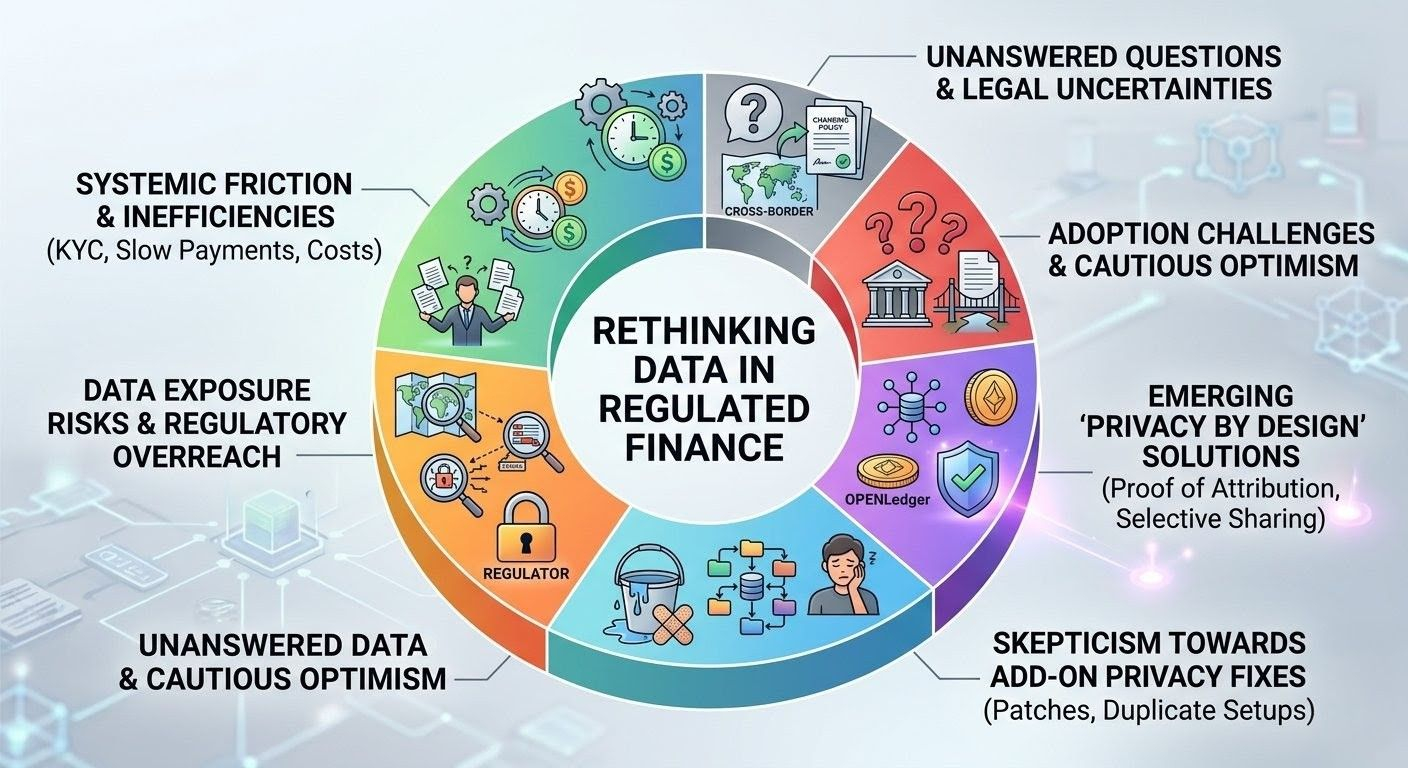
I've been turning this over in my mind for weeks now, especially after digging through yet another set of transaction records late at night that just felt uncomfortably exposed. It got me thinking about a mid-sized trader I know in Singapore, someone who's been in the import business for years. He's wiring routine payments to factories in Vietnam and distributors across Europe, and every single transfer creates this detailed map—balances, who he's dealing with, spending patterns—that ends up sitting in bank systems. Auditors, regulators, even potential leaks can access more than feels right. It's not some dramatic conspiracy; it's just the daily grind. Treasury folks are drowning in KYC updates that never seem to end, fintech builders watch potential users drop off at the first ID check, and regulators themselves seem caught between cracking down on real risks and facing pushback when it all starts feeling like overreach. This friction isn't some policy paper issue. It's what makes moving money slower, pricier, and more nerve-wracking than it has any business being.
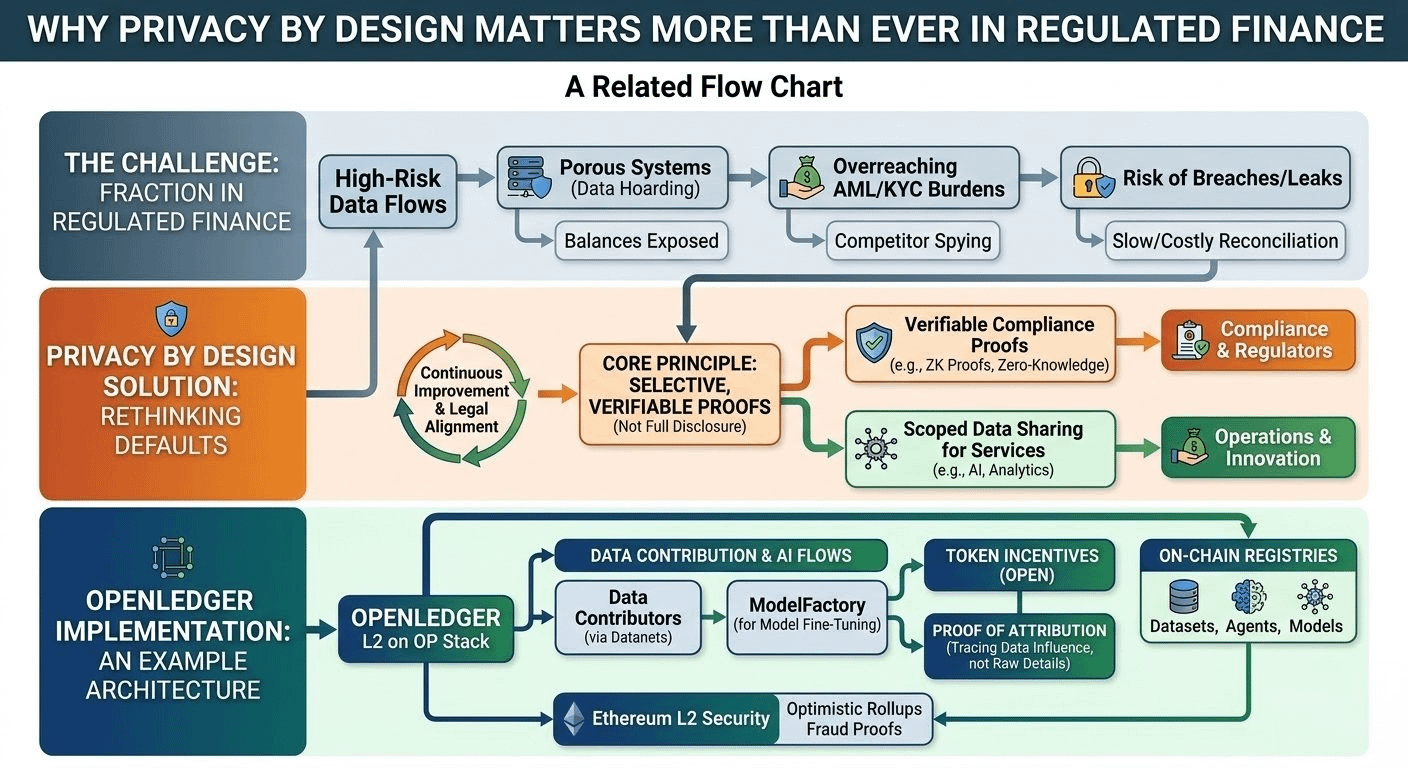
The way regulated finance got here has always struck me as a bit inevitable but flawed. We took those old systems built around a handful of trusted intermediaries holding the complete picture—because you needed that for catching fraud and stopping dirty money—and just digitized everything without really questioning the defaults. What began as sensible audit trails has turned porous in a world where data is searchable, shareable, and too easy to breach. AML rules and sanctions lists make sense; they demand proof, so the standard reaction is to gather piles of personal and business details right from the start. Privacy, when it appears, often comes as an afterthought—maybe some extra encryption, a consent box you click without reading, or special exceptions for the biggest clients. Those patches hold up okay for a bit, but then a new rule lands or one country reads the requirements differently, and suddenly your processes stall while the legal team scrambles. I've seen too many setups that looked promising on paper fall apart exactly at this point. The nice demo of controlled sharing rarely survives actual settlements, clashing regulations across borders, or that one partner who demands to see it all anyway.
What leaves me most skeptical about the usual fixes is how they treat privacy like an add-on instead of something woven into the foundation. You default to full openness and then try slapping on controls or extra policies afterward. In real life, that just creates more headaches: things slow down waiting for approvals, monitoring tools get overwhelmed by noise, and you end up paying for duplicate setups that don't even deliver that much extra safety. Human nature makes it all messier. Most people and companies aren't looking for secrecy to cover up wrongdoing—they just want a little protection from competitors poking around their strategies, scammers spotting patterns, or that creeping feeling that every step is being logged forever. Developers I talk to get worn out by compliance steps that feel more like theater than actual shields. Bigger institutions move cautiously on changes because retrofitting old systems often opens new cracks or makes linking back to traditional networks even harder. In the end, you get this unsatisfying middle ground where regulators are still chasing incomplete stories, everyone braces for the next leak, and the whole setup wastes time, money, and goodwill.
This is where something like OpenLedger catches my attention—not as a perfect solution or hype piece, but as one real attempt at building better plumbing. It's an Ethereum L2 on the OP Stack, focused on AI flows, but the privacy and attribution side feels relevant for finance. Through Datanets, people and businesses contribute specialized data for models. The Proof of Attribution system tries to trace exactly which data influenced an output, without spilling every raw detail publicly. Contributors get rewarded in OPEN tokens based on real impact. For regulated finance, imagine using this for tokenized assets or AI-driven decisions: you prove compliance bits—like sanctions status or source of funds—without exposing full histories or client patterns. Model inference payments happen on-chain, governance stays open to token holders, yet ordinary operations feel more contained. It builds on Ethereum security with optimistic rollups and fraud proofs for registries. I've seen the docs on ModelFactory and OpenLoRA for fine-tuning, and the on-chain registries for datasets and agents.
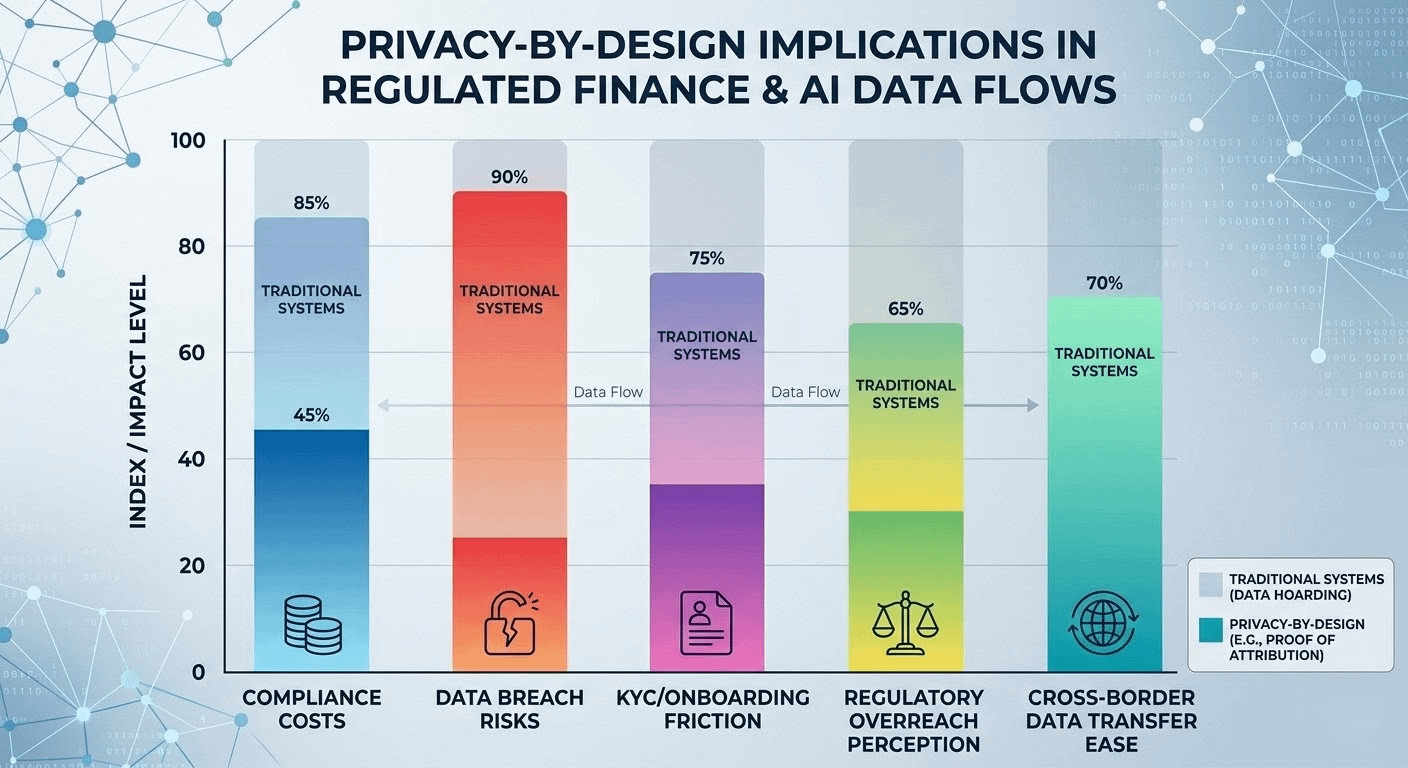
Even with that, I stay cautious. Does it embed privacy deeply enough for high-stakes money movement? Token incentives might pull in data contributors, but when real financial data sits there—with fines or licenses on the line—trust in those attribution methods (gradient-based or suffix-array techniques) will get tested hard. Real usage would show if settlement stays reliable under load, how it handles cross-border legal differences, and whether the privacy features avoid quietly depending on central points like sequencers. OpenLedger doesn't solve everything on its own, but it points toward rethinking defaults: keep daily flows scoped while allowing targeted, verifiable proofs for what regulators actually need.
One question that keeps nagging at me in all this: if a system like OpenLedger could genuinely let institutions prove compliance without exposing full transaction histories, would that finally shift how regulators and banks think about data sharing—or would old habits and risk aversion keep things stuck in the current patchwork?
At its heart, true privacy by design would mean changing the starting assumptions, and OpenLedger's approach—Proof of Attribution combined with selective on-chain tracking—feels like a step in that direction for AI-meets-finance areas. Tech is only half the story though. Laws shift at uneven paces, some wanting ironclad records and others pushing minimal data keeps. The money side counts too—running nodes, keeping validators interested, the cost of plugging in. I've watched solid ideas trip up by missing how slowly big money moves when unsure, or how fast new threats appear.
If it works out in practice, it could ease some of the bigger headaches: fewer big breaches from hoarding too much data, smoother reconciliations, and more people willing to share for better tools overall. But it's all conditional—relying on real tests in sandboxes, actual savings over old systems like SWIFT, and the ability to adapt as rules change. People and organizations will always lean toward what feels stable over flashy experiments.
The ones most likely to try it aren't everyday folks but the practical ones: portfolio managers dipping into tokenized assets, teams handling cross-border payments, or builders working on AI for compliance—places where OpenLedger's attribution and token model could actually cut costs and risks. In those spots, privacy slips hit the books, bring scrutiny, or block progress right away. It could take hold if it shows lower costs over years, holds up well, and pairs with familiar legal setups. Progress would probably come through low-key adoption, steady talks with regulators, and toughness in rough patches like heavy traffic or border conflicts. The risks I see are the usual ones: depending too much on token incentives that don't match careful duty standards, overlooking how much still ties back to traditional money rails, or letting excitement run ahead of what actually works. I wouldn't put everything on quick wins here—the story of financial tech is usually slow evolution amid complications. Still, starting with built-in limits and provable pieces, like OpenLedger tries with its attribution engine, feels more solid than constant fixes. It's the kind of careful step best measured by quieter, real reductions in daily strain rather than big promises. Trust comes bit by bit, earned through things that simply work better in practice.