Market was sideways for most of the week.
Not crashing, not pumping — just that weird in-between state where you start clicking on random projects just to fill the time. That's how I ended up going down a rabbit hole on OpenLedger and $OPEN .
Didn't expect much, honestly. Another "AI + blockchain" thing. I almost closed the tab.
But then something stopped me.
Everyone I'd seen talking about $OPEN was framing it the same way: "they're building a decentralized data marketplace for AI — anyone can contribute their data and get paid."
And at first that sounds genuinely cool. Like, finally, you own your data. Stick it to the big tech companies. Very web3, very 2025.
But here's where I started getting uncomfortable.
I thought about what data AI models actually need to get smarter. And it's not your Reddit comments. It's not my browser history. It's not anyone's Spotify listening patterns.
The data that genuinely moves the needle on AI quality? Labeled medical scans. Annotated legal documents. Expert-corrected code. Specialized financial datasets with verified structure. The kind of stuff that took someone years of expertise to even produce — let alone label correctly.
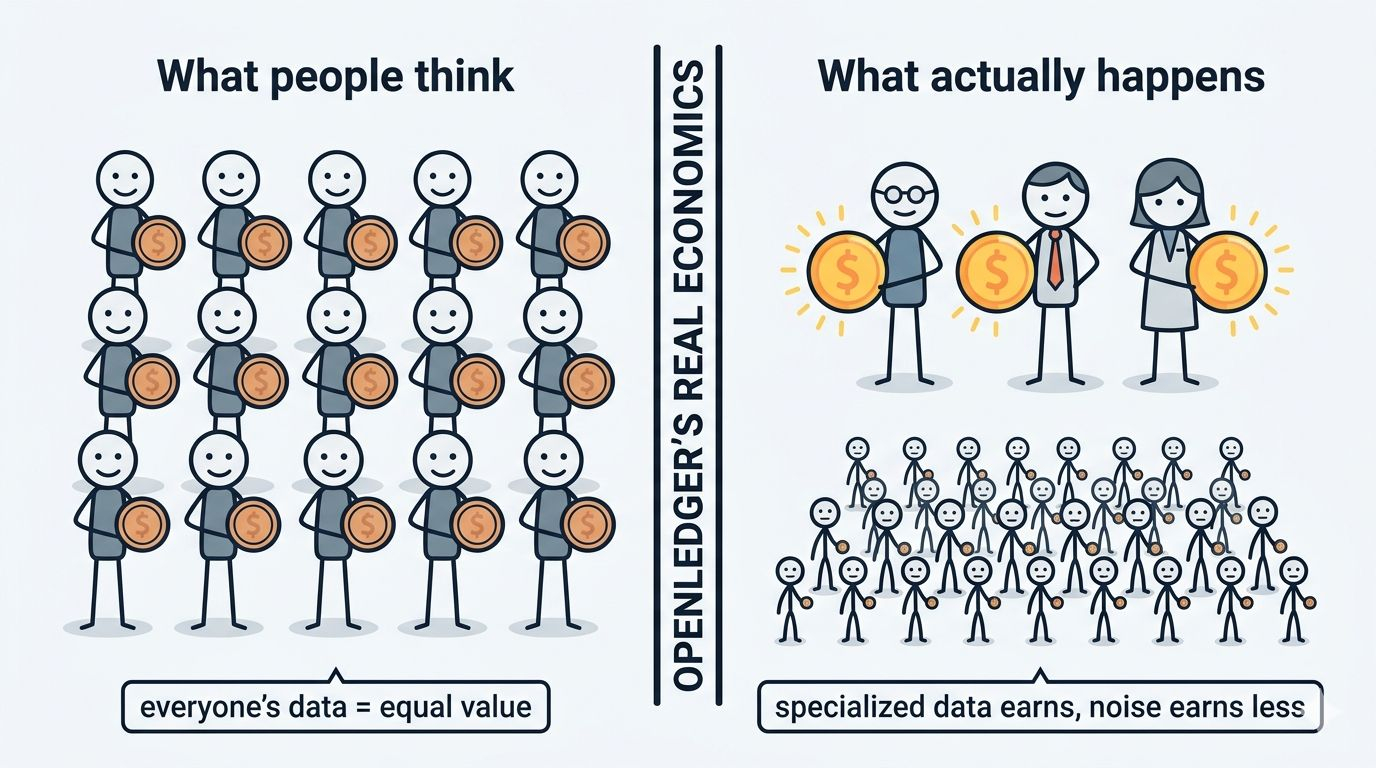
So when OpenLedger says "contribute data, earn $OPEN"... I started wondering who actually wins here. Because if the network gets flooded with low-value data — generic text, unstructured noise — the whole incentive system starts to feel like it's built on a narrative more than a mechanism.
Here's the one thing I can't shake: most people's data isn't valuable enough to matter.
That's not cruel, it's just true. The "everyone gets paid for their data" pitch is emotionally satisfying, but the actual value in OpenLedger's network probably concentrates around a much smaller group — researchers, domain experts, institutions with proprietary datasets. The average person contributing is more like... providing background scenery for someone else's payday.
And I don't think that's a fatal flaw necessarily. But it does mean the token narrative and the actual economic mechanism aren't quite the same thing.
The part that's actually more interesting to me — once I got past the marketing angle — is whether OpenLedger can function as infrastructure for the people who do have valuable data. If it becomes the layer that sits between specialized data holders and AI model builders, that's a real use case. That's a genuine problem that doesn't have a clean solution yet.
Because right now, if you run a hospital system and you want to license your anonymized patient data to an AI lab, the process is... a mess. Contracts, NDAs, trust issues, pricing negotiations. There's no standardized rail for it. OpenLedger is trying to be that rail.
That's a much narrower story than "everyone gets paid." But it might be a more durable one.
I'm still not fully convinced this holds under pressure though. Data quality verification on a decentralized network is genuinely unsolved. Who decides what's valuable? A token-weighted vote? That's asking for manipulation. An oracle system? That just reintroduces centralization through the back door.
Also — and this bothered me the more I thought about it — AI labs building frontier models already have data acquisition pipelines. They're not desperately waiting for a blockchain marketplace to rescue them. The real customers for something like OpenLedger are probably mid-tier AI builders. And I'm not sure that market is as deep as the pitch assumes.
I thought this was going to be a simple "oh interesting, another AI token" take. But actually it turned into something messier.
Anyway. Charts still look flat. I'll probably just watch how this develops over the next few weeks before forming a strong opinion either way.
#OpenLedger @OpenLedger