Recentemente, eu estava checando a atividade do meu nó OpenLedger depois de alimentar alguns conjuntos de dados em Bangla na rede, e honestamente... eu tive um pensamento estranho na minha cabeça o tempo todo. Por que os dados de lugares como Bangladesh geralmente saem do país de graça, mas o valor criado a partir deles quase nunca volta? Hmmm... essa pergunta parece pequena a princípio, mas quanto mais eu mergulho na infraestrutura de IA descentralizada, mais importante ela começa a parecer. Porque, pela primeira vez, estou vendo sistemas onde os contribuidores locais de dados não estão apenas alimentando algoritmos silenciosamente nos bastidores. Eles estão se tornando parte da camada econômica em si. E essa mudança pode acabar sendo muito maior do que a maioria dos traders percebe agora.
Por anos, a economia da IA operou em uma única direção. Os dados se moviam para fora dos mercados emergentes enquanto o valor econômico se concentrava em outro lugar. Grandes empresas de tecnologia treinavam modelos usando dados comportamentais globais, padrões de linguagem regionais, registros agrícolas, conversas de atendimento ao cliente, até informações de saúde. A infraestrutura melhorou globalmente, sim. Mas a propriedade permaneceu centralizada. A maioria dos países do Sul Global se tornou fornecedora de dados brutos em vez de partes interessadas na economia da inteligência.
É exatamente aí que a tese de @OpenLedger se torna interessante para traders e desenvolvedores que estão observando o próximo ciclo de infraestrutura de IA.
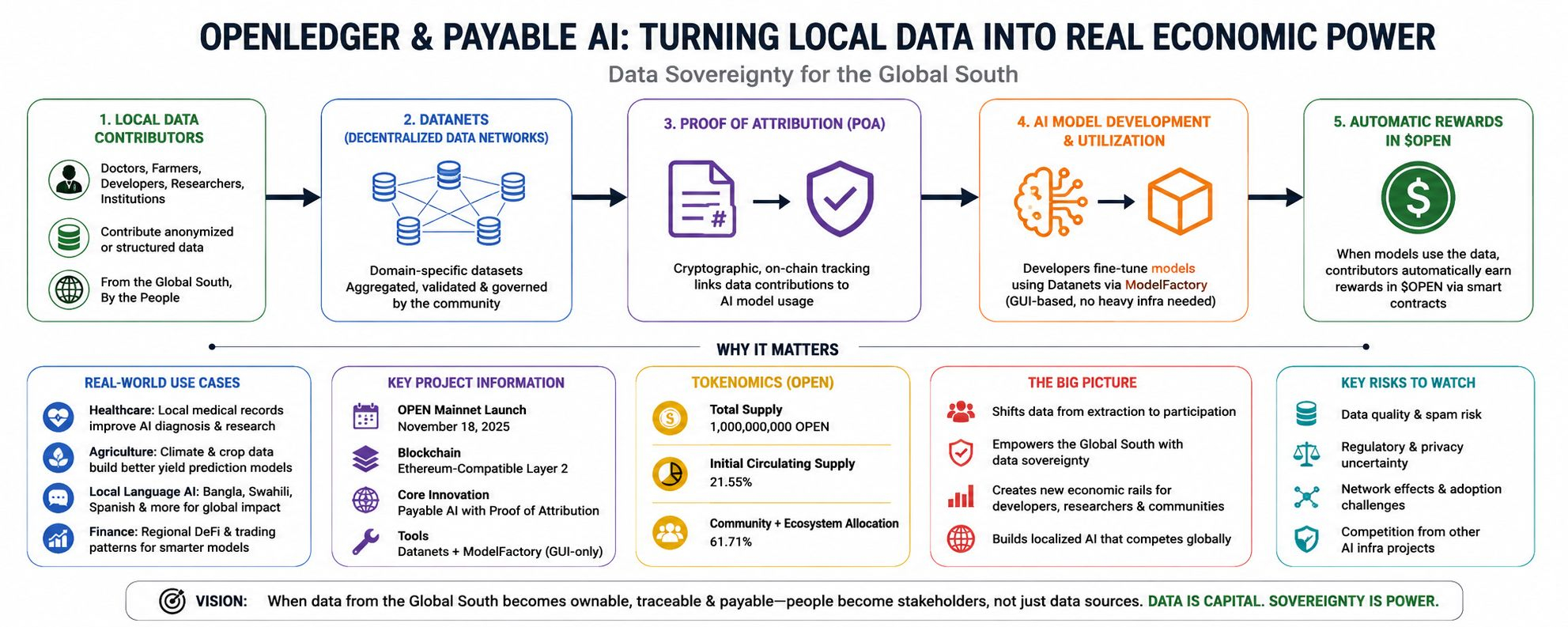
A OpenLedger lançou oficialmente sua Mainnet OPEN em 18 de novembro de 2025, posicionando-se como uma Layer 2 compatível com Ethereum focada em 'IA Pagável'. O conceito parece técnico à primeira vista, mas o mecanismo é na verdade simples. Cada contribuição de conjunto de dados dentro de suas Datanets descentralizadas pode ser rastreada através de algo chamado Prova de Atribuição, ou PoA. Se um modelo usar mais tarde esse conjunto de dados para treinamento ou ajuste fino, os contribuidores podem receber recompensas automaticamente em $OPEN através de contratos inteligentes.
A parte importante não é a recompensa do token em si. A parte importante é a propriedade verificável.
Acho que muitos traders ainda subestimam quão grande esse mercado pode se tornar. A IA não está mais caminhando em direção a sistemas genéricos de 'um modelo serve para todos'. A tendência em 2026 está claramente mudando para uma inteligência localizada. Modelos de linguagem regionais. Agentes financeiros específicos de países. Previsões agrícolas treinadas com base no comportamento climático local. Sistemas de saúde treinados com terminologia médica nativa. IA especializada precisa de conjuntos de dados especializados, e conjuntos de dados especializados são incrivelmente difíceis de obter em escala.
É aí que a estrutura Datanet da OpenLedger começa a fazer sentido estratégico.
De acordo com a documentação da OpenLedger divulgada após a mainnet, o ecossistema já suporta Datanets específicas de domínio em saúde, finanças e aplicações de linguagem local. A plataforma ModelFactory deles também reduziu significativamente as barreiras ao permitir que contribuidores ajustem modelos sem gerenciar infraestrutura cara diretamente. Para desenvolvedores menores em lugares como Daca, Nairóbi, Jacarta ou São Paulo, isso muda completamente a economia. Em vez de implorar a empresas de IA centralizadas por acesso a API e subsídios de computação, os contribuidores podem participar diretamente da economia de treinamento.
E sim... isso muda a narrativa do investimento também.
A maioria dos traders de cripto ainda aborda tokens de IA apenas através de ciclos de especulação. Mas tokens de infraestrutura conectados à propriedade de dados podem evoluir de maneira diferente porque se ligam diretamente à economia de produção de IA. A tokenômica da OpenLedger reflete essa direção. O projeto mantém um suprimento total de 1 bilhão de tokens OPEN, enquanto mais de 61% da alocação é direcionada para a participação da comunidade e do ecossistema, em vez de distribuição puramente interna. Em teoria, isso cria um alinhamento mais forte a longo prazo entre contribuidores, validadores, desenvolvedores e provedores de dados.
Claro, teoria e realidade nunca são idênticas. Essa parte importa.
Eu testei redes de infraestrutura iniciais o suficiente para saber que incentivos sozinhos não garantem ecossistemas duradouros. @OpenLedger ainda enfrenta vários riscos reais que os traders devem observar com atenção.
A qualidade dos dados é o primeiro grande desafio. IA paga só funciona se a atribuição permanecer confiável. Conjuntos de dados de baixa qualidade ou spam podem prejudicar a confiabilidade do modelo e enfraquecer a confiança no próprio sistema de recompensas. @OpenLedger usa camadas de staking e validação para reduzir esse risco, mas a rede ainda está no início de seu ciclo de maturidade.
A regulação é outra variável importante. Países do Sul Global estão ativamente reformulando estruturas de soberania digital agora. A Índia continua implementando estruturas de conformidade com o DPDP. A aplicação da LGPD no Brasil está evoluindo. Bangladesh ainda está refinando sua própria direção de governança digital. Se os sistemas de atribuição de IA descentralizados entrarem em conflito com os requisitos de privacidade nacional, a escalabilidade pode desacelerar significativamente.
Depois, há o clássico problema do efeito de rede. Modelos especializados precisam de grandes volumes de dados locais de qualidade antes de se tornarem competitivos comercialmente. Isso leva tempo. Os setores DePIN já nos ensinaram essa lição. Uma arquitetura forte não cria automaticamente uma adoção instantânea.
Ainda assim... não posso ignorar a mudança filosófica mais ampla que está acontecendo por trás de tudo isso.
Pela primeira vez, a infraestrutura de IA está começando a tratar os dados não como um resíduo passivo, mas como capital produtivo. Essa distinção é mais importante do que a maioria das pessoas percebe. Um agricultor contribuindo com padrões climáticos. Um médico fazendo upload de terminologia médica Bangla anonimizada. Um desenvolvedor treinando modelos de suporte ao cliente em idiomas locais. Em sistemas mais antigos, essas contribuições desapareciam em plataformas centralizadas. Nesta nova estrutura, elas podem teoricamente permanecer atribuíveis, possuídas e monetizáveis.
Isso muda os incentivos. E os incentivos eventualmente remodelam os mercados.
Como trader, sigo o fluxo de capital antes que as narrativas se tornem mainstream. Neste momento, o fluxo que continuo notando é em direção a projetos que resolvem atribuição, propriedade e coordenação de IA descentralizada. A OpenLedger não está sozinha nesta corrida, e nenhum projeto de infraestrutura de IA em estágio inicial tem sucesso garantido. Mas seu foco em Prova de Atribuição, Datanets e economias de IA de propriedade comunitária a coloca diretamente dentro de uma das mudanças estruturais mais importantes que estão emergindo no cripto hoje.
Talvez isso se torne massivo. Talvez evolua mais devagar do que o esperado. Hmmm... ambos são possíveis.
Mas uma coisa parece cada vez mais clara para mim: a próxima fase da IA pode não pertencer apenas a quem constrói os maiores modelos. Pode pertencer a quem possui as trilhas de dados mais valiosas. E se o Sul Global finalmente começar a capturar valor da inteligência que ajuda a criar, então a soberania dos dados deixa de ser teoria política e começa a se tornar realidade econômica.
