Late night again, coffee gone cold, staring at another compliance deck. This one’s for a mid-sized fund that’s been experimenting with feeding internal trade data into custom risk models. The question that keeps looping in my head isn’t some grand theory about blockchain or AI. It’s simpler, and more annoying: how the hell do you let enough of that data move around so the models actually improve and regulators sign off, without handing over the keys to the entire operation?
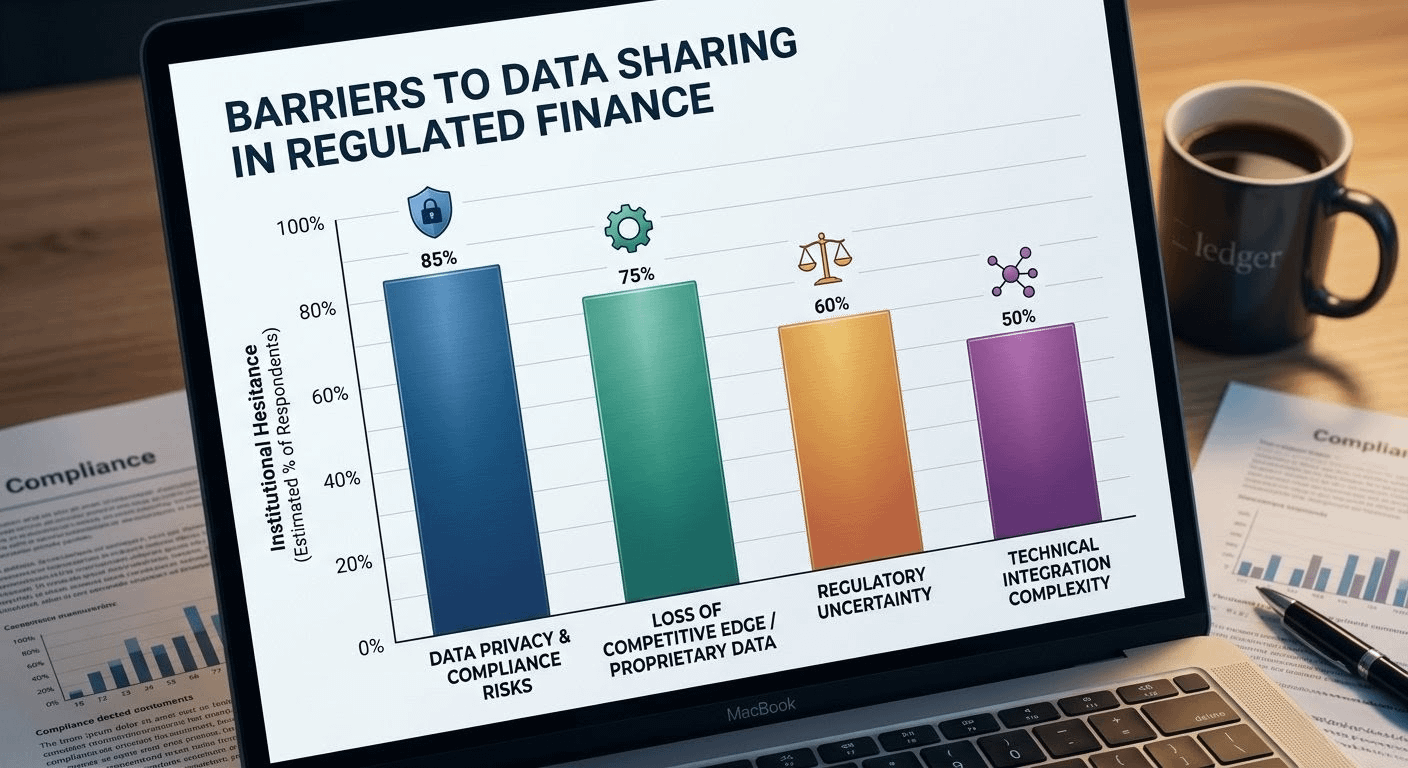
You see it play out in real rooms. A portfolio manager has client behavior signals that could sharpen alpha or flag compliance risks early. Share too freely and you’re staring at data breach headlines, GDPR fines, or worse—competitors quietly copying your edge. Lock it down completely and you’re stuck with mediocre models, duplicated effort across the industry, and missed chances to collaborate on things like fraud patterns that hurt everyone. The friction isn’t theoretical. It’s in the emails, the delayed settlements, the third-party data rooms that charge premium rents for “secure” access nobody fully trusts. I’ve watched institutions pay for these bandaids year after year, only for someone inside to route around them when the process gets too slow. Human nature doesn’t change just because the spreadsheet says “compliant.”
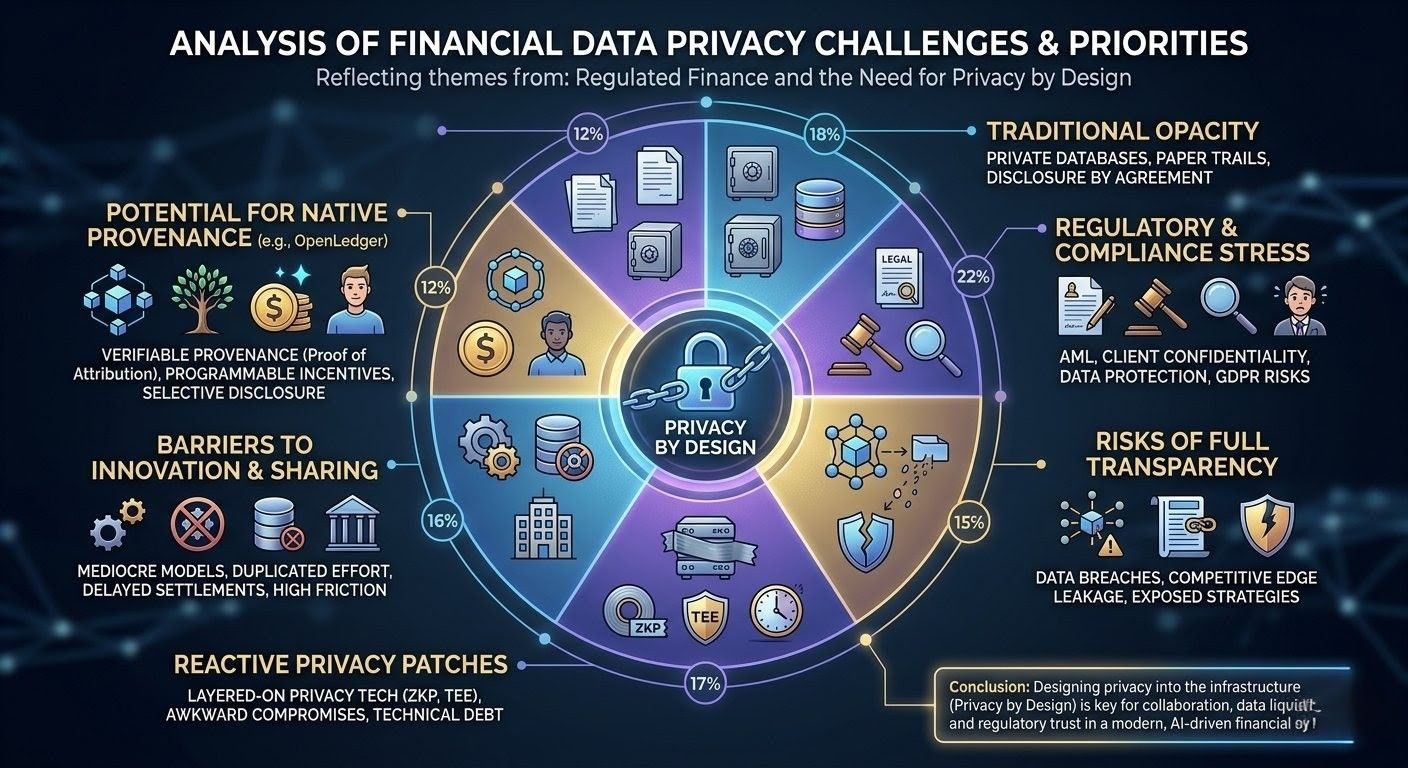
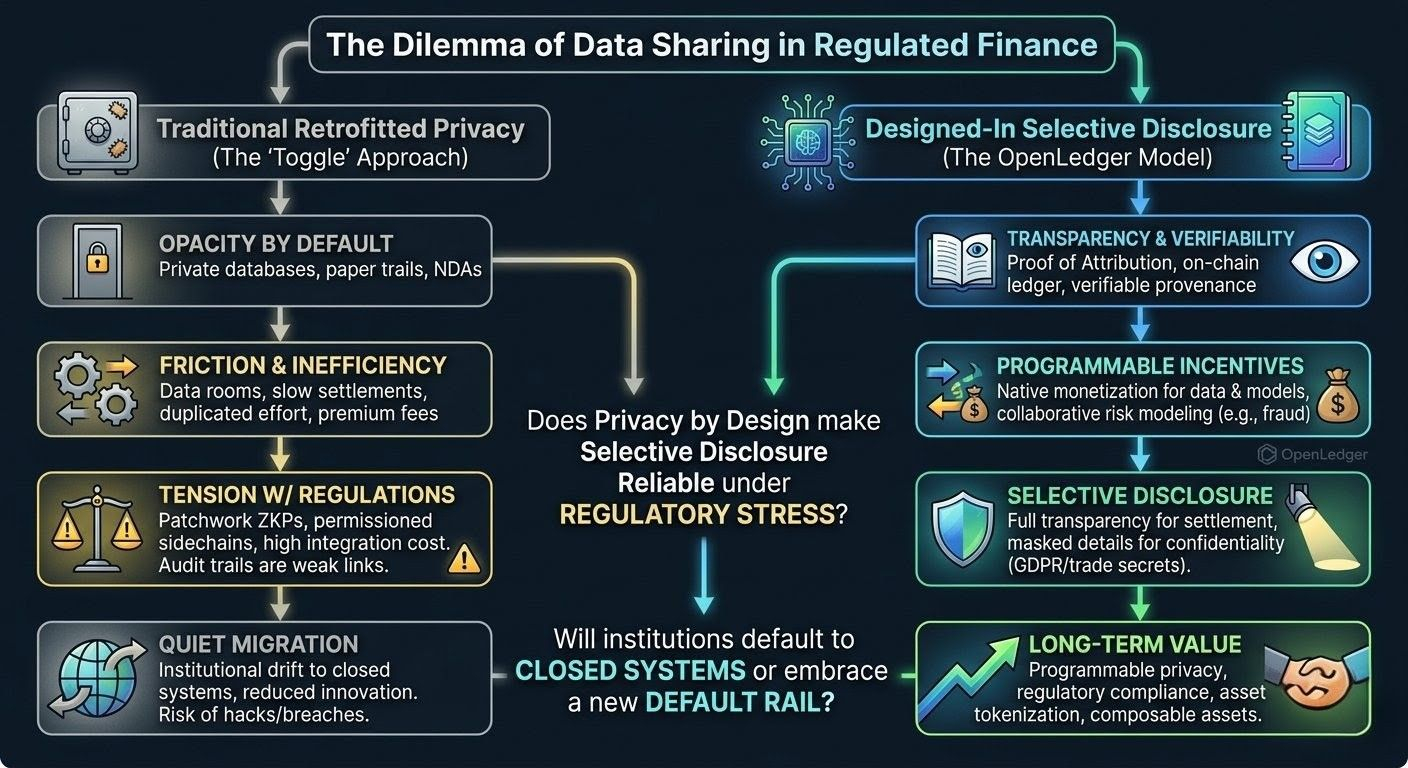
Most attempts at fixing this feel patched together, honestly. Traditional finance grew up with private databases and paper trails—opacity by default, disclosure by agreement. Public blockchains flipped that script hard: everything visible, everything verifiable, which is perfect for some transparent DeFi plays but disastrous when you’re dealing with personal data, proprietary strategies, or regulatory obligations that demand you prove control without broadcasting it. So the industry layers on privacy tech as an afterthought—zero-knowledge proofs here, permissioned sidechains there, trusted execution environments that still rely on someone not messing up the keys. It works on paper until a bug surfaces or a regulator asks for the full audit trail and you realize the exception you built is now the weakest link. Builders complain about integration headaches and ballooning costs. Compliance officers lose sleep because proving “we designed it this way on purpose” is harder when privacy was never baked in from the start.
Regulators sit in the middle of this mess for good reason. Rules around AML, client confidentiality, and data protection didn’t come from nowhere—they’re reactions to real harms when things stay too hidden or leak too easily. But applying them to digital systems built for radical openness creates this constant tension. You end up with awkward compromises: full transparency for settlement finality, selective blindness for sensitive bits. The result? Higher overhead, slower innovation, and a quiet migration of activity back to familiar, closed systems or offshore workarounds. I’ve seen it enough times to be wary. Systems that treat privacy as a toggle or a post-launch feature tend to accumulate technical debt and legal gray areas until something breaks under pressure—whether that’s a market event, a hack, or a policy shift.
That’s the backdrop where a project like OpenLedger starts looking interesting, though I’m not rushing to any conclusions. It’s framed as infrastructure purpose-built for AI workloads on a ledger—tracking contributions of data, models, and agents with something they call Proof of Attribution. The point seems to be creating verifiable provenance and programmable incentives so that pieces of the AI stack can gain liquidity and be monetized without defaulting to full public exposure. Not hype about revolutionizing everything, but potentially smoothing some of the real plumbing: allowing institutions to contribute to shared datasets for compliance AI or risk modeling, with attribution that shows who added what and how it was used, while keeping raw sensitive inputs protected.
In practice, think about a bank fine-tuning fraud detection models across anonymized transaction patterns from multiple players. Today, that’s bogged down by NDAs, clean rooms, and disputes over value. If attribution is native and rewards flow based on actual impact, it might nudge behavior toward more sharing without the usual free-rider problems. Settlement of AI-influenced trades or agent-executed deals could carry embedded trails that auditors can query selectively—enough for accountability, not so much that confidentiality evaporates. Costs could matter here too: if on-chain verification reduces the need for endless off-chain reconciliations, it might pay for itself. But only if the integration doesn’t add new layers of complexity that smaller players or even big ones balk at.
I remain skeptical because I’ve watched similar promises fade. Early privacy chains and “enterprise blockchain” experiments often delivered demos that didn’t survive contact with real regulatory scrutiny or daily operational friction. Will supervisors accept on-chain attribution as robust enough for liability and audit standards, or will they still insist on their own off-chain controls? Technical privacy is advancing, but legal settlement and human trust lag. Plus, AI introduces fresh risks—model poisoning, biased datasets, explainability demands—that provenance helps with but doesn’t magically solve. If the system still feels like retrofitting privacy rather than designing around selective disclosure from the ground up, it’ll stay niche.
**The grounded part:** Who actually reaches for this? Probably institutions and fintechs already knee-deep in tokenized assets or internal AI pilots—compliance teams exhausted by fragmented data silos, asset managers hunting sustainable edges from collaborative models, data owners tired of uncompensated contributions. It might gain traction if it quietly lowers long-term compliance drag, turns static datasets or specialized agents into composable, rewarded assets, and offers enough verifiable transparency for regulators without killing commercial discretion. Regulators themselves could see value in better provenance reducing blind spots in systemic risk.
It fails if it chases retail volume over institutional boring stuff, if privacy mechanisms crack under real stress tests, or if the economics and integration overhead make sticking with legacy vendors simpler. Execution in the messy details—how it handles actual law, settlement finality, everyday user behavior—will decide it, not the whitepaper vision. I’ve seen too many infrastructure plays end up as interesting experiments rather than default rails. Privacy by design in regulated finance feels less like a feature and more like table stakes for any system that wants serious money flowing through it over time. OpenLedger seems tuned for that angle. Whether it lands depends on delivering in the places where systems usually quietly fail.
Here’s the question that keeps nagging at me, the one that feels most central to whether any of this actually moves the needle: If privacy is truly designed into the system from the ground up, does that make selective disclosure reliable enough under real regulatory stress, or will institutions still default to familiar closed systems when the stakes involve client money and personal liability?