been going through openledger’s architecture docs and scattered discussions, mostly because i’m trying to separate the “ai + crypto token” story from what’s actually being built. most people i’ve talked to seem to file it away as: “decentralized data marketplace, contributors upload stuff, token rewards, done.” but that narrative feels too compressed, and it hides the hard part: making data attribution and incentives work when there’s real money and real model demand on the line.
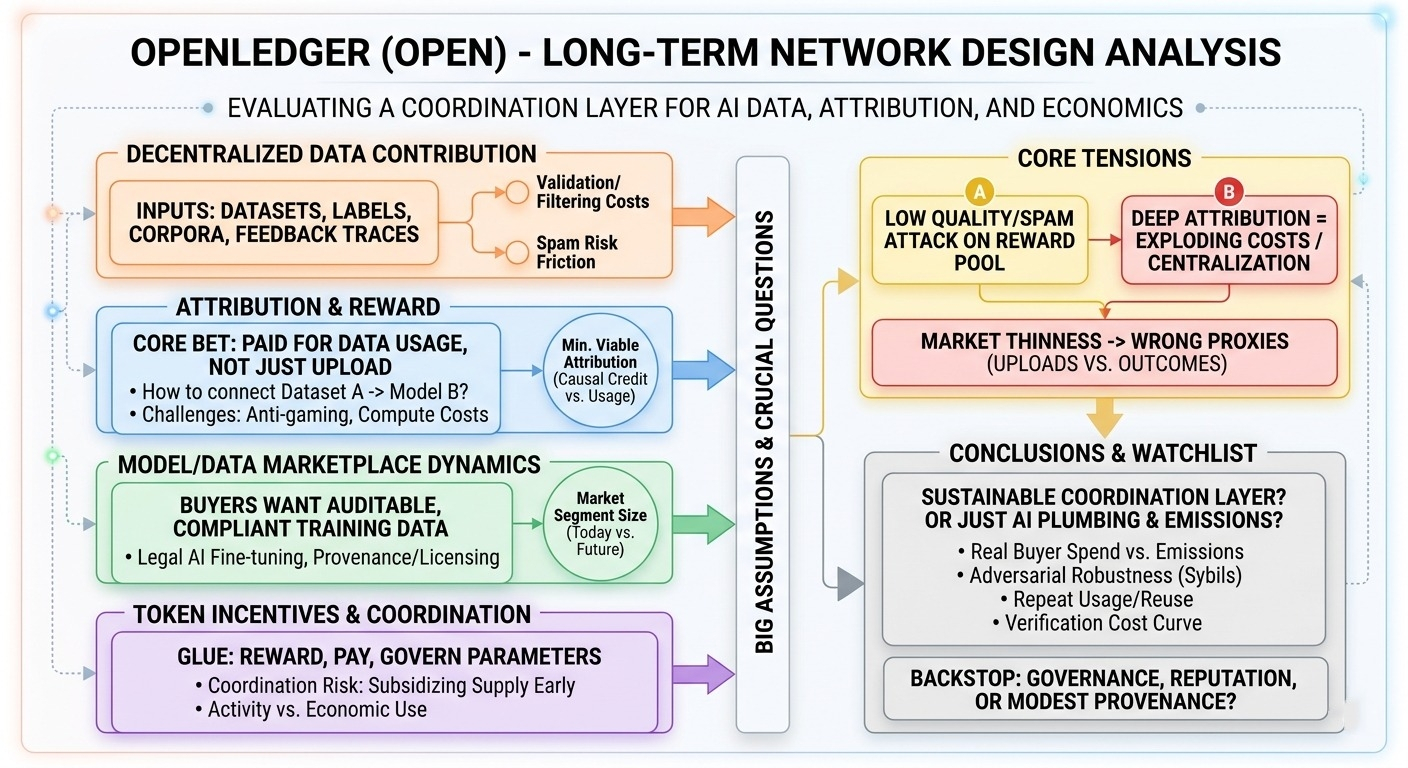
what caught my attention is that openledger isn’t only “storage + payments.” it’s trying to be a coordination layer where (1) data gets contributed, (2) data gets attributed to downstream model value, and (3) model usage becomes an on-chain economic loop. that’s ambitious, and honestly i’m not totally sure the pieces fit cleanly yet, but the shape is interesting.
first component: decentralized data contribution. the contribution side seems like it wants to be open-ended: datasets, labeled samples, maybe domain-specific corpora, potentially even feedback traces from model usage. the design question here is less “can people upload data?” and more “can you keep the cost of validating and indexing that data low enough that the network doesn’t drown in junk?” any open contribution funnel trends toward spam unless there’s friction, reputation, or some probabilistic verification layer that’s cheap to run.
second: attribution + reward. this is the core bet. openledger’s pitch (as i understand it) is that contributors don’t just get paid for uploading; they get paid because their data is used, and usage can be measured/attributed. and this is the part i keep thinking about… attribution in ML is messy even off-chain. once you put it in a protocol, you need a story for “how do we know dataset A helped model B” that’s robust against gaming and not insanely expensive to compute. influence functions, gradient-based credit assignment, dataset sharding with audit trails — all of these exist academically, but turning them into something adversarially robust and operational is another thing. i’d like to see what their “minimum viable attribution” is: is it strict causal credit, or more like “verified inclusion + usage metering”?
third: model/data marketplace dynamics. openledger seems to assume there will be buyers who want clean, auditable training data or model inputs with provenance. a realistic example: a small legal-ai fine-tuning shop wants a dataset of annotated contract clauses, and they need provenance for compliance (where did each clause come from, what license, who labeled it). in a centralized setup, you trust a platform’s internal logs. here, the goal is to make provenance and licensing auditable and payable on-chain. that’s valuable if compliance actually matters to buyers — but it’s not obvious how big that buyer segment is today versus “someday.”
fourth: token incentives + coordination. the token is basically the glue: it rewards contribution, pays for access, and maybe governs parameters (verification thresholds, reward curves, slashing rules, etc.). my skepticism here is pretty standard: if emissions are doing most of the paying early on, you’re subsidizing supply before demand exists. that can work as bootstrapping, but it can also create a network that’s great at producing “activity” and not great at producing economically useful data.
so who creates value? contributors create raw material, but the real value is created when model builders repeatedly pay for data/model access because it improves their product margins. which leads to the big assumptions: (1) ai teams will want on-chain coordinated data deals, (2) attribution will be credible enough to price, and (3) the protocol can filter for quality without becoming a permissioned cartel.
the tension i keep circling: low-quality and spam data is not just noise; it’s an attack on the reward pool. if attribution is shallow (e.g., pay-per-download), sybil farms win. if attribution is deep (e.g., compute-heavy credit assignment), costs explode or verification centralizes into a few operators. and if the “marketplace” is thin, token incentives may start rewarding the wrong proxies (uploads, labels, transactions) instead of outcomes (paid reuse, measurable model lift).
no perfect conclusion yet. i’m basically trying to tell whether openledger becomes a sustainable coordination layer, or if it’s attaching token incentives to ai plumbing ahead of real demand.
watching:
- ratio of rewards from real buyer spend vs token emissions
- evidence that attribution survives adversarial behavior (sybils, collusion, data laundering)
- repeat usage: do the same datasets get purchased/licensed multiple times?
- verification cost curve: does quality assurance get cheaper per unit over time, or more expensive?
if the protocol can’t prove “trusted attribution at scale” without centralizing, what’s the backstop — governance, reputation, or just accepting a more modest version of provenance?