Let me be honest about something before I start — when I first came across this kind of system, my instinct was to dismiss it as another over-engineered Web3 project with too many rules and not enough freedom. But then I spent more time with it. And the picture changed.
Reading through @OpenLedger documentation carefully one idea kept coming back to me — this isn't just a data platform. It's an experiment in making data something you earn the right to contribute, not just dump somewhere.
Let me break that down.
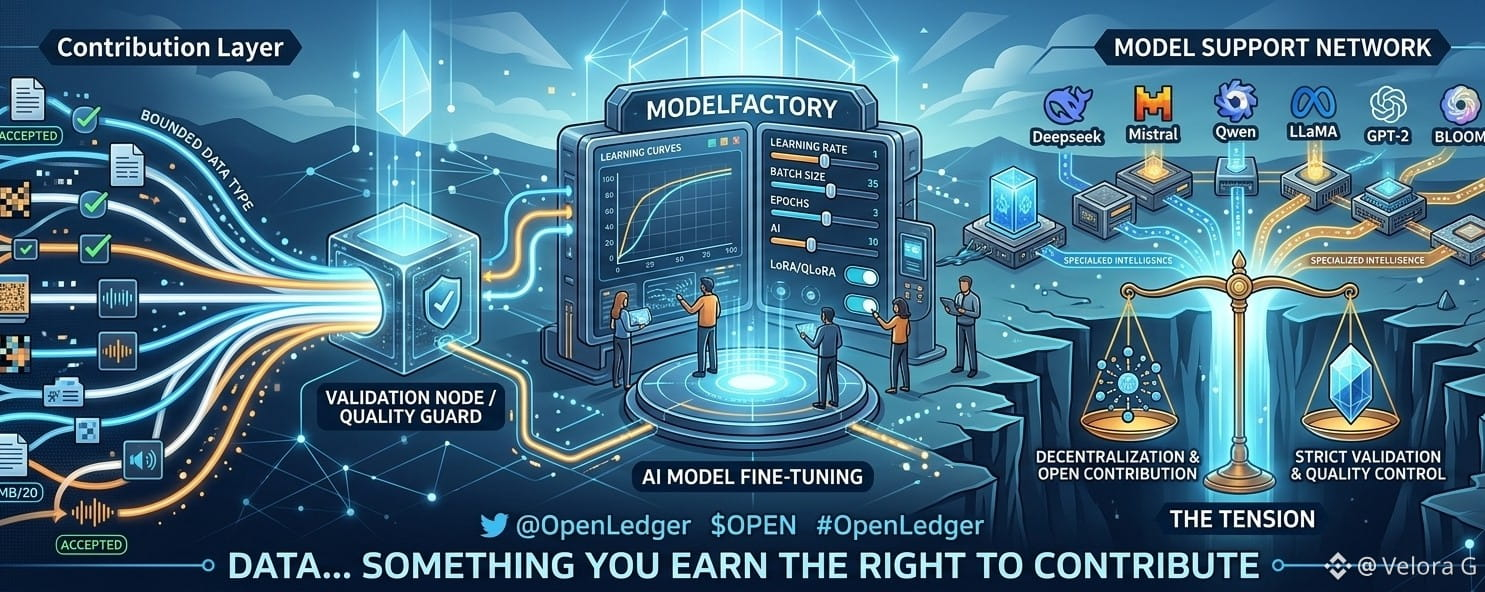
The Contribution Layer Has Boundaries And That's the Point
The first thing you notice is the restrictions. Text images, audio — kept separate. 10 MB daily limit. 20 file cap. On the surface this sounds counterintuitive for a Web3 project where the default promise is permissionless everything. But think about it differently. Unlimited contribution doesn't mean valuable contribution. Without filters you just get noise. These limits aren't about gatekeeping — they're about protecting signal quality.
The leaderboard design reinforces this thinking. Your rank doesn't go up just because you uploaded more files. What matters is your acceptance rate. Ten low quality uploads help nobody including you. But here's the part I actually respect rejected files don't hurt your ranking either. That's a deliberate choice. It means the system wants people to experiment without punishing honest mistakes. That's a healthier incentive structure than most platforms I've seen.
ModelFactory Is Where Things Get Serious
This is the part of OpenLedger that I think deserves the most attention. They're turning LLM fine-tuning — something that has historically lived inside research labs and terminal windows — into a visual GUI driven workflow. Learning rate batch size epochs — all adjustable without writing a single line of code.
At first glance you might read that as beginner-friendly. But the deeper ambition is more interesting than that. It's about democratizing AI development while keeping the process structured and controlled. Those two things usually trade off against each other. Here, they're trying to hold both.
The LoRA and QLoRA support makes practical sense too. Full model fine-tuning is expensive. Lightweight adaptation paths lower the barrier without sacrificing meaningful customization. And the real time dashboard combined with post-training interaction suggests they want training to be a continuous loop — not a one-time event. Train, test, interact, refine. Repeat.
Wide Model Support Is a Strategy Not Just a Feature List
Deepseek, Mistral Qwen LLaMA, GPT-2 BLOOM ChatGLM — the range is broad. You could look at this and think they just wanted to check boxes. But I read it differently. Narrow model support creates a narrow platform. Wide support means a wide experimentation space, which means more types of contributors can actually build something meaningful here.
The Tension at the Center
Here's what I keep coming back to when I think about OpenLedger as a whole.
There are two forces pulling in opposite directions inside this system. On one side decentralization, open contribution, community-driven data. On the other strict validation, controlled structure, quality enforcement. These two things are genuinely hard to keep in balance. Most systems collapse toward one or the other over time.
Whether OpenLedger gets that balance right is still an open question. But the design choices suggest they've at least thought carefully about where the tension sits, rather than pretending it doesn't exist.
The real question underneath all of this isn't technical. It's philosophical — can data become a true economic asset in a system like this, or are we just rebranding an old validation problem with new infrastructure?
I don't have a clean answer to that. But I think it's a question worth sitting with seriously.
Because if the balance holds — this could be something real.


