Been going through openledger’s architecture again, mostly the parts around data registration + incentives, and trying to picture it running in the wild (not just in a clean demo). what caught my attention is how much of the design is basically an attempt to turn ai inputs into accountable “economic objects” without pretending the chain can validate model quality directly.
most people think openledger is just another ai + crypto token where you upload data, stake something, and hope number-go-up. i get why that narrative sticks. but the deeper claim is more specific: if you can make provenance + usage attribution legible, you can coordinate payments across contributors, curators, and model builders in a way that centralized platforms usually handle with contracts + closed databases.
the pieces that feel most important (and also easiest to get wrong):
1) decentralized data contribution (but not “everything on-chain”)
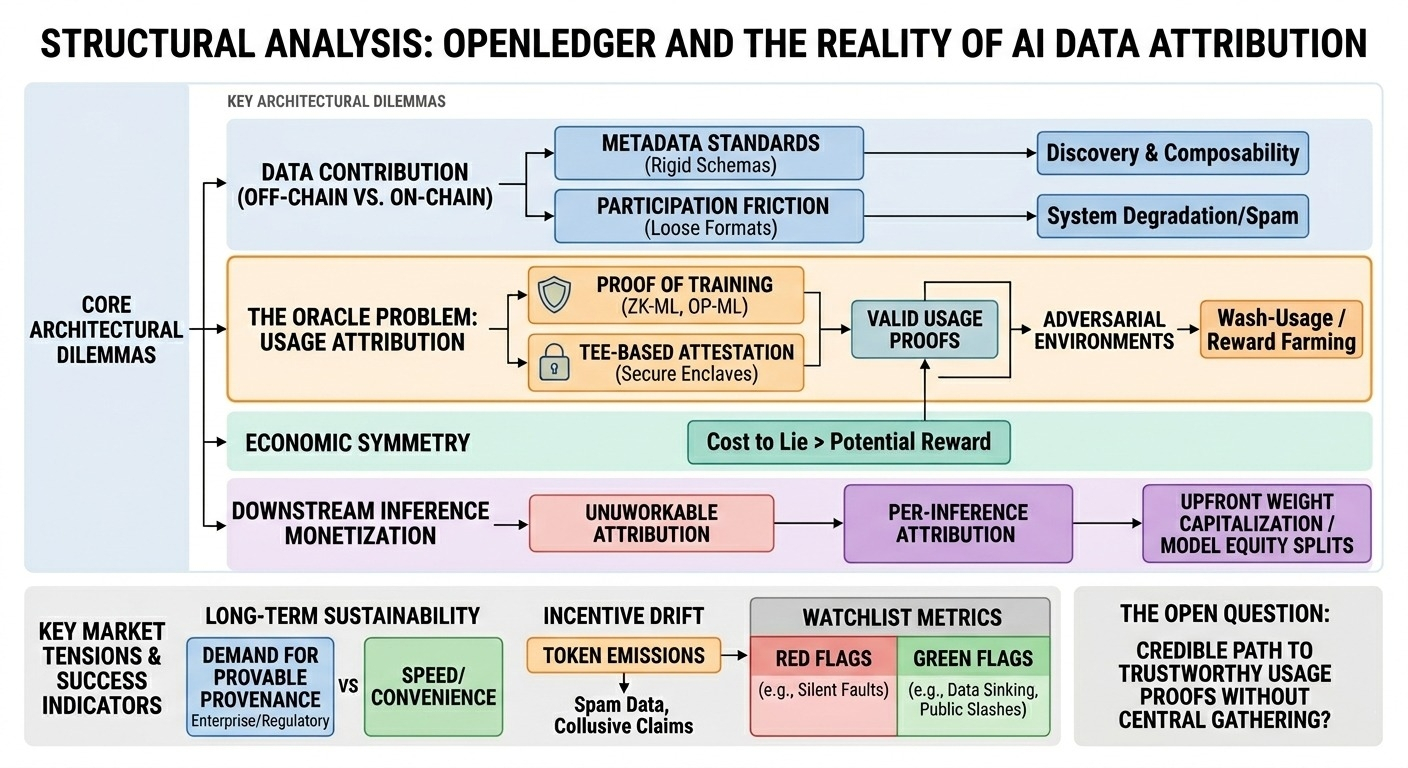
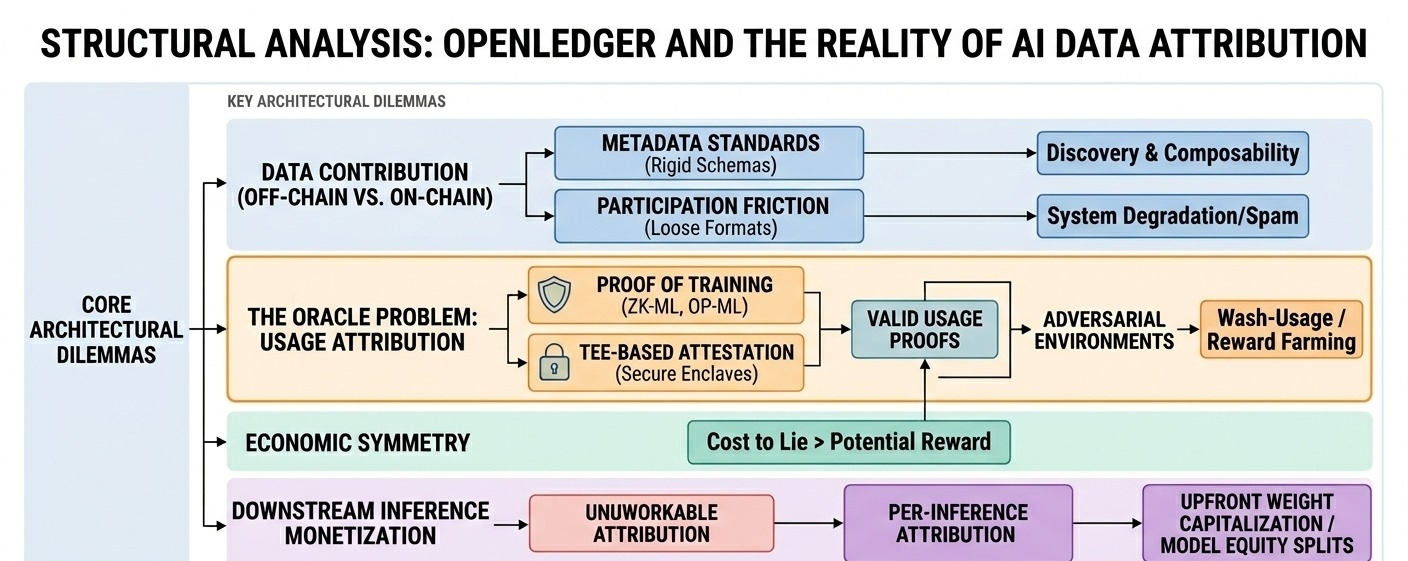
it looks like openledger wants datasets and related artifacts to live off-chain (storage networks, traditional object stores, whatever), with hashes/commitments + metadata on-chain. that’s sensible. the question is: how tight is the metadata standard? if contributors can register anything with loose schemas, discovery and composability degrade fast. if the protocol enforces strict formats, participation drops. i’m not sure where they’ll land, and the tradeoff is kind of the whole system.
2) attribution + reward routing
openledger’s north star seems to be: “if your data is used, you keep earning.” and this is the part i keep thinking about… because “used” is not naturally observable. a chain can’t see inside a training loop. so you end up with attestations: some agent (trainer, compute provider, auditor, maybe the buyer themselves) signs a statement like “job j used dataset ids {a,b,c} and produced model m.” that can work, but only if (a) there’s a cost to lying, and (b) the network can actually punish lies. otherwise you get wash-usage, where people simulate training jobs purely to trigger rewards.
3) marketplace dynamics for data + models
a real market needs more than listing pages. buyers want licensing clarity, quality signals, and a frictionless “i can integrate this today” path. openledger’s approach seems to be turning those requirements into protocol-level objects: standardized rights metadata, attribution graphs, and payment splits. indirectly, it’s trying to replace the role of centralized data brokers / hosted model platforms that rely on trust and account relationships. i’m unsure whether on-chain coordination beats “just sign a contract with a vendor” unless the protocol can consistently deliver better pricing or better provenance.
4) scalability / verification layer (the unglamorous part)
the system needs some mechanism to filter spam and enforce quality. that likely means curators, reputation, staking, slashing, maybe some challenge process. but verification doesn’t scale linearly: the more data you ingest, the more expensive it is to validate it isn’t duplicated, poisoned, or legally sketchy. if verification becomes a small set of semi-trusted entities, decentralization becomes more of a label than a property.
who creates value here?
in practice, the highest value probably comes from (1) unique datasets that aren’t easily scraped, (2) expensive labeling/cleaning, and (3) domain evaluation harnesses that tell you whether the data helped. imagine a contributor group providing de-identified clinical notes with consistent coding, or even a simpler example: multilingual customer support chats with intent labels and tight redaction. a model builder might pay to fine-tune a support agent. openledger can record the purchase and route revenue back. but connecting that to ongoing inference revenue later is harder unless inference is mediated through something the protocol can meter (or unless teams voluntarily report usage, which feels optimistic).
the tension i can’t ignore
openledger’s long-term sustainability seems to assume steady demand for “provable provenance” in ai development. maybe that demand grows (regulation, enterprise compliance), but today a lot of teams optimize for speed and convenience. if buyer demand is weak, the network leans on token emissions to keep contributors engaged. and once emissions drive behavior, incentives drift: contributors optimize for what gets rewarded, not what’s useful. spam data, duplicated corpora, synthetic “labeling,” even collusive attribution claims — these aren’t edge cases, they’re the default adversarial environment.
so i don’t have a neat conclusion. i can see the shape of a genuine coordination layer, but it hinges on whether attribution can be made expensive to fake and cheap to verify, at scale, without reintroducing a central gatekeeper.
watching:
- % of payouts funded by real buyer spend vs emissions over time
- dataset “activation rate”: how many registered datasets ever get paid usage
- frequency + outcome of attribution disputes / slashing events (if any)
- concentration metrics: do a few curators or datasets capture most rewards
if openledger works, it’s because they solve the boring integrity problems. if it doesn’t, it’ll still look busy for a while. the open question for me: what’s their credible path to “trustworthy usage proofs” without forcing everyone to run through a single metered endpoint?