Market's been kind of flat lately. Not the exciting kind of flat where you know something's building — just... quiet. I found myself clicking through random project dashboards out of habit more than anything else.
That's how I landed on @OpenLedger .
I wasn't looking for anything specific. I think someone mentioned it in passing in a thread about AI data infrastructure, and I opened the tab, forgot about it, then came back to it an hour later. And I sat with it longer than I expected.
Here's the thing that got me.
Everyone's talking about OpenLedger like it's an AI data marketplace. Which it is, technically. But that framing misses what's actually being built underneath it — and I think that gap between the surface description and the actual structure is where most people are walking away with the wrong takeaway.
What I kept coming back to was this: the ecosystem isn't designed around data transactions. It's designed around data dependency.
There's a difference, and it's subtle enough that it doesn't show up in most write-ups.
A marketplace moves assets. Buyers come in, pay, leave. The platform sits in the middle and takes a cut. That's a fine business. But it doesn't compound. If the marketplace goes quiet, nothing holds it together.
What OpenLedger seems to be building — and I'm still working through this — is a system where the more AI models use the network to train and verify outputs, the more those models become entangled with the network's data rails. Not locked in by contract. Entangled by architecture. The verification layer, the attribution layer, the contribution tracking — all of it creates a structure where leaving gets expensive over time, not because of fees, but because of what you'd lose in provenance and trust history.
I thought at first this was just a fancy way of saying "network effects." But it's not quite that either.
Network effects are about users attracting users. This is more like infrastructure entrenchment — the kind that happens slowly, then suddenly. Similar to how AWS didn't win because it was the cheapest. It won because enough systems were built assuming it would be there.
That's the long-term bet buried in OpenLedger's design. Not "we have the most data." More like: "the process of verifying AI outputs starts to run through us, and over time, that process becomes load-bearing."
But here's the part that genuinely bothers me.
That kind of entrenchment takes time. A lot of it. And in crypto, time is the one thing most projects don't get. The window between "interesting infrastructure play" and "forgotten chain" is shorter than people admit. OpenLedger would need AI adoption to move fast enough, and mainstream enough, that the dependency layer has time to actually calcify before attention moves somewhere else.
I'm not convinced that timeline works cleanly. The AI data space is crowded, the enterprise sales cycle for anything touching model training is slow, and "verifiable data provenance" — while genuinely important — isn't the kind of value prop that creates explosive early traction. It's the kind of thing that matters quietly, in the background, until one day it matters a lot.
So I'm sitting with this tension. The design logic is sound. Maybe more sound than most things I've looked at recently. But sound design and good timing are two different things, and I've seen well-designed things lose simply because they arrived in the wrong market window.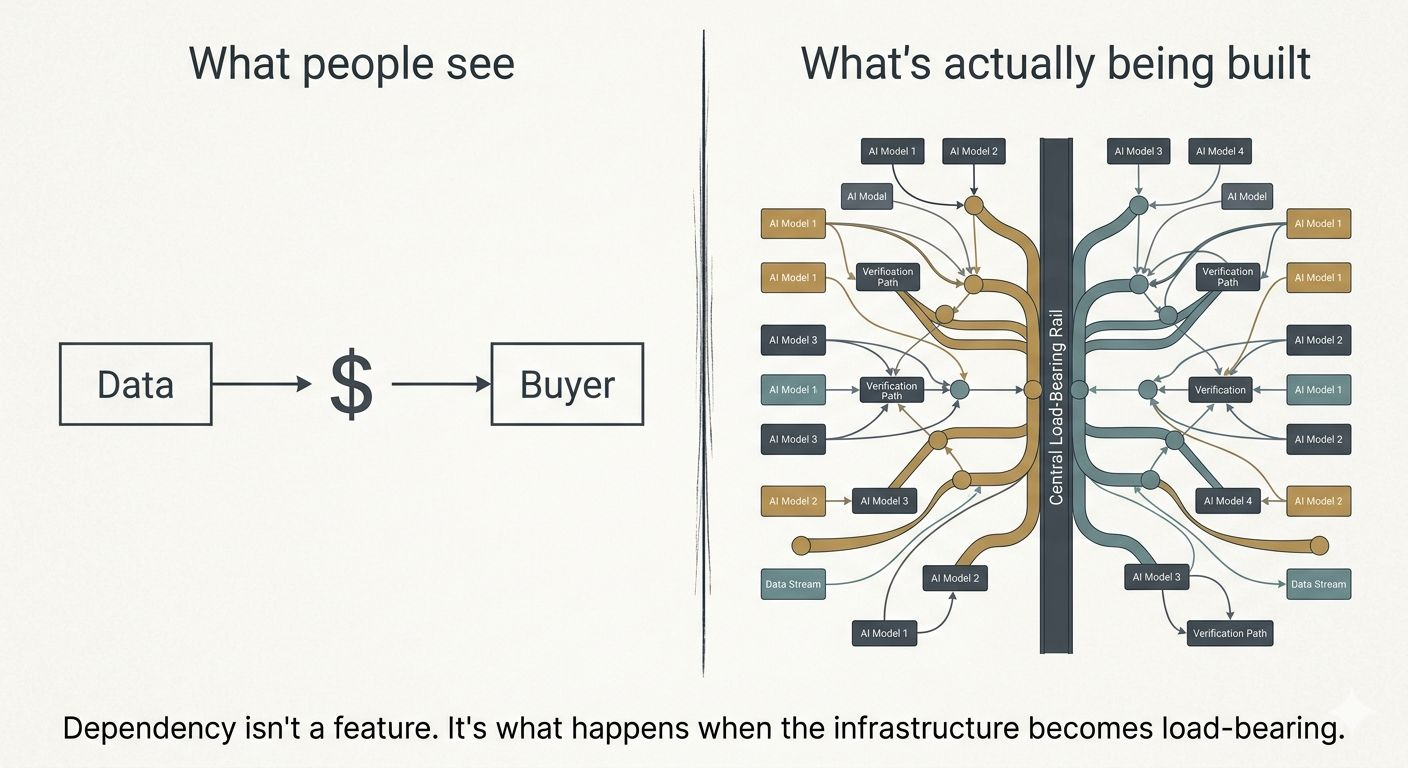
I'll probably keep watching how the developer adoption side progresses. That's the leading indicator here — not token price, not TVL. If the tooling starts showing up in actual AI pipelines, the thesis starts feeling more real. If it stays at the infrastructure announcement stage for another year, that's a different story.
Anyway. Charts are still doing nothing. Maybe that's fine.