Esta manhã, eu estava revisando uma tabela antiga de anotações sobre modelos de IA que já fizeram barulho, e uma sensação familiar voltou. As coisas que o mercado elogia mais alto muitas vezes não são as que entendem mais profundamente. É exatamente isso que chamou minha atenção para a Openledger, não porque fala mais alto que os outros, mas porque se concentra em um problema menor, mais difícil e mais real: como bolsões de conhecimento altamente especializados, densos em contexto, podem ainda manter seu espaço em vez de desaparecer em uma massa de entendimentos médios.
O que me fez ficar com isso por mais tempo está em Datanets. Muitos projetos falam sobre dados em termos muito amplos, como se reunir uma quantidade suficiente já fosse o bastante. Essa forma de pensar funciona na superfície, mas perde a essência do conhecimento de nicho, onde a precisão não vem da escala, mas da estrutura, contexto e rotulagem. A Openledger vai em outra direção ao tentar preservar as fronteiras dos dados, com proveniência, contribuidores, condições de uso e timestamps intactos. O conhecimento estreito geralmente não desaparece porque não tem valor, desaparece porque é dissolvido muito cedo.
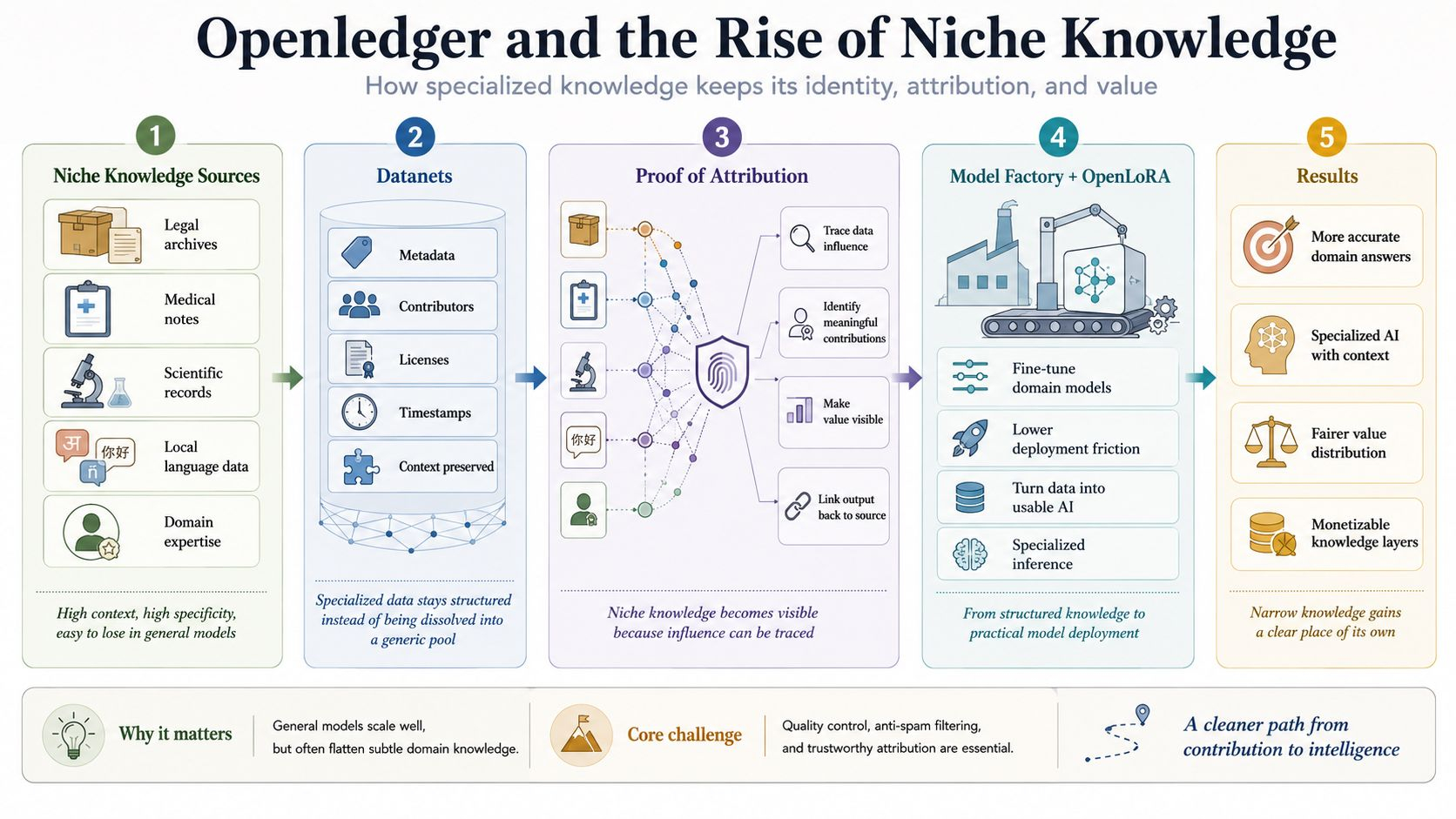
É por isso que este projeto não pode ser lido simplesmente como um lugar que reúne dados e depois os alimenta no treinamento de modelos. O que importa muito mais é que a Openledger está tentando transformar dados especializados em uma camada com seu próprio direito de existir. Uma vez que os dados estão organizados como uma unidade que pode ser contabilizada, a questão da contribuição não está mais no nível da ética, mas passa para o nível da arquitetura. Passei por ciclos suficientes para ver que o mercado sempre prefere falar sobre modelos ou produtos finais, enquanto a parte que realmente cria precisão é empurrada para as sombras.
É exatamente por isso que a Prova de Atribuição é a parte que peso mais fortemente. Muitas pessoas ouvem esse termo e assumem que é apenas uma camada extra adicionada para tornar a história mais interessante, mas na realidade é aqui que a Openledger está apostando na mudança mais difícil, rastreando quais conjuntos de dados influenciam um resultado e quais contribuições têm peso real. Qualquer um que tenha construído sistemas de dados provavelmente entende isso, rastrear influência nunca foi fácil, especialmente quando os resultados são criados através de múltiplas camadas empilhadas de processamento. Mas essa dificuldade é exatamente o que lhe dá valor.
Dando um passo adiante, acho que essa ideia só se sustenta se a atribuição não for separada da implementação do modelo. É aí que a Model Factory e o OpenLoRA entram como duas partes que não podem ser tratadas como secundárias. A Openledger não quer apenas preservar o rastro do conhecimento especializado, ela também quer abrir um caminho para que esses dados se movam para modelos ajustados e depois para operações reais sem morrer no meio do caminho porque o custo é muito alto ou o processo é muito pesado. Muitas ideias corretas falham simplesmente porque a distância dos dados à aplicação é maior do que a resistência do construtor.
Eu também não vejo essa história com nenhuma suavidade. Qualquer sistema que vincule recompensas à influência de dados eventualmente enfrentará o lado obscuro dos incentivos. As pessoas podem inundá-lo com mais dados apenas para se encaixar na cadeia de atribuição. Elas também podem aprender a otimizar para ser contadas como influentes, em vez de realmente melhorar a precisão. Por essa razão, a Openledger precisa de mais do que uma ideia correta, precisa de uma disciplina muito rigorosa de filtragem e seleção. Honestamente, é aqui que muitos projetos acabam revelando sua verdadeira natureza.
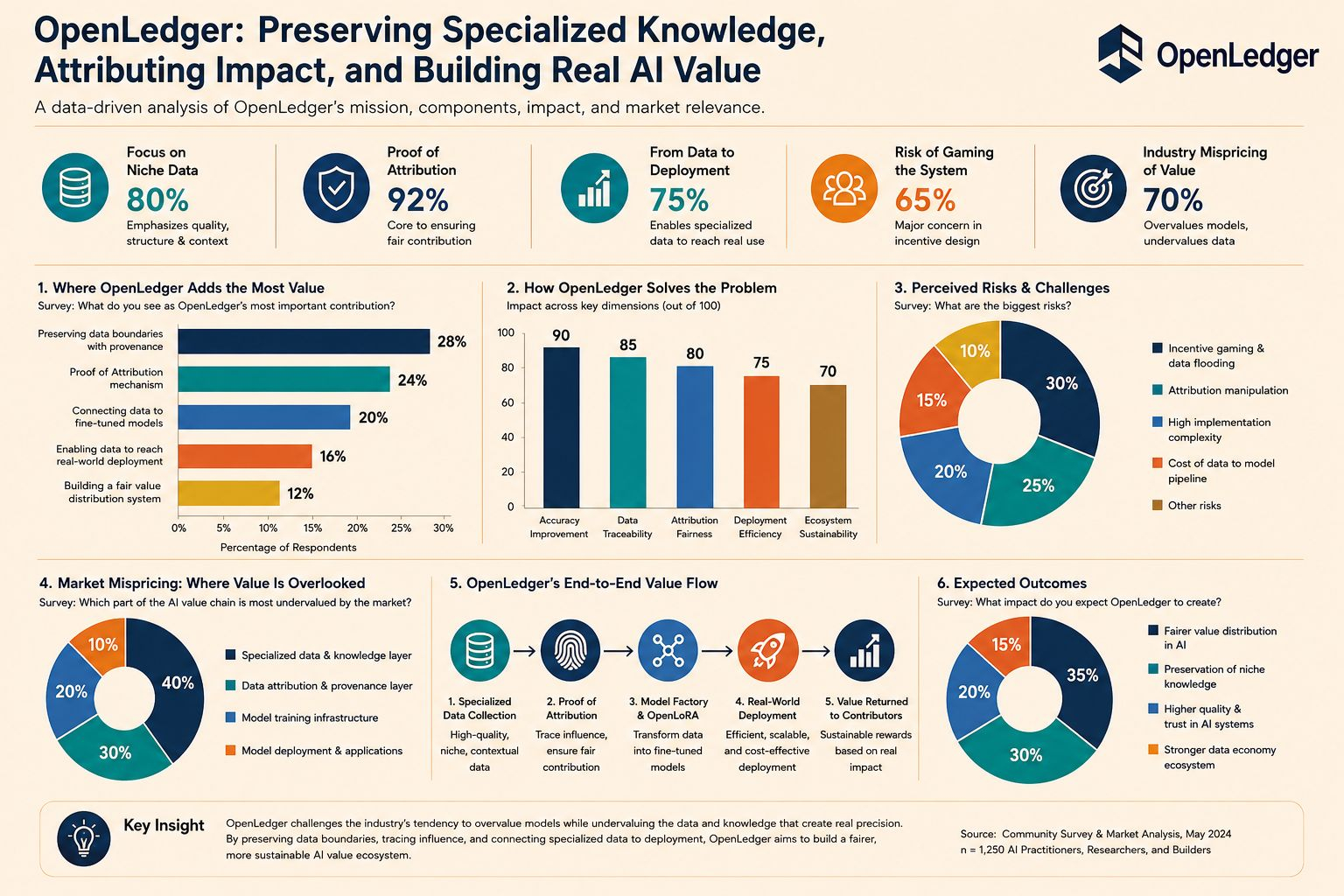
O que me faz valorizar esse esforço é que ele vai contra o instinto familiar da indústria. Em vez de construir mais uma camada de modelo que afirma entender tudo, a Openledger admite implicitamente que existem domínios de conhecimento que não devem ser forçados à lógica das médias. A expertise profunda em campos estreitos não precisa ser inflacionada em uma grande narrativa, precisa de um pipeline limpo o suficiente para preservar o contexto e a contribuição que produzem precisão. Essa é uma diferença de postura, não apenas uma escolha técnica.
O que considero mais digno de reflexão após olhar de perto para essa estrutura é que o mercado pode ter estado precificando mal o valor desde o início, recompensando generosamente a camada final de agregação, enquanto subestima a camada silenciosa de conhecimento que cria precisão. Quando um sistema tenta preservar os limites dos dados, rastrear influência, conectar dados especializados a modelos ajustados e trazê-los para uso real, a Openledger está tentando corrigir como o valor é distribuído em IA de uma maneira muito mais rigorosa. E se a Openledger realmente conseguir manter o conhecimento estreito de afundar na confusão entre contribuição e resultado, o mercado ainda continuará adorando uma inteligência ampla, mas rasa, como um padrão bom o suficiente.