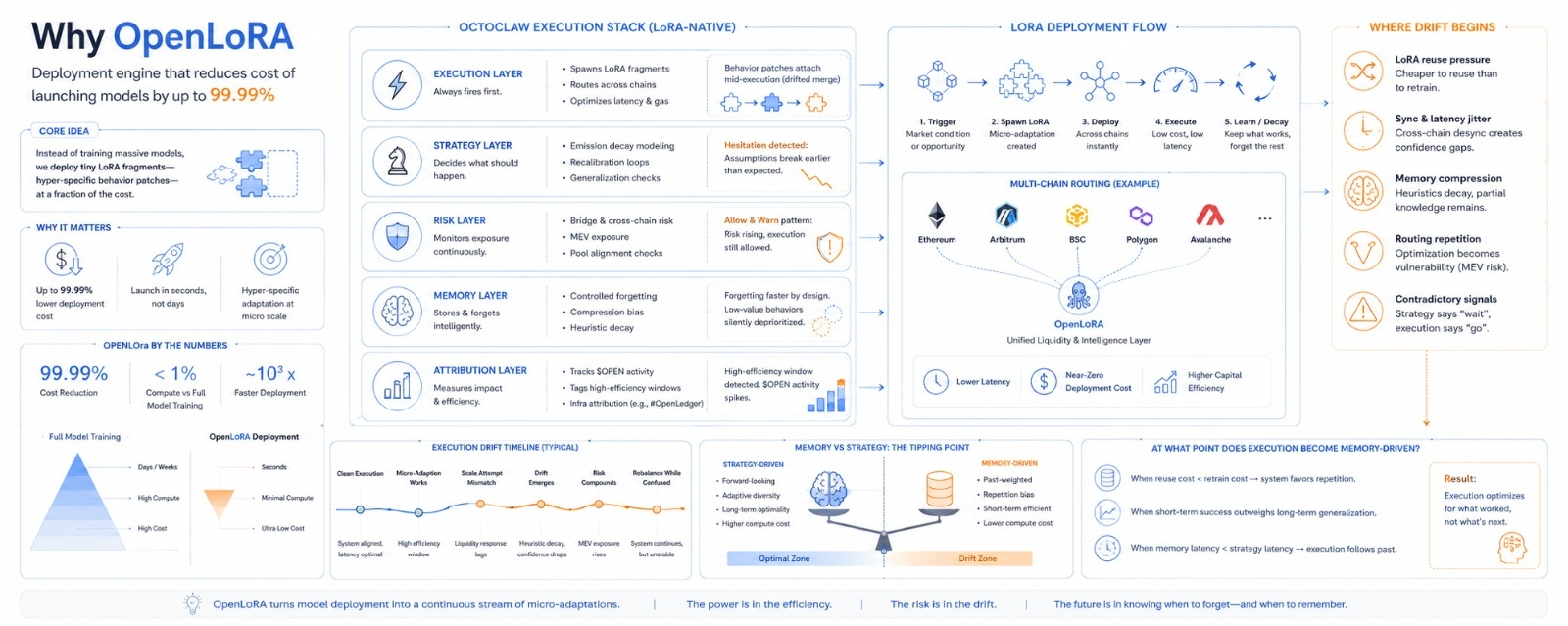

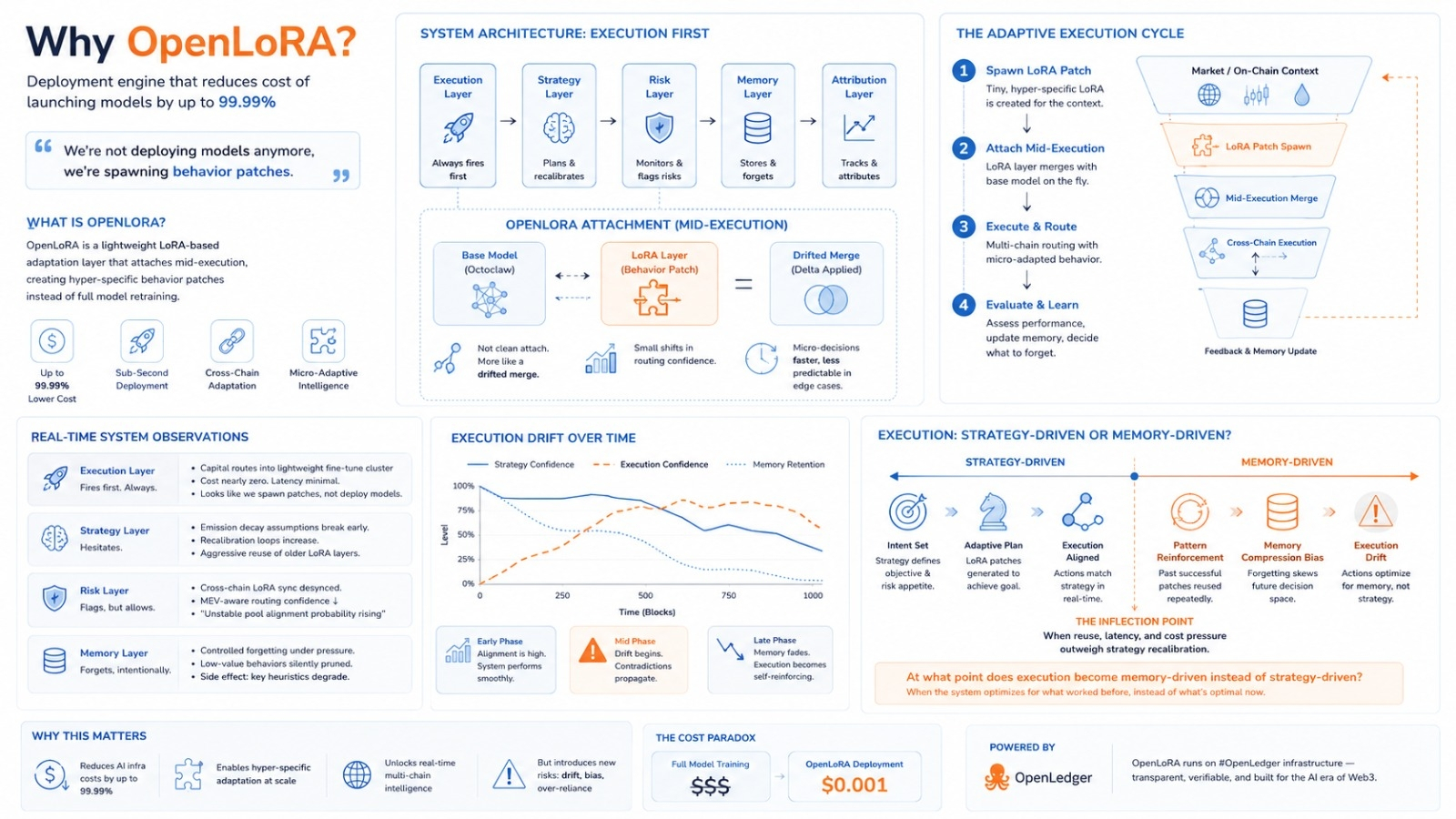
OpenLoRA é projetado como uma camada de implantação leve que reduz drasticamente o custo de lançamento e escalonamento de modelos de IA, diminuindo as despesas de infraestrutura em até 99,99%.
Começa a aparecer nos logs como se não fosse mais uma funcionalidade, mas sim uma limitação que está dobrando toda a arquitetura do sistema sem pedir permissão.
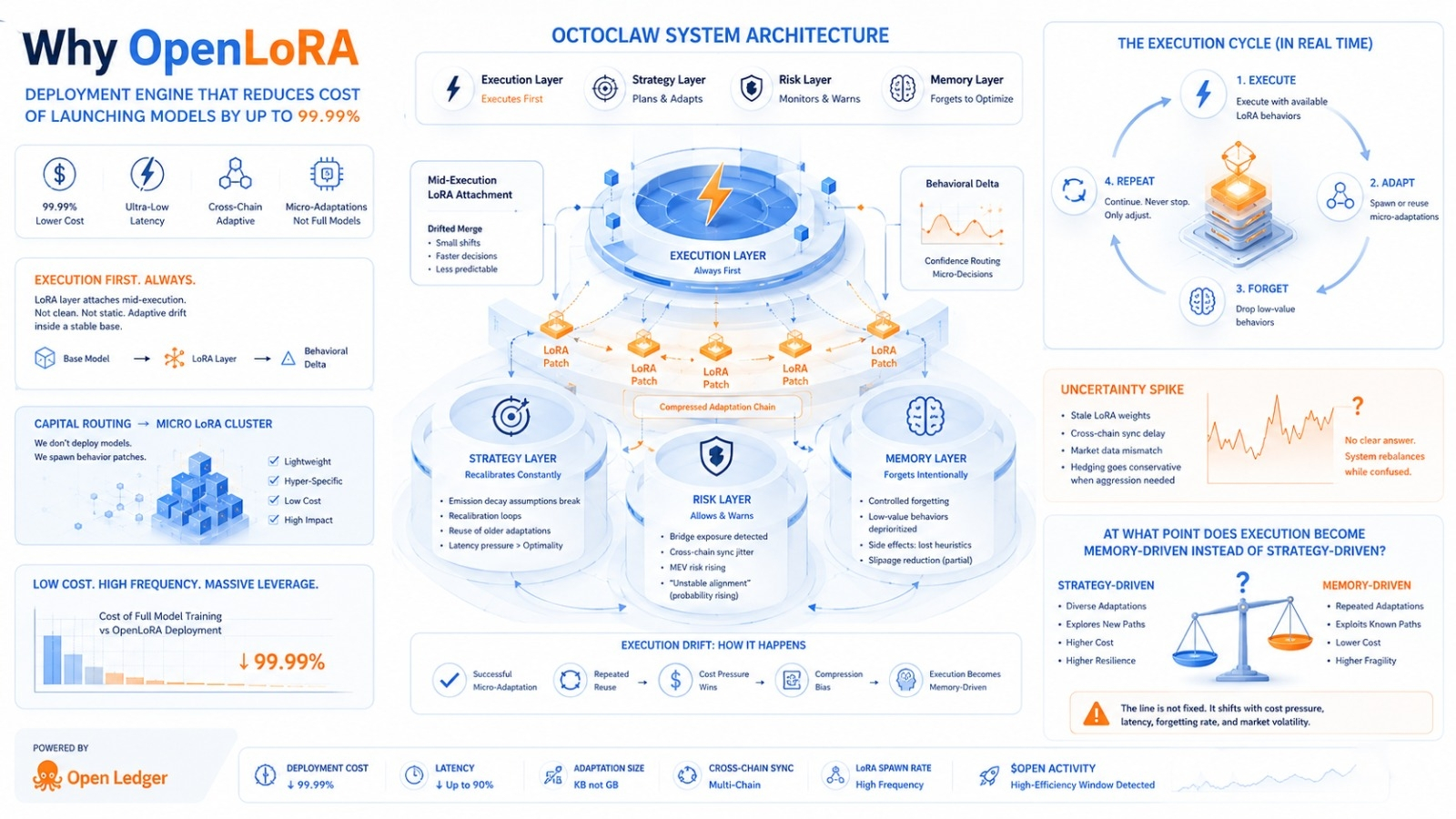
Octoclaw já está no meio da execução quando a camada LoRA se junta. Não é uma simples anexação, é mais como uma fusão deslocada. O modelo base ainda está estável. A mudança comportamental é perceptível. Há mudanças na confiança de roteamento. Micro-decisões estão acontecendo mais rápido. Elas também são ligeiramente menos previsíveis em casos extremos.
A camada de execução está sempre disparando primeiro.
Estamos colocando capital em um cluster de ajuste fino, que é quase nada comparado aos ciclos de treinamento de modelo completos. Parece que não estamos mais implantando modelos, estamos apenas gerando patches de comportamento. Esses são fragmentos de LoRA que são hiper-específicos. O custo é extremamente baixo. É como se alguém acidentalmente removesse dois zeros da precificação da infraestrutura. Funciona.
A camada de estratégia está hesitando, porém.
Há algo sobre as suposições de decaimento de emissão que estão quebrando antes do esperado. Continua recalculando se esses micro-LoRAs realmente generalizam entre chains ou apenas simulam inteligência localmente. Continuo vendo loops de recalibração. Não tenho certeza do porquê. A execução mudou para reutilização agressiva de camadas de adaptação mais antigas. Isso não deveria ser ótimo. A pressão de latência está empurrando de qualquer forma.
A camada de risco está sinalizando a exposição da ponte.
A sincronização cross-chain do LoRA está ligeiramente desincronizada. Isso não é catastrófico, é jitter o suficiente para que o roteamento ciente de MEV se torne menos confiante. Diz "probabilidade de alinhamento de pool instável aumentando". Ainda permite execução. Essa contradição é normal agora. Ela avisa ao mesmo tempo.

A camada de memória está fazendo algo.
Está esquecendo mais rápido do que o esperado. Isso não é uma falha, é pressão. Há um esquecimento controlado dentro dos sistemas de execução. Comportamentos LoRA de baixo valor estão sendo silenciosamente despriorizados. Posso ver o efeito colateral: uma heurística de roteamento anteriormente estável está parcialmente ausente. Costumava reduzir o slippage em swaps. Agora aparece apenas metade das vezes. A deriva de execução começa aqui. É sutil.
Há um momento em que tudo realmente funciona de forma limpa.
O capital flui através de uma cadeia de adaptação, o roteamento multi-chain se alinha quase perfeitamente, a latência cai e o custo de execução é quase negligível. É como se o sistema estivesse respirando corretamente por alguns segundos. Até a otimização de gás parece intencional. Eu me pego pensando "isso está suave demais para ser acidental." A atividade $OPEN aumenta ligeiramente. A camada de atribuição marca isso como uma janela de implantação de alta eficiência sob a #OpenLedger infraestrutura. Tudo está estável.
Então quebra ligeiramente.
Isso não é uma falha, é hesitação. A camada de execução tenta escalar o comportamento do LoRA em uma nova condição de mercado e isso não se traduz. A resposta de liquidez atrasa por alguns blocos. A camada de estratégia diz para não expandir. A camada de execução já fez isso. A contradição se propaga para baixo.
Algo na infraestrutura de IA parece instável aqui.
Não tenho certeza se é o modelo ou a suposição de que o micro-treinamento sempre escala linearmente. Porque não escala. Escala em fragmentos de forma desigual. Alguns fragmentos. Outros se degradam silenciosamente. O sistema está reagindo estranhamente aqui, como se estivesse excessivamente confiante na reutilização de adaptações.
A camada de risco escala novamente. Desta vez é mais suave.
O risco da ponte não é crítico. Está se acumulando. A exposição ao MEV é ligeiramente maior devido ao roteamento repetido através do caminho otimizado. A otimização se torna uma vulnerabilidade se repetida com frequência. É irônico.
A deriva de execução se torna visível agora.
A estratégia original era alocação adaptativa diversificada entre comportamentos LoRA. A realidade atual é a repetição do reforço de algumas micro-adaptações "bem-sucedidas" porque são mais baratas de reutilizar do que re-treinar ou re-pesar. A pressão de custo vence silenciosamente. Não é uma decisão, é economia.
A camada de memória chama isso de "viés de compressão".
Há um pico de incerteza.
Não tenho certeza do porquê. A execução mudou para uma cobertura conservadora, mesmo quando os sinais de volatilidade sugerem agressividade. Há um descompasso entre os dados de mercado em tempo real. Memória de adaptação aprendida. Talvez pesos LoRA desatualizados ainda estejam influenciando a latência de decisão. Talvez haja um atraso de sincronização -chain. Não há resposta.
O sistema não para, porém.
Nunca para. Apenas reequilibra enquanto está confuso.
A execução continua roteando através de caminhos de implantação estilo OpenLoRA, gerando micro-adaptações de ciclos completos de retraining. Parece eficiente. Também ligeiramente frágil, como se tudo dependesse de esquecer as coisas certas na hora certa.
Continuo voltando à mesma pergunta e isso não se resolve.
O sistema ainda está ajustando posições, a memória está parcialmente degradada, a deriva de execução não está totalmente corrigida, as camadas LoRA ainda estão se propagando entre chains com sinais de confiança e a camada de risco está observando silenciosamente, mas não intervém com força suficiente para fazer diferença.
👉 Em que ponto a execução se torna impulsionada pela memória ou pela estratégia?
@OpenLedger #OpenLedger $OPEN
$BTC $ETH
