I was sitting outside a small electronics shop a few days ago while the owner argued with a supplier over a worn notebook full of handwritten balances. Pages folded at the corners. Ink fading in places. Both of them trying to trace who delivered what and which payments were still pending.
The interesting part was that nobody was confused about the products themselves.
The confusion was around records.
Who contributed. Who deserved payment. What could actually be verified.
That stayed in my head later while reading OpenLedger’s architecture documents because the deeper I went into the system, the clearer something became.
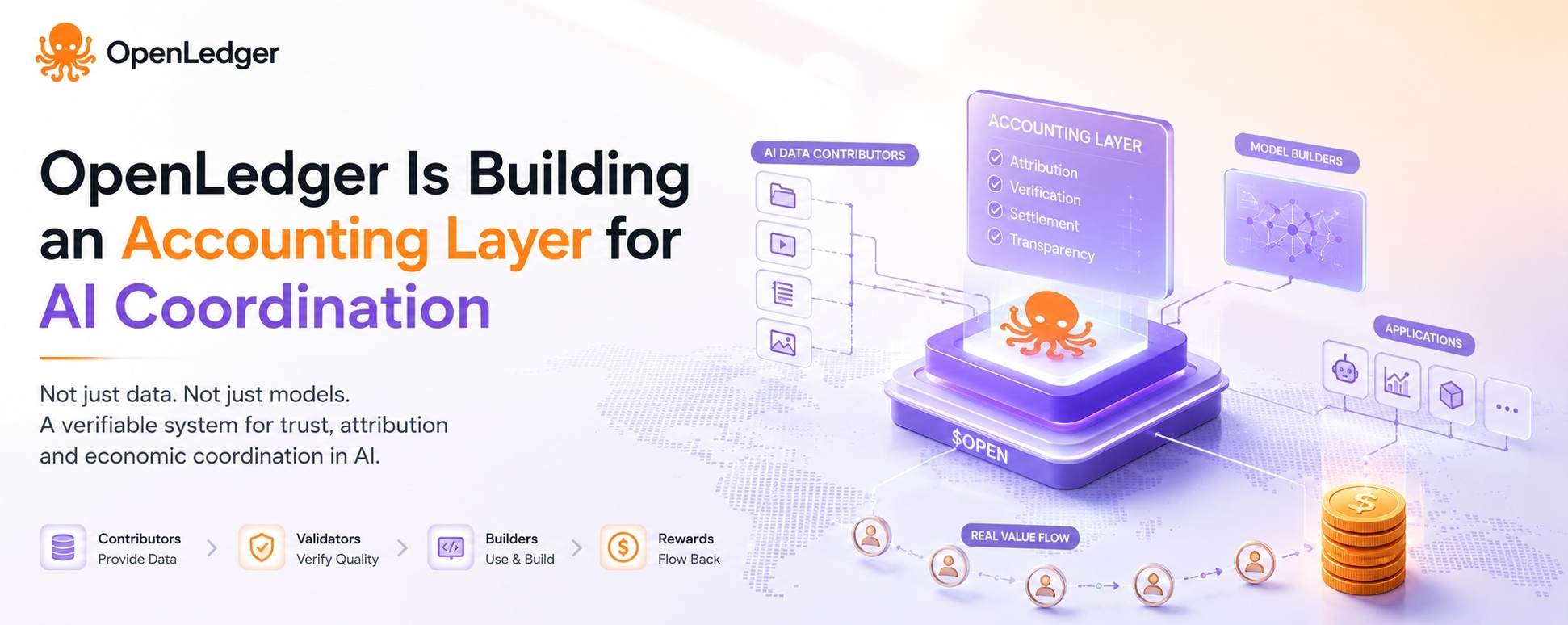
OpenLedger is not fundamentally a data marketplace.
It is an accounting system for AI coordination.
The data layer matters, obviously. But the real thing holding the network together is attribution.
Most people still explain OpenLedger through the usual crypto AI framing: contributors upload datasets, builders consume them, rewards get distributed.
That description is technically correct. But it misses the important part.
The actual problem OpenLedger is trying to solve is coordination.
Once AI systems involve many contributors, many models and many applications interacting together, somebody has to keep track of where value came from and where value should flow afterward.
That becomes difficult very quickly.
Who provided the training data? Who verified the quality? Which dataset version was used? How is usage measured? Can disputes be audited later?
Those questions sound administrative until real money starts moving through the system.
Then they become infrastructure.
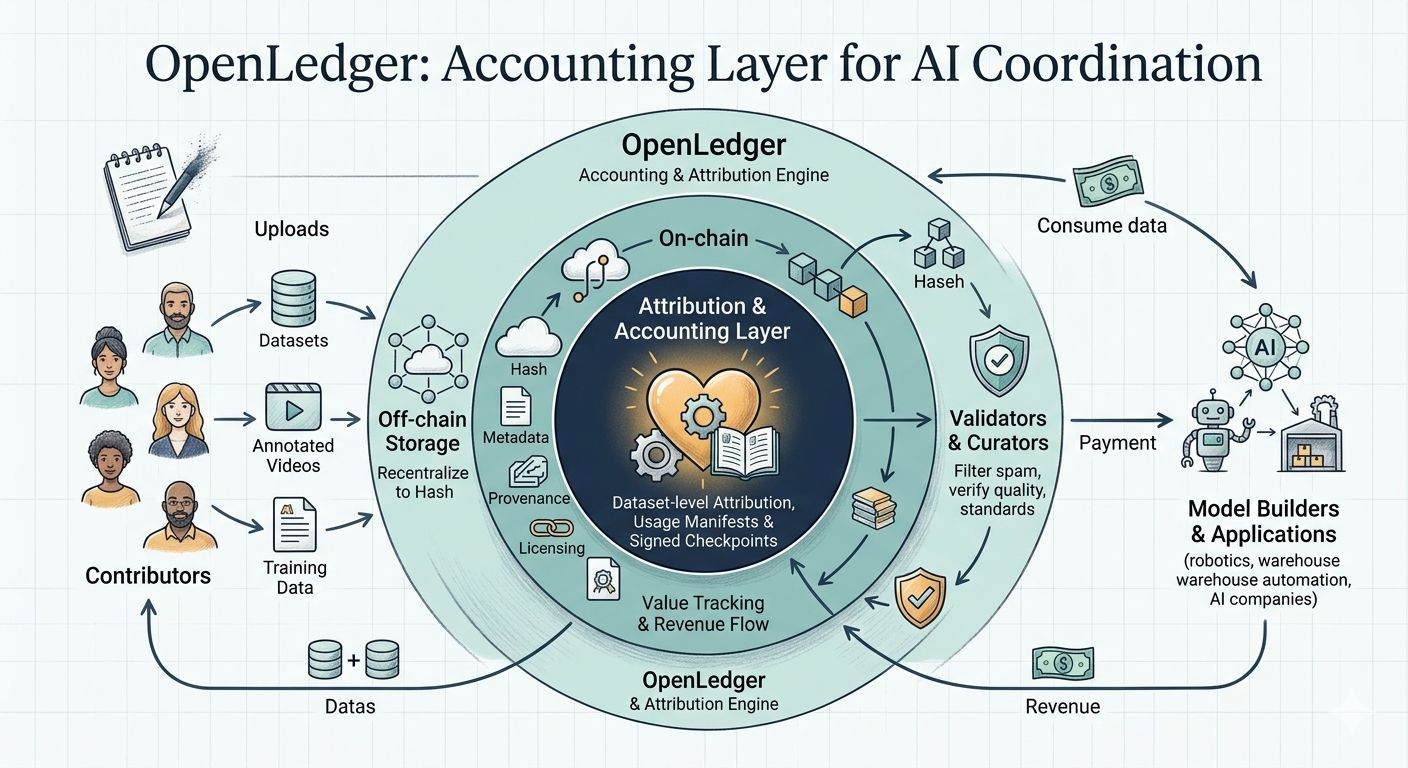
The storage side is relatively straightforward. Data lives off-chain while the chain records hashes, metadata, contributor identities and licensing references.
That part is not the challenge.
The difficult part is maintaining quality in an open system.
Because open contribution immediately creates pressure from spam, duplicate uploads, low-effort labeling and questionable ownership claims.
Markets do not automatically filter that out cleanly.
Validators and curators become necessary almost immediately.
And once validators become important, trust starts concentrating around whichever participants consistently maintain quality standards.
That is where decentralization becomes more complicated than the branding language suggests.
The system still remains distributed. But coordination naturally begins forming around trusted actors.
That happens in almost every network eventually.
Open systems scale participation. Scale creates abuse. Abuse creates demand for filtering. Filtering creates influence.
The attribution layer itself is where OpenLedger becomes genuinely interesting.
And also where the system becomes difficult to execute properly.
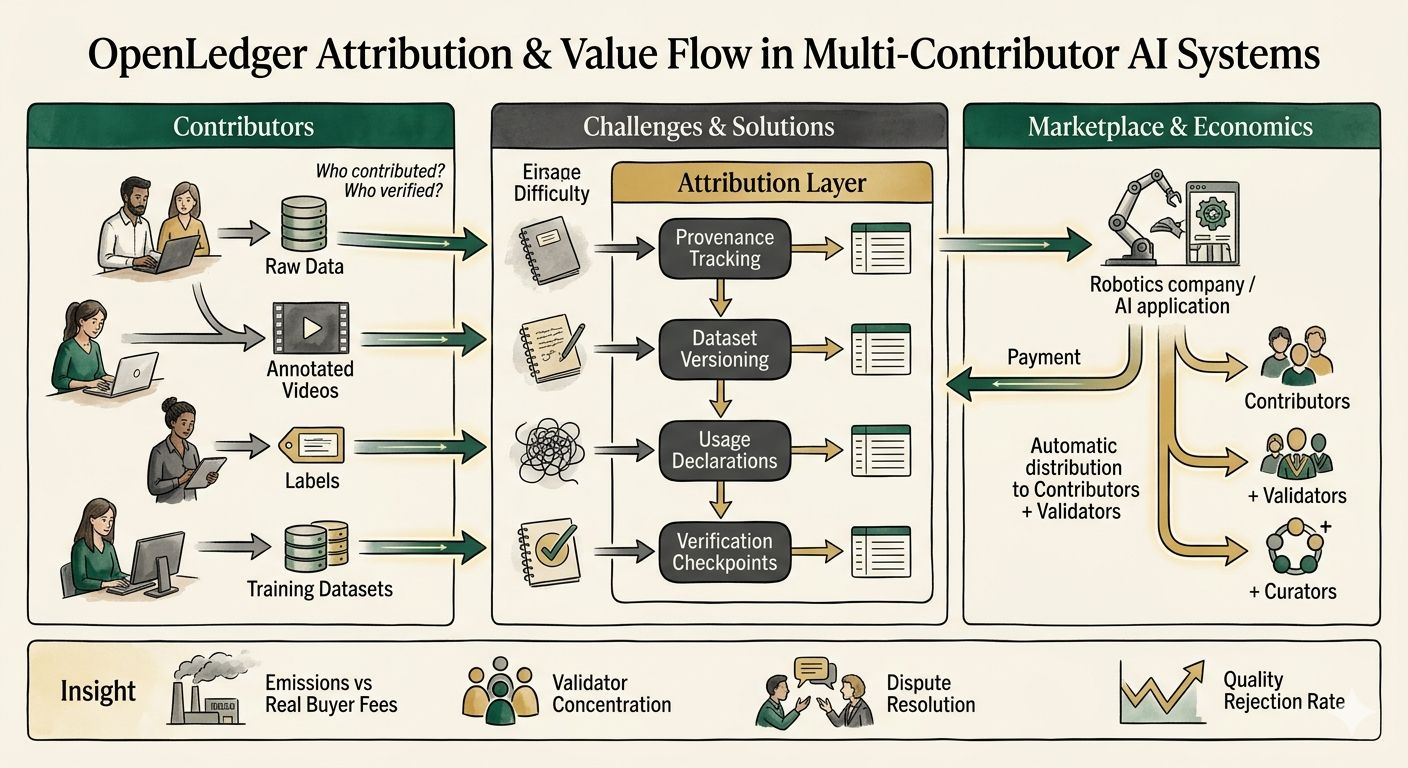
People talk about AI attribution as if models preserve exact ingredient lists internally. Real training pipelines do not work like that. Data gets filtered, compressed, mixed together, transformed and reused continuously.
By the time outputs emerge, tracing influence perfectly becomes unrealistic.
Which means attribution probably works through broader accounting structures instead of microscopic tracking.
Dataset-level attribution. Usage declarations. Signed manifests. Verification checkpoints.
That still creates meaningful coordination.
But it also means enforcement matters more than theory.
Because attribution only works if dishonest reporting carries real consequences.
Otherwise the system slowly becomes symbolic rather than operational.
And crypto systems have a long history of appearing sustainable during incentive-heavy periods before weak enforcement eventually surfaces underneath.
The marketplace side becomes easier to understand through practical examples.
Imagine a robotics company training warehouse automation models.
They need annotated video datasets with clean commercial rights, consistent labeling and reliable provenance. Traditional vendors already provide these services through centralized agreements.
OpenLedger’s structure changes the coordination model.
Contributors provide data. Validators verify quality. Model builders pay for usage. Revenue flows back through the attribution layer automatically.
The appeal is transparency and programmable compensation instead of opaque vendor relationships.
But buyers care about reliability more than ideology.
A company integrating AI into production systems wants accountability that survives legal reviews, operational failures and commercial disputes.
That is the real test for OpenLedger.
Not whether contributors join the network.
Whether serious buyers trust the attribution layer enough to build around it consistently.
Because external demand is the only thing that stabilizes these systems long term.
Without buyers, emissions carry too much of the economy.
And emissions always distort behavior eventually.
Networks start rewarding visible activity over valuable activity: more uploads, more participation, more apparent usage.
Not necessarily higher quality.
That is how ecosystems drift toward duplicated datasets, spam submissions and artificial engagement around incentives.
The metrics worth watching are probably the least exciting ones:
contributor rewards funded by real buyer fees versus emissions
validator concentration
dispute resolution outcomes
rejection rates for low-quality submissions
repeat production usage instead of temporary pilot activity
Those numbers reveal whether attribution is functioning as infrastructure or simply as narrative.
I am also cautious whenever one token coordinates too many functions simultaneously.
From what I understand, $OPEN handles incentives, validation economics and marketplace settlement together.
That can work. But multi-purpose token systems sometimes hide weak organic demand because one layer temporarily subsidizes another.
The network looks economically active while sustainability remains unresolved underneath.
Still, OpenLedger is addressing a more serious problem than most AI + crypto projects are addressing right now.
Not simply: “How do we decentralize AI?”
The real question is: “How do we coordinate trust, compensation and accountability once AI systems involve many independent participants contributing value simultaneously?”
That is a much harder infrastructure problem.
And honestly, that is probably why the project feels more interesting the deeper you look into it.
Not because the system is simple.
Because it is trying to organize a part of AI economics that most projects still avoid dealing with directly.