
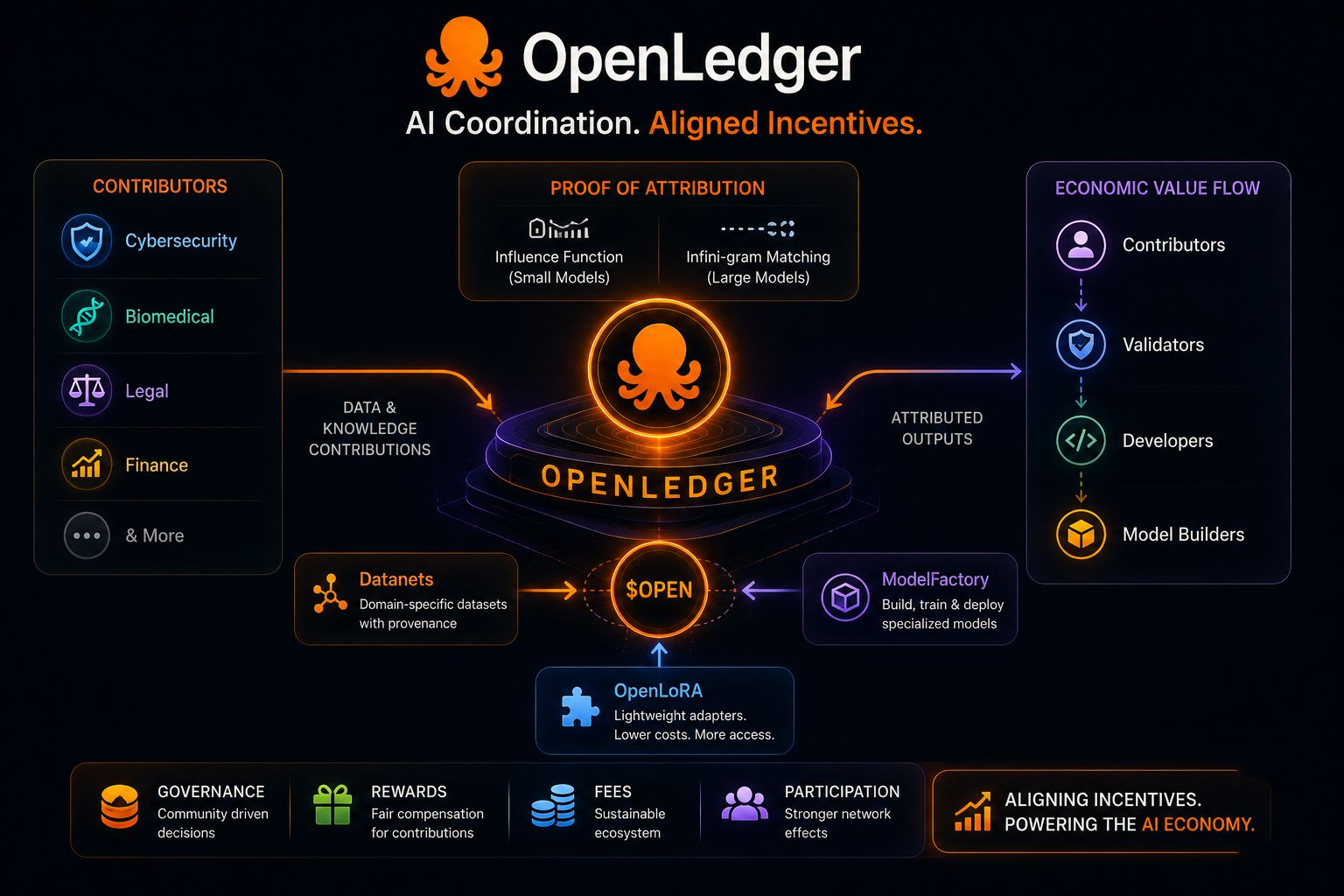
The more I read about OpenLedger, the more I think the real problem it’s trying to solve is not technical capability. AI already has models, compute, APIs, deployment frameworks, and enough infrastructure to scale rapidly. The harder problem now feels economic.
Specifically: who actually captures value inside AI systems once they become large enough to matter.
Right now most AI pipelines still work in a very one-directional way. Data moves upward through centralized systems, models get trained, companies monetize the outputs, and the people who supplied the underlying information usually disappear from the value chain entirely. Not because the industry forgot about them, but because the infrastructure was never designed to coordinate attribution and compensation at scale.
That’s the part OpenLedger seems focused on changing.
Proof of Attribution is probably the clearest example. Instead of treating datasets like anonymous fuel for models, OpenLedger attempts to trace how contributions influence outputs after deployment. Smaller models use influence function approximations while larger systems rely on Infini-gram style span matching to connect outputs back toward source material.
What matters to me isn’t only the technical mechanism itself. It’s the economic implication underneath it.
If attribution becomes native infrastructure instead of an optional feature, contributors stop functioning like invisible inputs and start functioning more like participants inside the AI economy.
And honestly, I think Datanets make that idea much more concrete.
A cybersecurity Datanet built by practitioners accumulates differently from a generic scraped dataset. Same with biomedical or legal datasets curated by people actually working in those fields. The value is no longer only scale. It becomes provenance, specialization, and verified contribution history layered together over time.
That creates a very different coordination model from how most centralized AI systems operate today.
Instead of value flowing upward toward whoever owns the aggregation layer, OpenLedger seems designed so value circulates horizontally across contributors, validators, developers, and model builders interacting through the same infrastructure layer.
The OPEN token ties directly into that coordination loop too. Governance, rewards, fees, contributor incentives, model usage, ecosystem participation. It feels less like a detached speculative asset and more like infrastructure connecting economic activity inside the network itself.
I also think tools like ModelFactory and OpenLoRA matter more than people initially realize. Lowering the cost of training and deploying specialized models changes participation dynamics completely. Developers no longer need to rebuild everything independently just to access domain-specific intelligence. Shared infrastructure becomes cheaper than isolated infrastructure.
That’s usually how real ecosystems strengthen over time.
And maybe that’s the deeper reason OpenLedger keeps standing out to me compared to a lot of AI narratives in crypto right now. It doesn’t really feel optimized around hype velocity alone. It feels optimized around coordination efficiency inside a future AI economy where attribution, ownership, and participation become impossible to ignore.
Still early obviously, and there are still huge execution questions ahead. But I do think the protocols quietly building coordination infrastructure today are probably more important than the market currently realizes.
Because once AI economies scale large enough, the systems determining who captures value underneath them matter more than the applications sitting on top.