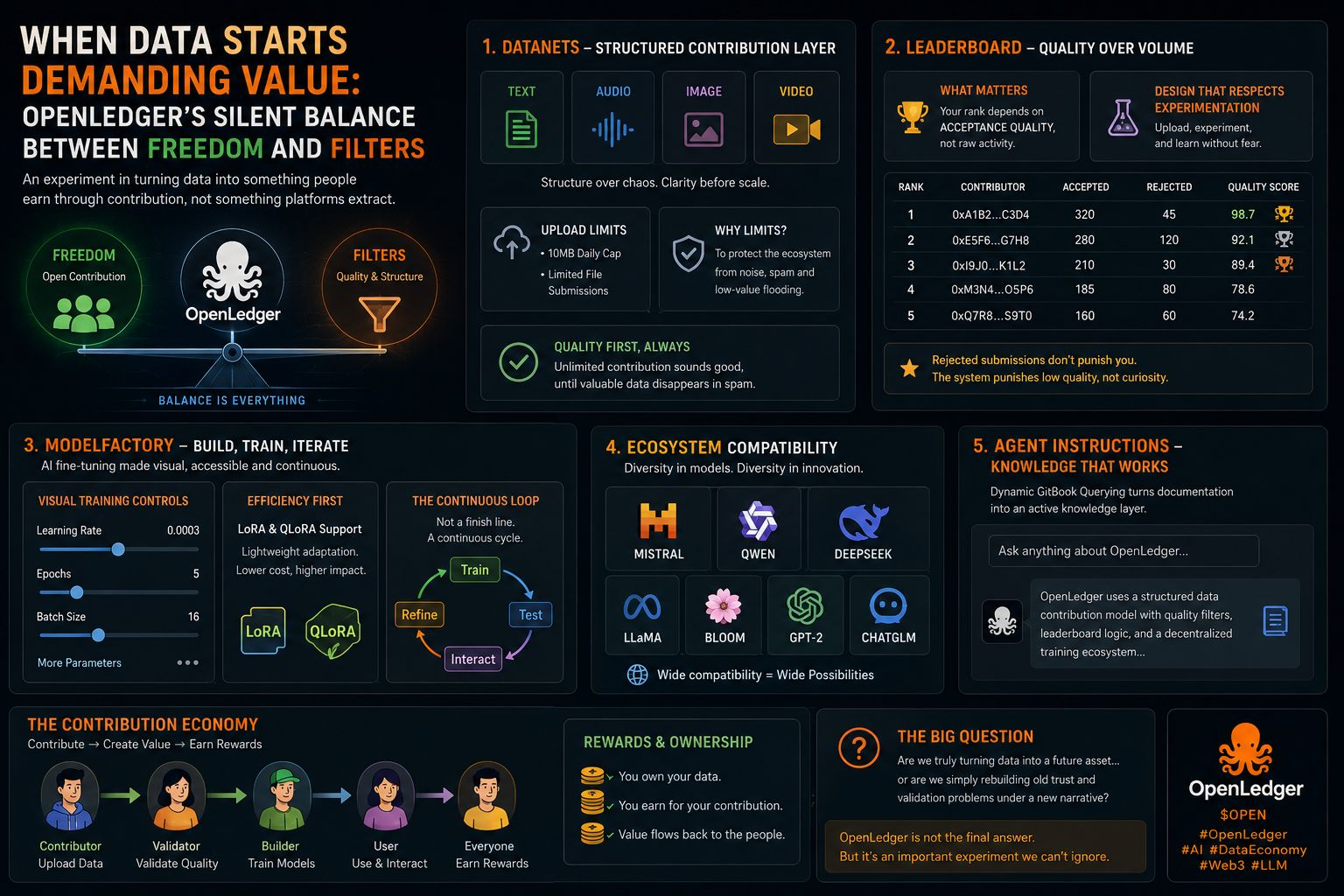
Primeiro vem a camada de contribuição dos Datanets.
É aqui que as coisas se tornam interessantes porque a OpenLedger não segue a mentalidade usual de "carregar tudo livremente" do Web3.
Em vez disso, o sistema força estrutura.
Texto permanece texto.
Áudio permanece áudio.
Imagens permanecem imagens.
A princípio parece restritivo, quase estranho para um ecossistema descentralizado.
Mas talvez o objetivo aqui não seja máxima liberdade — talvez seja manter clareza antes que a escala destrua a qualidade.
Até os limites de upload contam a mesma história.
Limites diários de 10MB, envios de arquivos limitados… parece pequeno no papel, certo?
Mas isso não é realmente sobre limitar colaboradores.
Parece mais proteger o ecossistema de se tornar um oceano de ruído sem sentido.
Porque contribuição ilimitada soa bonita… até que dados valiosos desapareçam dentro do spam.
E então vem a lógica do leaderboard — que honestamente me surpreendeu mais.
Normalmente, plataformas recompensam volume.
Carrega mais. Posta mais. Faz mais.
Mas a OpenLedger muda silenciosamente essa mentalidade.
Sua posição depende mais da qualidade de aceitação do que da atividade bruta.
Você pode fazer upload infinitamente, mas se os dados não têm valor, o sistema simplesmente se recusa a se importar.
Estranhamente… submissões rejeitadas não destroem sua classificação.
E essa pequena escolha de design diz muito.
Isso significa que a experimentação ainda é permitida.
A plataforma pune comportamentos de baixa qualidade — não a curiosidade.
Então toda a atmosfera muda assim que você chega ao ModelFactory.
Essa parte parece menos como um painel e mais como a verdadeira ambição da OpenLedger.
Porque eles estão tentando mover a afinação de IA para longe de linhas de comando pesadas em pesquisa para um fluxo de trabalho visual que as pessoas possam realmente interagir.
Taxa de aprendizado.
Épocas.
Tamanho do lote.
Tudo ajustável visualmente.
Na superfície parece amigável para iniciantes.
Mas, por baixo, é realmente sobre baixar a barreira sem remover a mecânica.
Essa é uma distinção importante.
O suporte a LoRA e QLoRA torna a direção ainda mais clara.
A afinação completa hoje é cara, pesada em recursos e irrealista para a maioria dos construtores.
Então, ao invés de forçar a rota mais pesada, a OpenLedger opta por uma adaptação leve.
Prático em vez de performático.
E o fluxo de treinamento em si é construído quase como um loop em vez de uma linha de chegada:
Treinar → Testar → Interagir → Refinar.
Esse ciclo contínuo é provavelmente uma das partes mais inteligentes do sistema.
O ecossistema LLM suportado conta outra história também.
Mistral, Qwen, DeepSeek, LLaMA, BLOOM, GPT-2, ChatGLM — não é uma coleção aleatória de modelos.
É cobertura do ecossistema.
Porque apoiar apenas modelos de elite cria um espaço de experimentação estreito.
Compatibilidade ampla cria diversidade no desenvolvimento em si.
E honestamente… uma imagem engraçada continua aparecendo na minha cabeça enquanto olho para tudo isso ..
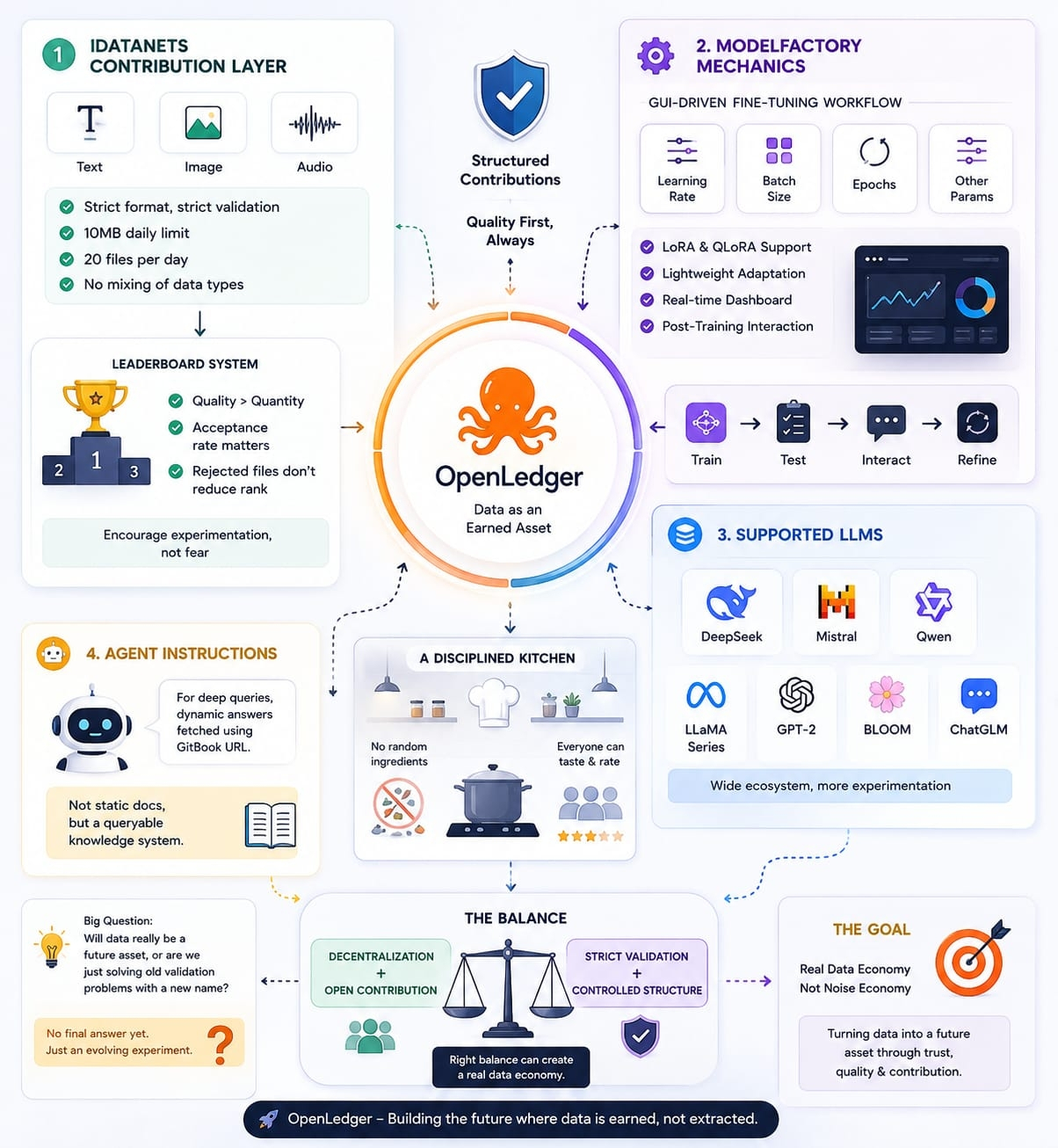
A OpenLedger parece uma cozinha altamente disciplinada.
Ninguém é permitido jogar ingredientes aleatórios na panela.
Tudo é medido, filtrado, validado.
Mas uma vez que o prato final está pronto — todos podem provar, testar e julgá-lo.
Então não… apenas vibrações não vão sobreviver aqui.
E talvez esse seja o ponto.
Até a seção de "Instruções do Agente" sugere silenciosamente algo mais profundo.
A documentação não está mais sendo tratada como material de leitura estático.
Através de consultas dinâmicas do GitBook, isso se torna mais como uma camada de conhecimento ativa do que documentos passivos.
E quando você conecta todas essas peças, uma tensão se torna impossível de ignorar:
A OpenLedger está tentando ficar exatamente entre descentralização e estrutura controlada.
Contribuição aberta de um lado.
Validação rigorosa por outro lado.
Manter essas duas forças equilibradas é incrivelmente difícil.
Mas se esse equilíbrio realmente funciona… então talvez isso se torne mais do que apenas mais uma plataforma de dados de IA.
Talvez isso se torne uma versão inicial de uma verdadeira economia de contribuição.
E honestamente, é aí que a pergunta maior começa:
Estamos realmente transformando dados em um ativo do futuro…
ou estamos simplesmente reconstruindo velhos problemas de confiança e validação sob uma nova narrativa?
Eu não acho que haja uma resposta final ainda.
Mas como um experimento em evolução, a OpenLedger definitivamente não é algo a ser ignorado.