
@OpenLedger When I first looked at inference fees inside decentralized AI systems, I honestly thought it was mostly API bookkeeping.
Input tokens go in. Output tokens come out. Users get charged.
Simple enough.
What changed my view was realizing the fee itself is not really the product 👀
Inside OpenLedger, the fee is acting more like a routing mechanism for economic eligibility.
And once I noticed that, the whole structure started looking very differnt.
Most people still interpret inference pricing through the old software lens. You pay for access, the platform keeps the margin, contributors stay invisible somewhere underneath the stack.
That assumption made sense when AI systems behaved mostly like centralized utilities.
But OpenLedger’s tokenized inference changes the accounting layer itself.🐙
An input token is not just text entering a model anymore. Structurally, it behaves more like a measurable dependency request.
Large prompts increase retrieval pressure, memory exposure, bandwidth coordination, and dataset reliance all at once.
A longer context window sounds cosmetic on the surface.
Underneath, it quietly expands the number of contributors involved in generating one answer.
That shift creates another effect.
Output tokens stop behaving like simple generation costs and start behaving like execution intensity signals.
Longer outputs consume more GPU cycles, validator coordination, latency management, and verification overhead. What users experience as “better reasoning” often means the network is absorbing significantly higher infrastructure strain behind the scenes.
Some estimates already project global inference demand to surpass $200B annually before the end of the decade.
The number itself matters less then what it signals.
Inference is slowly becoming the dominant operational layer of AI economics, not training.
Meanwhile context windows across major systems expanded nearly 16x to 32x since 2023.
At first glance that looks like a capability race.
But structurally, larger context windows increase dependency on external retrieval systems, archived datasets, and attribution routing.
The network starts depending less on static model memory and more on coordinated information access.
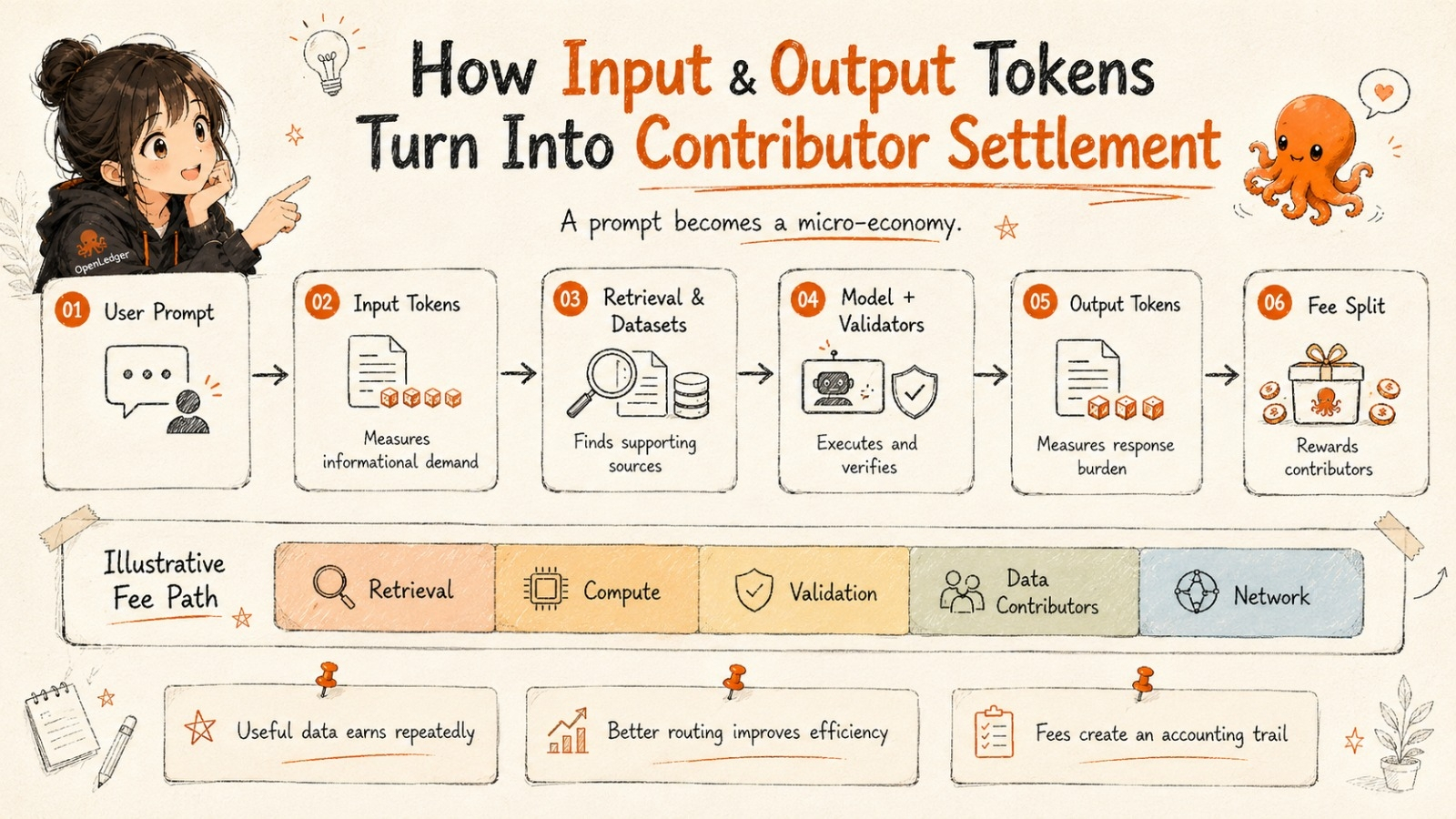
Understanding that changes how I see OpenLedger inference fees entirely.
The interesting part is how token measurement turns into contributor settlement.
A request enters the network.
The system measures retrieval depth, execution workload, contextual dependency, validator participation, and output generation load.
Then fragments of the fee get distributed proportionally across whichever contributors participated in the response pathway.
That sounds abstract until you translate it plainly.
The fee itself becomes an accounting trail.
Centralized AI systems already operate with inference margins reportedly exceeding 70% in some enterprise API environments.
Most users never see where that margin concentrates.
That invisibility is important because hidden contribution structures create hidden bargaining power too.
OpenLedger is trying to expose that invisible layer directly.
Not perfectly.
But visibly enough that contributors can begin competing economically for usefulness instead of access.
And usefulness is becoming measurable in a strange new way.
Datasets are no longer valuable simply because they exist.
They become valuable if retrieval systems repeatedly depend on them during live inference.
That distinction matters alot.
Because it transforms static data ownership into recurring economic participation.
What becomes visible here is that token accounting quietly reshapes behavior.
Contributors optimize for retrieval relevance.
Model providers optimize for efficient execution paths.
Validators optimize for coordination reliability.
The network slowly rewards utility density instead of pure scale.
Atleast in theory.
There is a reasonable case for the opposite view though.
Systems like this can become incredibly complex very fast.
Micropayment fragmentation creates accounting opacity.
Attribution disputes become harder as retrieval paths overlap.
And sybil-style contribution farming could easily distort payout quality if verification standards stay weak.
The network might end up rewarding manipulation instead of usefulness.
That risk feels very real.
Meanwhile broader market behavior is already moving toward systems that prioritize verification over pure generation speed.
Institutional AI spending kept increasing this year while regulatory pressure around auditability and attribution also intensified.
That combination matters.
Capital still wants AI exposure, but increasingly inside structures where accountability can be inspected afterward.
Inference accounting fits naturally into that direction.
Trading activity across AI-linked digital assets also became heavily rotational during stronger liquidity weeks.
Volume spikes often move from $2B toward $5B or higher in short windows whenever infrastructure narratives gain momentum.
Most people interpret those rotations as speculation.
Partly true.
But underneath, markets are also searching for systems that can coordinate value distribution more predictably.
Not just generate outputs faster.
And that may be the deeper shift underneath all of this.
Older internet systems monetized attention.
Inference systems are beginning to monetize contextual dependency itself.
Inside OpenLedger, input tokens effectively measure informational demand.
Output tokens measure execution burden.
The fee sitting between them becomes a programmable coordination layer connecting contributors, infrastructure, retrieval systems, and computation into one temporary economic event.
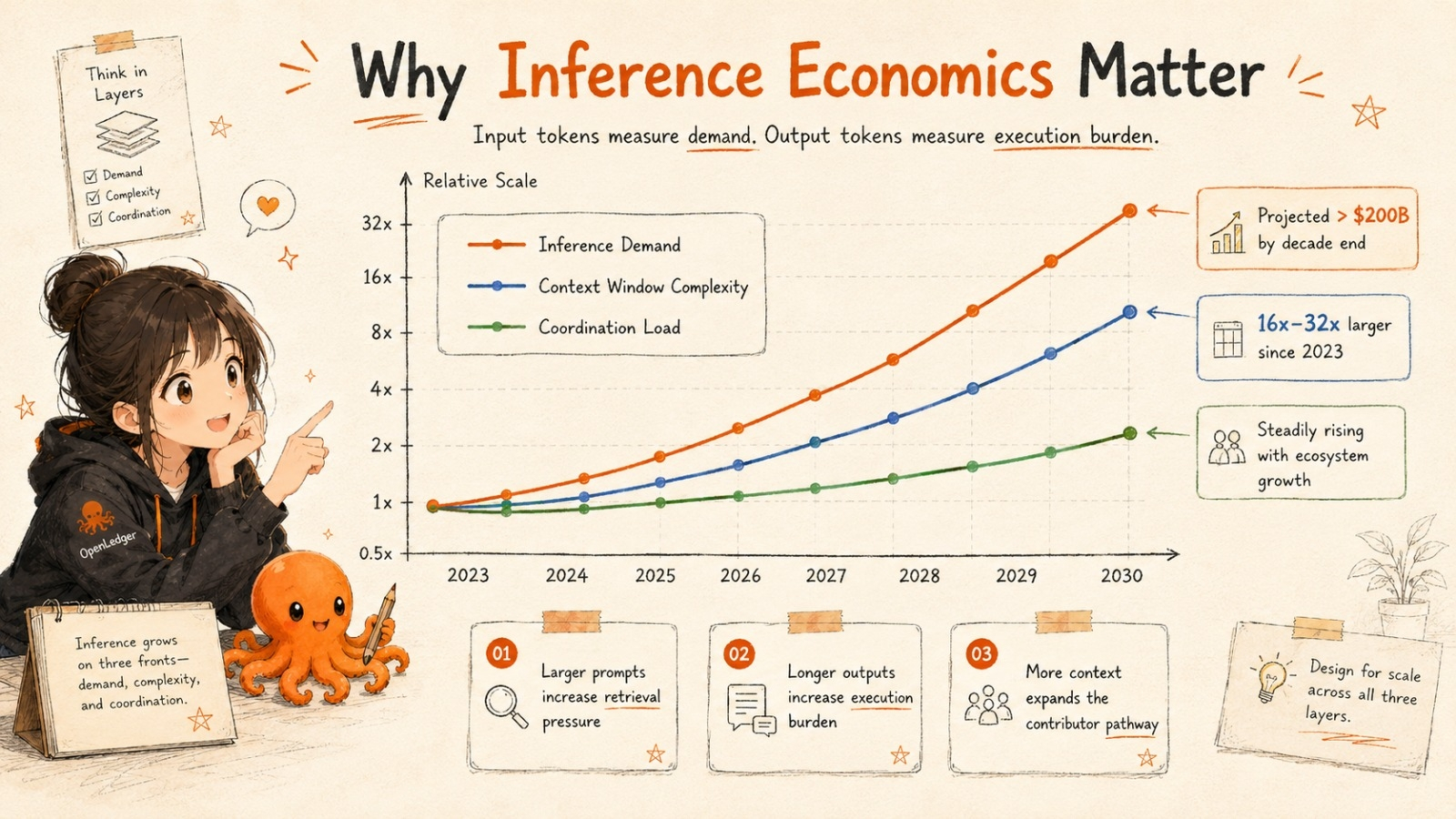
A single prompt starts looking less like software usage and more like a micro-economy.
In some contexts, this model could fail completely.
High quality datasets might centralize power again.
Expensive inference costs could reduce accessibility.
Networks might over-optimize toward profitable information while neglecting socially useful but economically weak data.
That tension probably does not disappear.
It just becomes measurable.
Still, the direction feels difficult to ignore.
The more AI systems rely on retrieval, attribution, and distributed coordination, the harder it becomes for inference pricing to remain invisible infrastructure.
Fees stop behaving like passive charges.
They begin behaving like governance signals for who the network economically recognizes.
And once contribution becomes traceable during live execution, OpenLedger starts looking less like platform monetization and more like continuous settlement.
Quietly, that changes everything 🤔