the part of OpenLedger that kept bothering me wasn't the output.
It was the route history after the route already fired.
PoA looked clean.
Fine.
Still wasn't the runbook.
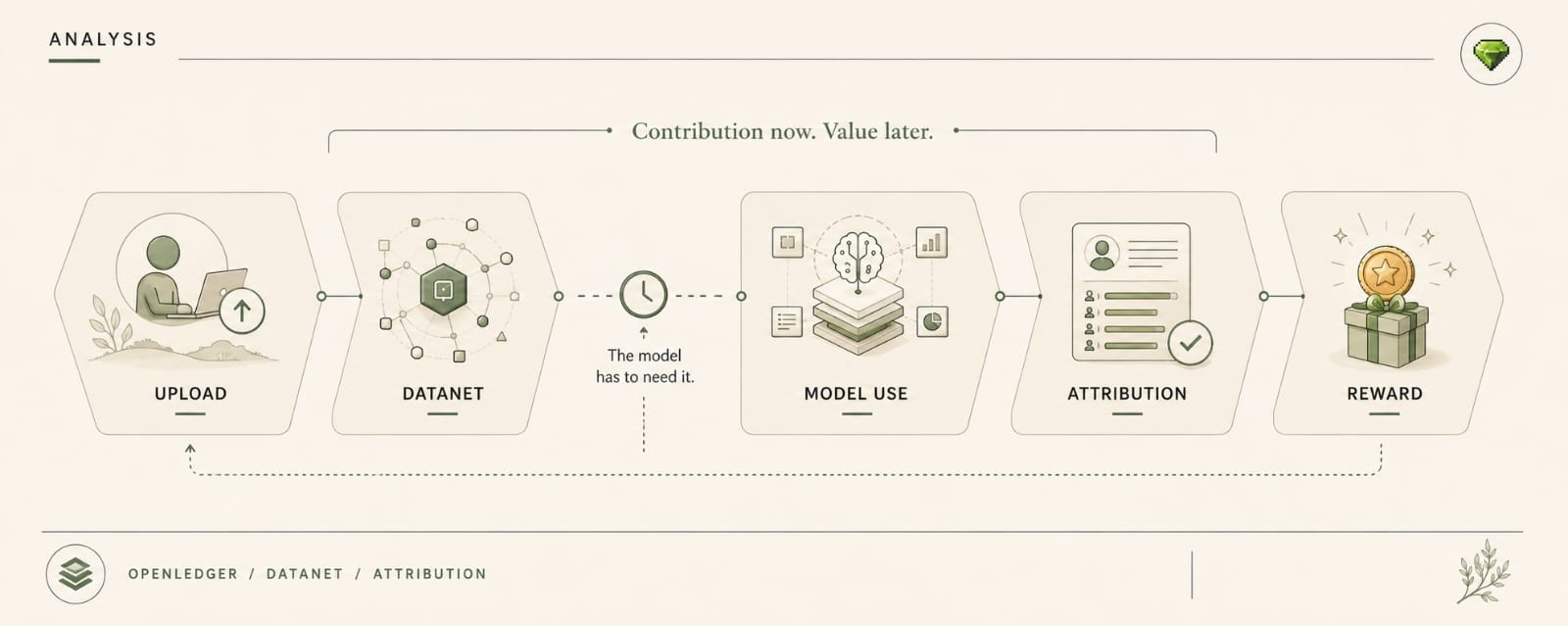
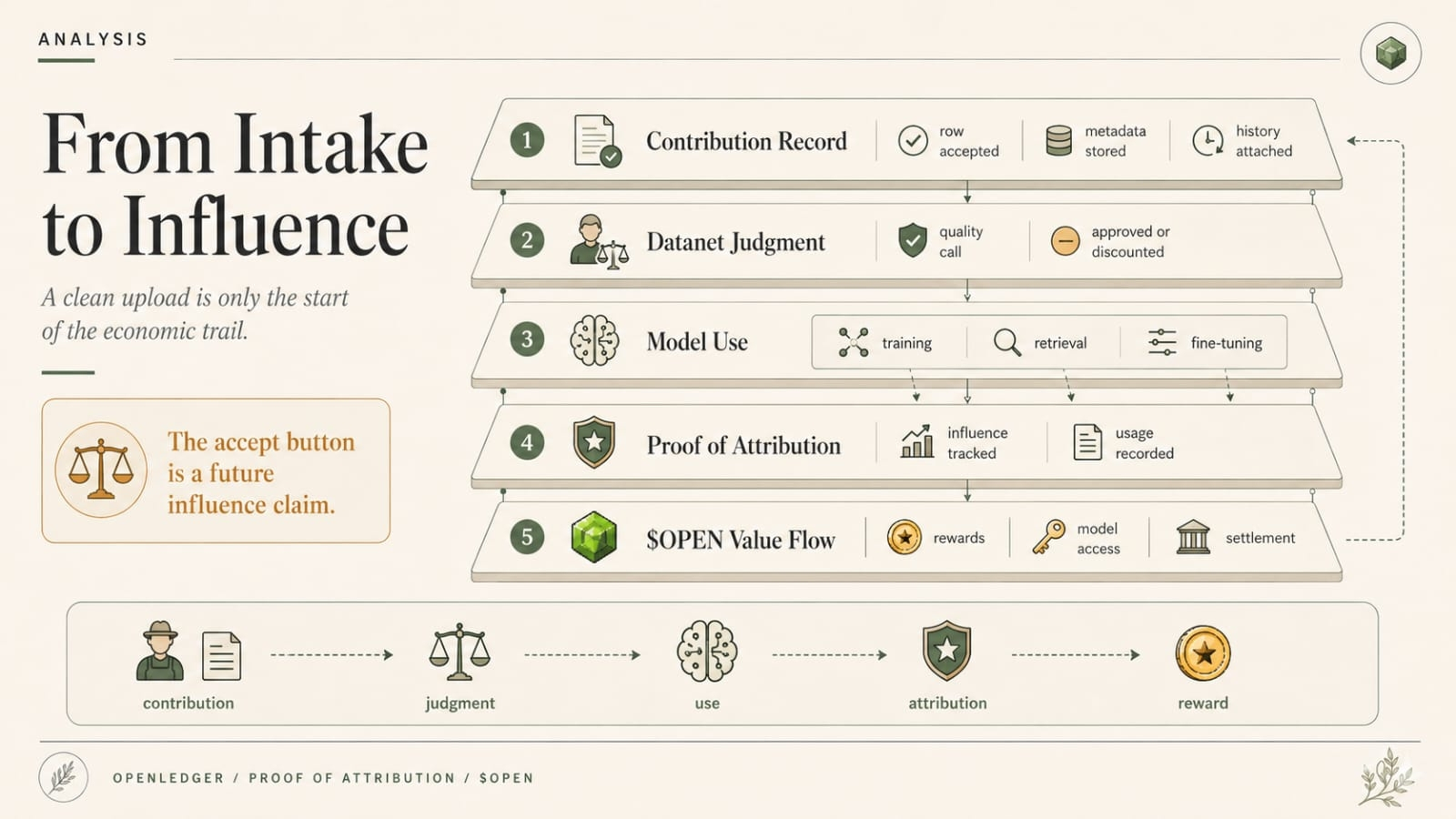
Thats where OpenLedger gets more interesting than the easy pitch version. Datanet source, OpenLoRA adapter, ModelFactory packaging, PoA trail, OctoClaw action path. On paper, good. Coherent, even.
But the paper version isn't where this gets tested.
That version holds up right until somebody serious asks a second question.
Thats the hour I keep getting stuck on.
Not what did the agent output.
More like... what actually happened here?
Thats where OpenLedger gets interesting to me. Not because the stack is fake. I think the stack is real. Datanets for source material. OpenLoRA for specialized serving. ModelFactory for packaging usable agents. PoA for tracing contribution. OctoClaw for turning outputs into actions when the workflow can justify it.
On paper, that’s one of the cleaner attempts I’ve seen to make AI infra less hand-wavy and more operational.
Say a firm runs a specialized OpenLedger agent. Nothing dramatic. Not an exploit. Not a scandal. Just ordinary use. Treasury monitoring. Exception routing. Research generation that ends up in an internal dashboard or kicks an OctoClaw path because the Datanet source looked strong enough and that agent family had already built enough trust inside the desk.
Fine. That is exactly the kind of thing OpenLedger should make possible.
Then somebody opens the route history instead of the output, and the mood changes.
Then quarter close hits. Or audit prep. Same difference once people start signing files.
A risk team wants to know why one OctoClaw route fired and the fallback didn’t. A partner asks why one exception was allowed and another wasn’t. Internal review asks why that source branch woke up there instead of one step earlier, when the queue still could have slowed it down.
Nobody is asking for raw internals because they love paperwork. They’re asking because somebody has to sign their name under the decision later.
And nobody likes discovering at sign-off time that “traceable” was doing a lot of lazy emotional work.
That is the exact moment where a traceable output stops being the whole answer.
Oversight people do not always want attribution. They want chronology. Route choice. What changed, when it changed, and whether the explanation still holds up once liability gets attached to it.
They want, basically, the runbook.
Not the polished diagram. The ugly sequence.
That part gets skipped all the time.
PoA is good at narrowing what contributed. OpenLedger is built around that.
But “show me the source path” and “explain the decision path” are not the same threshold. The second one moves around depending on who is asking and what they’re going to be blamed for later.
If an agent on OpenLedger produces a traceable result without turning the whole workflow into black-box theater, then technically the system worked. Fine.
Then the counterparty says... I accept that the output was attributable. Now explain the path that led there. Not every raw input, maybe. But the retrieval sequence. The branch that won. Why one source family got leaned on harder than another. Why OctoClaw fired here at all.
By then nobody wants the full mess.
They want enough story to sign off without owning blind risk.
Who decides what gets opened at that point?
The protocol?
The app developer?
The enterprise running the workflow?
The team that shipped the agent through ModelFactory and called it production-ready?
The examiner who does not care how elegant the stack is and just wants enough sequence to clear the file?
At that point, this is barely an attribution problem anymore.
Call it governance or don’t. Same headache.
The harder OpenLedger problem isn’t tracing the output. It’s whether the run can be made legible enough for real oversight without pushing everyone straight back into blind trust with better branding.
Doesn’t make OpenLedger weaker.
Just moves the hard part somewhere uglier.
And that’s what adoption pressure actually looks like when institutions get involved.
Not do people say they want attributable AI? Everyone says yes to that. The harder test is what happens when attribution has to survive contact with institutions that still need an explainable record of why a decision, route, or action was acceptable.
Because at that point OpenLedger is not just tracing things.
It is deciding how much of the agent’s story gets to exist outside the clean output.
Real liability is where that boundary stops looking clean.
And the operational scar here is worse than people admit.
A PoA trail can stay tidy.
The Datanet path can stay real.
The output can stay perfectly attributable.
And the room can still be stuck because nobody can cleanly answer why this branch fired, why this source mix won, why the confidence threshold was treated as enough, or why the action moved before someone expected it to.
That is the part I keep coming back to.
The output is not the same thing as the runbook.
A lot of AI infra still acts like it is.
Once OpenLedger gets used in workflows that move money, risk, access, ranking, routing, whatever ugly little real-world thing comes next, that gap gets expensive fast.
Because by then nobody is asking whether the output was traceable in the abstract.
They’re asking something meaner.
The route already fired. The result already counts.
Who can reconstruct the decision path well enough to defend it now?