
Uma e meia da manhã, eu fechei a página do GitHub do OpenLedger, esfreguei os olhos e pensei que precisava escrever algo. Estou de olho nesse projeto há um tempo, a primeira vez que vi foi na lista de ecossistemas do EigenLayer, depois percebi que a Polychain liderou a rodada seed. Para ser sincero, aqueles 8 milhões de dólares não são um valor tão alto, mas no jogo de dados + IA, é um sinal de que uma instituição respeitável entrou no ringue.
Eu não sou o tipo que se empolga só porque viu o valor do financiamento. Já quebrei a cara antes, tinha um projeto de mercado de dados, investi uma grana e no final descobri que os conjuntos de dados eram todos lixo adquirido por crawlers, a qualidade era péssima e o token foi a zero. Por isso, dessa vez eu peguei a parte 'datanet' do whitepaper do OpenLedger e li duas vezes com atenção.
Vamos falar sobre o 'livro de registro de contribuição de dados rastreável' que eles estão fazendo. Oficialmente, isso é chamado de 'prova de atribuição'. Simplificando, você envia um conjunto de dados e o sistema gera algo como uma impressão digital dos dados, registrada na blockchain. Depois, quando alguém usa seus dados para treinar um modelo, os resultados intermediários gerados pelo modelo são verificados com essa impressão digital. Se bater, um contrato inteligente dispara e te paga em $OPEN. Esse mecanismo é mais inteligente do que o simples upload e download, porque considera 'o uso real dos dados' como uma condição para pagamento, e não apenas 'o dado foi disponibilizado'.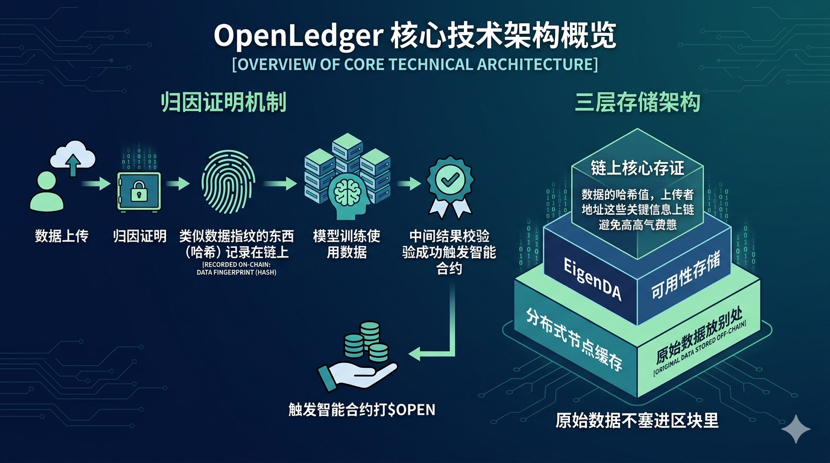
O white paper menciona uma arquitetura de armazenamento em três camadas, com a prova central na blockchain, armazenamento de disponibilidade do EigenDA e cache de nós distribuídos. Em termos simples, apenas os hashes dos dados e os endereços dos uploaders são registrados na blockchain, enquanto os dados originais ficam em outro lugar. Isso garante a rastreabilidade sem encher o bloco com várias TB de imagens, evitando que as taxas de gás estourarem.
Mas o que me parece mais confiável é outra questão. O cofundador do projeto, Ram Kumar, mencionou em uma entrevista que a maior diferença entre eles e a HuggingFace é que 99% dos conjuntos de dados na HuggingFace não são utilizados, enquanto a OpenLedger força a qualidade dos dados através de incentivos econômicos. Isso é uma afirmação bastante realista, pelo menos mostra que a equipe sabe onde estão os problemas.
Mas os problemas também estão surgindo. Eu vejo três áreas que precisam ser mais bem pensadas.
Primeiro, o modelo econômico conseguirá se fechar? O white paper deu um exemplo: uma taxa de inferência custa 1.14 $OPEN, a plataforma fica com 0.5, sobrando 0.64, onde o provedor do modelo recebe 0.448, o staker fica com 0.064 e os contribuintes de dados dividem 0.128. Atenção, esse 0.128 é dividido entre todos os contribuintes de dados, então na prática cada um recebe bem menos. Eu entendo a ideia de open source, mas se o incentivo para os contribuintes for tão baixo que não dá pra ver, quem vai querer subir dados de alta qualidade? Isso se torna a velha questão do ovo ou da galinha. O projeto pode estar contando com a valorização do token para cobrir essa diferença, mas o preço do token é algo incerto.
Segundo, a dificuldade de implementação da colaboração distribuída. Não encontrei os números específicos sobre a latência da testnet mencionada no documento oficial, mas eu mesmo já rodei treinamentos distribuídos semelhantes e só a sincronização de estado entre os nós pode deixar você maluco. A OpenLedger usa o AVS do EigenLayer, ou seja, um serviço de validação ativa para garantir a segurança econômica, essa lógica de design está correta, os nós de validação que trapacearem serão multados. Mas a questão chave é a eficiência, milhares de máquinas executando juntas, cada iteração precisa sincronizar milhares de vezes; acumulando, será que a eficiência consegue acompanhar? Só saberemos isso depois que a mainnet rodar por um tempo. Até agora, não vi dados de desempenho concretos sendo apresentados oficialmente.
Terceiro, quem vai garantir a qualidade dos dados? Os nós de validação só podem fazer verificações aleatórias, se alguém maliciosamente fizer uploads de muitos dados de baixa qualidade e não for selecionado, como o sistema vai se proteger? O documento oficial menciona esse conceito de 'pontos de reputação', mas não consegui encontrar detalhes sobre como os pontos são acumulados ou como as penalizações funcionam, eu olhei duas vezes e não achei. Parece que ainda está em fase de design. Isso é um pouco preocupante, porque o verdadeiro problema do mercado de dados nunca foi 'ninguém está uploadando', mas sim 'o que está sendo uploadado é utilizável?'.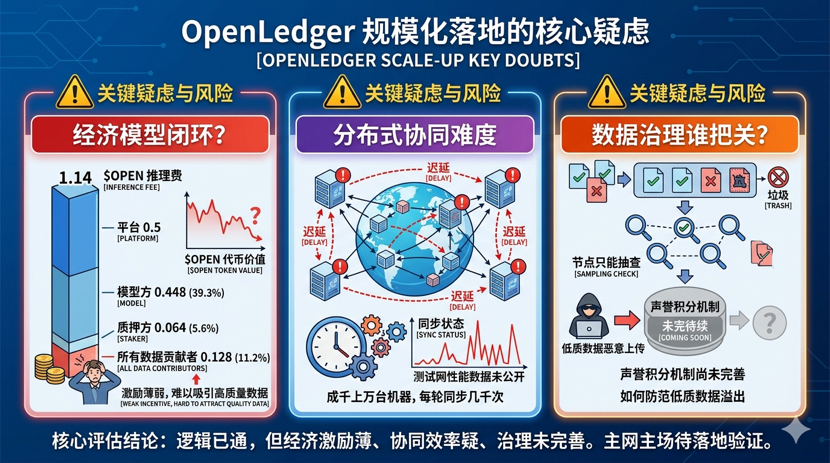
Mas falando sério, acho que tem um ponto nesse projeto que merece um elogio: eles não prometeram 'substituir o treinamento de IA centralizada', mas sim que estão focando em 'conjuntos de dados nichados, de alto valor e que precisam de proteção de privacidade'. Essa é uma posição bem honesta. Por exemplo, dados de imagem médica e anotações de risco financeiro, esses dados ninguém quer enviar para a rede pública, mas com o ambiente de execução confiável da OpenLedger e a contabilidade em blockchain, realmente pode ser possível explorar uma parte desse mercado existente. Já dá pra ver alguns casos de teste no GitHub oficial, que são focados em treinamento privado de dados médicos, não é só conversa.
Meu julgamento pessoal agora é que a lógica do livro razão está clara, mas a escala e a governança ainda não foram testadas. O oficial mencionou em uma AMA no início deste ano que o primeiro mercado de dados da mainnet deve ser lançado no primeiro trimestre. Vou esperar por isso para fazer as contas. Não estou com pressa para entrar, nem vou descartar tudo de uma vez. Eu só sigo uma regra: vou esperar a primeira transação real de dados acontecer e o primeiro caso de upload malicioso ser pego e tratado. Depois disso, vou olhar os números no livro razão para decidir. Por enquanto, estou de olho, mas não vou tirar todo o dinheiro do meu bolso.
Por último, só uma coisa: investimento tem risco, não saia correndo só porque alguém falou bem, leia os documentos oficiais com calma.
