Spent most of today just watching things move sideways. Not in a dramatic way — just that slow, uncertain kind of sideways where nothing feels like it's going anywhere. So I ended up doing what I usually do in moments like that: clicked around, followed a thread I'd been meaning to follow for a while.
Ended up on @OpenLedger .
I wasn't expecting much. The "decentralized AI" space has gotten almost comically crowded — every other project has a whitepaper, a token, and a vague pitch about making AI open and fair. I've read enough of them that they start blurring together. So I went in a little tired, honestly.
But then something stopped me.
Here's what I kept seeing in other decentralized AI projects: the pitch is almost always about access. Democratize AI. Let anyone use the model. Remove the gatekeepers. And that sounds good — it is good, philosophically — but it quietly sidesteps the actual problem.
The actual problem isn't who uses the model.
It's who builds it. And more specifically: whether the thing being built is even verifiable.
That's the part that clicked for me when I was looking through how OpenLedger approaches contribution. Most projects treat AI development like a black box with decentralized branding painted on the outside. The training happens somewhere, the data gets sourced somehow, the model improves in ways nobody can really audit. You're just supposed to trust the roadmap.
OpenLedger seems to be doing something structurally different — tracking contributions on-chain. Not just outputs, but the actual inputs: data, compute, model work. The idea being that if you can record what went into the model, and attribute value back to whoever contributed it, you've actually changed the incentive structure of how AI gets built — not just who gets to run inference on the finished thing.
I thought that was a surface-level distinction at first. But actually, it's not.
Because here's what that changes: it means contributors — people providing real training data, real domain knowledge — have a reason to care about quality, not just quantity. Right now, most data markets are optimized for volume. You get paid for submitting data, so you submit data. What happens to it after is someone else's problem.
If contribution is tracked, attributed, and economically tied to model performance downstream, the person who submitted garbage data is eventually going to feel that. And the person who submitted genuinely useful, well-structured data is going to feel that too.
That's a different game. That's closer to how good research ecosystems actually work.
But here's the part that bothers me — and I want to be honest about this.
I'm not fully convinced this holds under pressure at scale. Attribution in AI training is genuinely hard. It's not like a blockchain transaction where you can trace a wallet address. Figuring out which data actually moved the model, and by how much, is a research problem that hasn't been cleanly solved. If the attribution mechanism is rough — or gameable — then the incentive structure breaks down pretty fast, and you're back to the same volume-over-quality problem with extra steps.
I don't know how OpenLedger handles this at the technical layer. I should probably go deeper there. But that's the question I'd want answered before I got too excited about the framing.
What makes this worth watching, even with that uncertainty, is that the question itself is the right one. Most projects in this space aren't even asking it. They're still selling access. OpenLedger seems to be asking: can you make the process of building AI legible and fair, not just the product?
That's a harder problem. Which is probably why nobody's really solved it yet. But it's also the problem that actually matters if decentralized AI is ever going to mean something real — not just rebrand the same closed development loop with a governance token attached.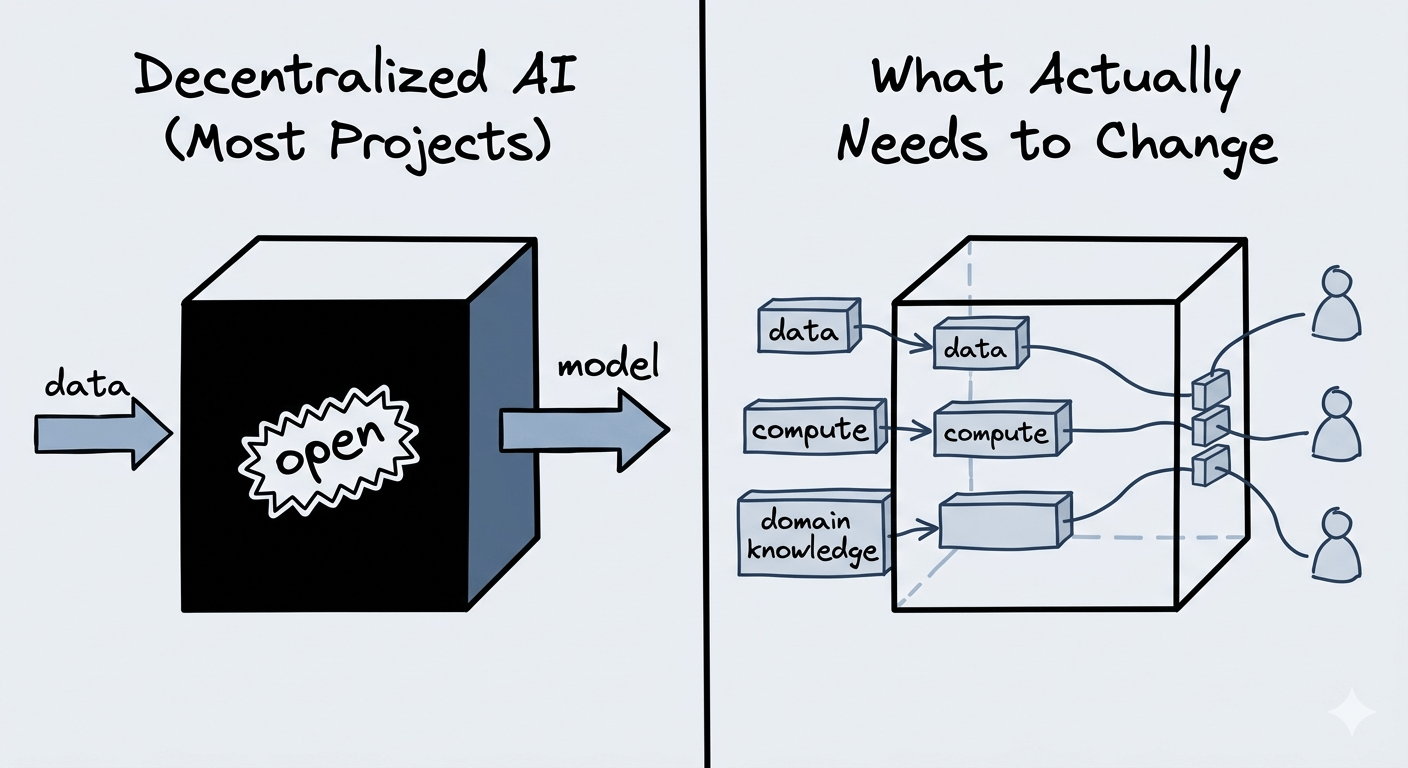
Who it affects most, if this works: domain specialists. People with real expertise who've always had knowledge worth paying for but no clean way to plug into AI development pipelines. That group has been completely left out of the current model. Interesting to think about what it looks like if that changes.